






一.先来先服务调度算法
1.主要内容
按作业提交的/到达的(到达后备队列的时间)先后次序从外存后备队列中选择几个最先进入该队列的作业为他们分配资源、创建进程,然后再放入就绪队列。 每个作业由一个作业控制块JCB表示,JCB可以包含如下信息:作业名、提交时间、所需的运行时间、作业状态等等。 作业的状态可以是等待W(Wait)、运行R(Run)和完成F(Finish)三种状态之一。每个作业的最初状态总是等待W。 各个等待的作业按照提交时刻的先后次序排队。 每个作业完成后要输出该作业的开始运行时刻、完成时刻、周转时间和带权周转时间,这一组作业完成后计算并输出这组作业的平均周转时间、平均带权周转时间。
2.算法原理
当使用先来先服务法用于作业调度时,系统将按照作业到达的先后顺序来进行调 度,或者说它是优先考虑在系统中等待时间最长的作业,而不管该作业所需执行 时间的长短,从后备作业队列中选择几个最先进入该队列的作业,将他们调入内 存,为他们分配资源和创建进程,然后将它们放入就绪队列。
3.算法实现
#include <stdio.h>
#include <string>
#define MAX_JOBS 20
typedef struct {
char name[10]; // 作业名
float arrival_time; // 提交时间
float run_time; // 所需的运行时间
float start_time; // 开始运行时刻
float finish_time; // 完成时刻
char status; // 作业状态:W(Wait)、R(Run)、F(Finish)
float turnaround_time; // 周转时间
float weighted_turnaround_time; // 带权周转时间
} JobControlBlock;
void initializeJobs(JobControlBlock jobs[], int n) {
for (int i = 0; i < n; i++) {
scanf("%s %f %f", jobs[i].name, &jobs[i].arrival_time, &jobs[i].run_time);
jobs[i].status = 'W'; // 初始状态为等待
jobs[i].turnaround_time = 0; // 初始化周转时间和带权周转时间为0
}
}
void scheduleJobs(JobControlBlock jobs[], int n) {
// 初始化当前时间为0,表示作业调度开始的时刻
float current_time = 0.0;
// 初始化完成作业数为0,用于跟踪已完成作业的数量
int finished_jobs = 0;
// 初始化总周转时间和总带权周转时间为0,用于计算平均值
float total_turnaround_time = 0, total_weighted_turnaround_time = 0;
// 打印表头,用于输出作业调度的详细信息
printf("作业名 提交时间 运行时间 开始运行时刻 完成时刻 周转时间 带权周转时间\n");
// 主循环,持续直到所有作业完成
while (finished_jobs < n) {
int next_job_index = -1; // 初始化下一个作业的索引为-1,表示尚未找到下一个作业
// 遍历作业列表,寻找下一个要执行的作业
for (int i = 0; i < n; i++) {
// 如果作业已到达且尚未完成(状态为'W'),则考虑此作业
if (jobs[i].arrival_time <= current_time && jobs[i].status == 'W') {
// 如果未找到作业或当前作业的到达时间早于已选作业,则选择当前作业
if (next_job_index == -1 || jobs[i].arrival_time < jobs[next_job_index].arrival_time) {
next_job_index = i;
}
}
}
// 如果找到了下一个作业
if (next_job_index != -1) {
// 更新作业状态为运行中('R')
jobs[next_job_index].status = 'R';
// 设置作业的开始时间为当前时间
jobs[next_job_index].start_time = current_time;
// 更新当前时间,加上作业的运行时间
current_time += jobs[next_job_index].run_time;
// 设置作业的完成时间为当前时间
jobs[next_job_index].finish_time = current_time;
// 更新作业状态为完成('F')
jobs[next_job_index].status = 'F';
// 计算并更新作业的周转时间和带权周转时间
jobs[next_job_index].turnaround_time = jobs[next_job_index].finish_time - jobs[next_job_index].arrival_time;
jobs[next_job_index].weighted_turnaround_time = jobs[next_job_index].turnaround_time / jobs[next_job_index].run_time;
// 累加到总周转时间和总带权周转时间
total_turnaround_time += jobs[next_job_index].turnaround_time;
total_weighted_turnaround_time += jobs[next_job_index].weighted_turnaround_time;
// 打印作业的调度信息
printf(" %s\t\t%.0f\t\t%.0f\t\t%.0f\t\t%.0f\t\t%.0f\t\t%.2f\n",
jobs[next_job_index].name, jobs[next_job_index].arrival_time, jobs[next_job_index].run_time, jobs[next_job_index].start_time, jobs[next_job_index].finish_time,
jobs[next_job_index].turnaround_time, jobs[next_job_index].weighted_turnaround_time);
// 增加完成作业计数
finished_jobs++;
} else {
// 如果当前没有作业可以运行,时间前进到下一个作业的到达时间
current_time++;
}
}
// 打印平均周转时间和平均带权周转时间
printf("\n平均周转时间: %.2f\n", total_turnaround_time / n);
printf("平均带权周转时间: %.2f\n", total_weighted_turnaround_time / n);
}
int main() {
JobControlBlock jobs[MAX_JOBS];
int n;
printf("先来先服务算法\n\n");
printf("请输入作业个数:");
scanf("%d", &n);
printf("请输入各个作业的作业名, 提交时刻, 所需的运行时间:\n");
initializeJobs(jobs, n);
scheduleJobs(jobs, n);
return 0;
}4.运行结果

5.结果分析
从键盘输入作业数量为 5,其中各个作业的作业名、提交时刻和服务时间如下: A 0 4 B 1 3 C 2 5 D 3 2 E 4 4 按 A、B、C、D、E 顺序即为它们进入后备队列的顺序,执行顺序就是作业进入队 列的先后时间顺序,先进去的先执行,即作业 A 最先执行,其次依次是 B、C、D、 E,下一个作业开始运行的时间就是前一个作业的完成时刻。根据周转时间=完成 时间-到达时间;带权周转时间=周转时间/服务时间,即可算得每个进程的周转 时间和带权周转时间,而平均周转时间和平均带权周转时间只需计算所有进程的 周转时间和和带权周转时间和,再加以求平均即可求得。因此分析结果与上述运 行结果一致。
二.短作业优先调度算法
1.主要内容
根据作业的估计运行时间的长短,从外存后备队列中选择若干个作业为他们分配资源、创建进程,然后再放入就绪队列。 每个作业由一个作业控制块JCB表示,JCB可以包含如下信息:作业名、提交时间、所需的运行时间、作业状态等等。 作业的状态可以是等待W(Wait)、运行R(Run)和完成F(Finish)三种状态之一。每个作业的最初状态总是等待W。 各个等待的作业按照提交时刻的先后次序排队。 每个作业完成后要输出该作业的开始运行时刻、完成时刻、周转时间和带权周转时间,这一组作业完成后计算并输出这组作业的平均周转时间、平均带权周转时间。
2.算法原理
短作业优先算法是以作业的长短来计算优先级,作业越短,其优先级越高。作业 的长短是以作业要求的运行时间来衡量的。在把短作业优先调度算法用于作业调 度时,它将从外存的作业后备队列中选择若干个估计运行时间最短的作业,优先 将它们调入内存运行。 完成时间=开始时间+需要运行时间 周转时间=完成时间-到达时间 带权周转时间=周转时间/需要运行时间
3.算法实现
#include <iostream>
#include <string>
#include <iomanip>
struct job
{
char name[10]; //作业的名字
int starttime; //作业到达系统时间
int needtime; //作业服务时间
int runtime; //作业周转时间
int endtime; //作业结束时间
int flag=0; //作业完成标志
char state='W'; //作业状态,一开始都默认为就绪
double dqzz_time; //带权周转时间
};
void sjf(struct job jobs[50],int n){
int i=0,j=0,k,temp,count=0,min_needtime,min_starttime,t_time,flag1;
char t_name[10];
int nowtime=0;
for(i=0;i<n;i++) //按作业所需运行时间排序,短的排在最前面
{
min_needtime=jobs[i].needtime;//n轮循环,每次都把job[j]与job[i]的所需运行时间相比较,从而找到位于job[i]后的最短的运行时间
temp=i;
for(j=i;j<n;j++)
{
if(jobs[j].needtime<min_needtime)
{
temp=j;
min_needtime=jobs[j].needtime;
}
}
if(temp!=i)//存在更短的运行时间
{
jobs[40]=jobs[temp];//中间变量
for(k=temp-1;k>=i;k--)//将位于jobs[temp]前的jobs向左平移
{
jobs[k+1]=jobs[k];
}
jobs[i]=jobs[40];
}
}
while(count<n){//作业未全部运行完
temp=1000;
flag1=0;
min_needtime=1000;
min_starttime=1000;
for(i=0;i<n;i++){
if(jobs[i].flag==0){
if(jobs[i].starttime<=nowtime)//存在未完成且等待的作业
{
flag1=1;
if(jobs[i].needtime<min_needtime){//找出所需运行时间最短的作业
min_needtime=jobs[i].needtime;
temp=i;
}
}
}
}
if(flag1==0)//如果所有未完成的作业都没等待
{
for(i=0;i<n;i++){
if(jobs[i].flag==0){
if(jobs[i].starttime<min_starttime){//找出最先到达的作业
min_starttime=jobs[i].starttime;
temp=i;
}
}
}
nowtime=jobs[temp].starttime+jobs[temp].needtime;//系统时间从作业到达时间开始
jobs[temp].state='r';
jobs[temp].endtime=nowtime;
jobs[temp].flag=1;
jobs[temp].runtime=jobs[temp].endtime-jobs[temp].starttime;
jobs[temp].dqzz_time=float(jobs[temp].runtime)/jobs[temp].needtime;
jobs[temp].state='f';
count++;
}
else{//有等待的作业
nowtime+=jobs[temp].needtime;//从系统时间开始运行
jobs[temp].state='r';
jobs[temp].endtime=nowtime;
jobs[temp].flag=1;
jobs[temp].runtime=jobs[temp].endtime-jobs[temp].starttime;
jobs[temp].dqzz_time=float(jobs[temp].runtime)/jobs[temp].needtime;
jobs[temp].state='f';
count++;
}
}
}
void print(struct job jobs[50],int n)
{
int i,j;
double avertime;
double dqzz_avertime;
int sum_runtime=0;
double sum_time=0.00;
for(i=0;i<n;i++) //按作业完成时间进行排序,完成早的排在最前面
{
for(j=i;j<n;j++)
{
if(jobs[j].endtime<jobs[i].endtime)
{
jobs[45]=jobs[j];
jobs[j]=jobs[i];
jobs[i]=jobs[45];
}
}
}
printf("作业名 到达时间 运行时间 完成时间 周转时间 带权周转时间\n");
for(i=0;i<n;i++)
{
printf("%s %2d %2d %2d %2d %.2f\n",jobs[i].name,jobs[i].starttime,jobs[i].needtime,jobs[i].endtime,jobs[i].runtime,jobs[i].dqzz_time);
sum_runtime=sum_runtime+jobs[i].runtime;
sum_time=sum_time+jobs[i].dqzz_time;
}
avertime=sum_runtime*1.0/n;
dqzz_avertime=sum_time*1.000/n;
printf("平均周转时间:%.2f \n",avertime);
printf("平均带权周转时间:%.2f \n",dqzz_avertime);
printf("\n");
}
int main()
{
struct job jobs[50];
int n,i; //n个作业
printf("短作业优先算法\n\n") ;
printf("请输入作业个数:");
scanf("%d",&n);
printf("请输入各个作业名、提交时刻和服务时间:\n");
for(i=0;i<n;i++)
{
scanf("%s",jobs[i].name); //作业名
scanf("%d",&jobs[i].starttime);//到达时间
scanf("%d",&jobs[i].needtime);//运行(服务时间)时间
}
printf("\n");
sjf(jobs,n);
printf("短作业优先调度算法运行结果:\n");
print(jobs,n);
}
4.运行结果
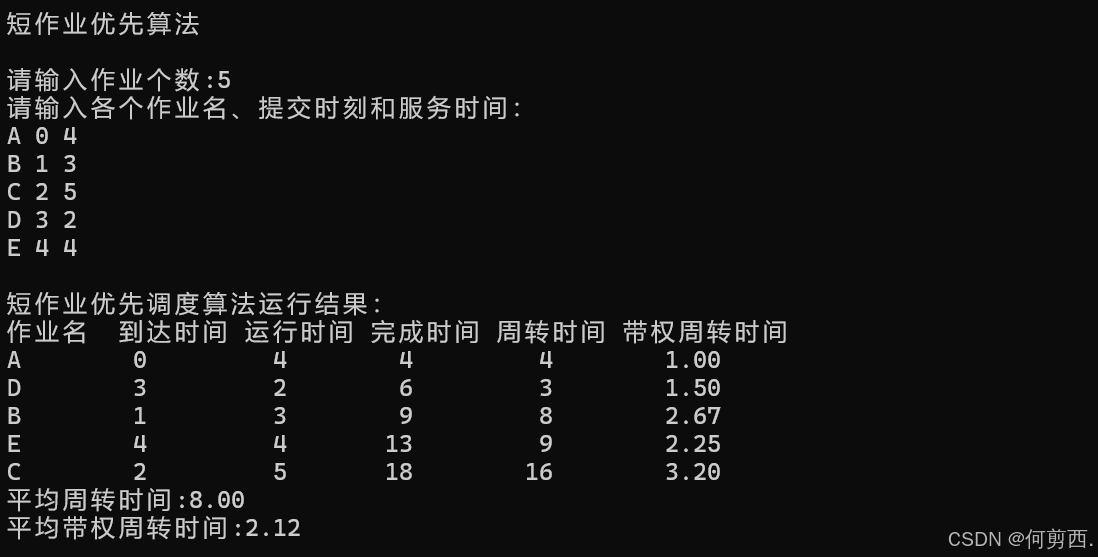
5.结果分析
从键盘输入作业数量为 5,其中各个作业的作业名、提交时刻和服务时间如下: A 0 4 B 1 3 C 2 5 D 3 2 E 4 4 其中作业 A 最先到达,因此最先执行作业 A,作业 A 在 4 时刻执行完毕,在 4 时 刻及以前,作业 B、C、D、E 均已到达,故下一个要执行的作业就是在这已到达 的四个作业中执行服务时间最短的作业即作业 D,接下来的步骤也是一样的,作 业服务顺序为 A、D、B、E、C,下一个作业开始运行的时间就是前一个作业的完 成时刻。根据周转时间=完成时间-到达时间;根据周转时间=完成时间-到达时间; 带权周转时间=周转时间/服务时间,即可算得每个进程的周转时间和带权周转时 间,而平均周转时间和平均带权周转时间只需计算所有进程的周转时间和和带权 周转时间和,再加以求平均即可求得。因此分析结果与上述运行结果一致。
三.总结
1.FCFS 算法是一种非抢占式调度算法,它按照作业到达的顺序进行调度。最先 到达的作业将最先被服务。FCFS 算法简单且公平,每个作业都按照它们到达的 顺序被处理。实现 FCFS 算法相对简单,通常只需要一个队列来存储待处理的作 业。FCFS 算法可能导致长作业(长时间运行的作业)延迟,从而影响系统的整 体效率。如果长作业连续到达,短作业可能会遭受饥饿。
2.SJF 算法是一种非抢占式调度算法,它选择服务时间(执行时间)最短的作业 优先执行。SJF 算法在减少平均周转时间和带权周转时间方面表现更好,因为它 倾向于先处理短作业。实现 SJF 算法需要对作业按照服务时间进行排序,这可能 涉及到更复杂的数据结构和排序算法但 SJF 算法可能导致长作业饥饿,尤其是当 短作业连续到达时,长作业可能长时间得不到服务。
3.两者共同点是都是非抢占式调度算法,一旦作业开始执行,就不会被打断,直 到完成。都适用于批处理系统或某些实时系统。都可以导致饥饿问题,特别是当 长作业或短作业连续到达时

















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









