







基础相关
DBMS
概念相关
| 名称 | 概念 | 特点 |
|---|---|---|
| 数据 | 描述事物的符号记录, 可以是数字、 文字、图形、图像、声音、语言等,数据有多种形式,它们都可以经过数字化后存入计算机。 | 无 |
| 数据库 | 存储数据的仓库,是长期存放在计算机内、有组织、可共享的大量数据的集合。数据库中的数据按照一定数据模型组织、描述和存储,具有较小的冗余度,较高的独立性和易扩展性,并为各种用户共享 | 1. 数据结构化 数据的共享性高,冗余度低,易扩充 ;2. 数据独立性高;3.数据由 DBMS 统一管理和控制(安全性、完整性、并发控制、故障恢复) |
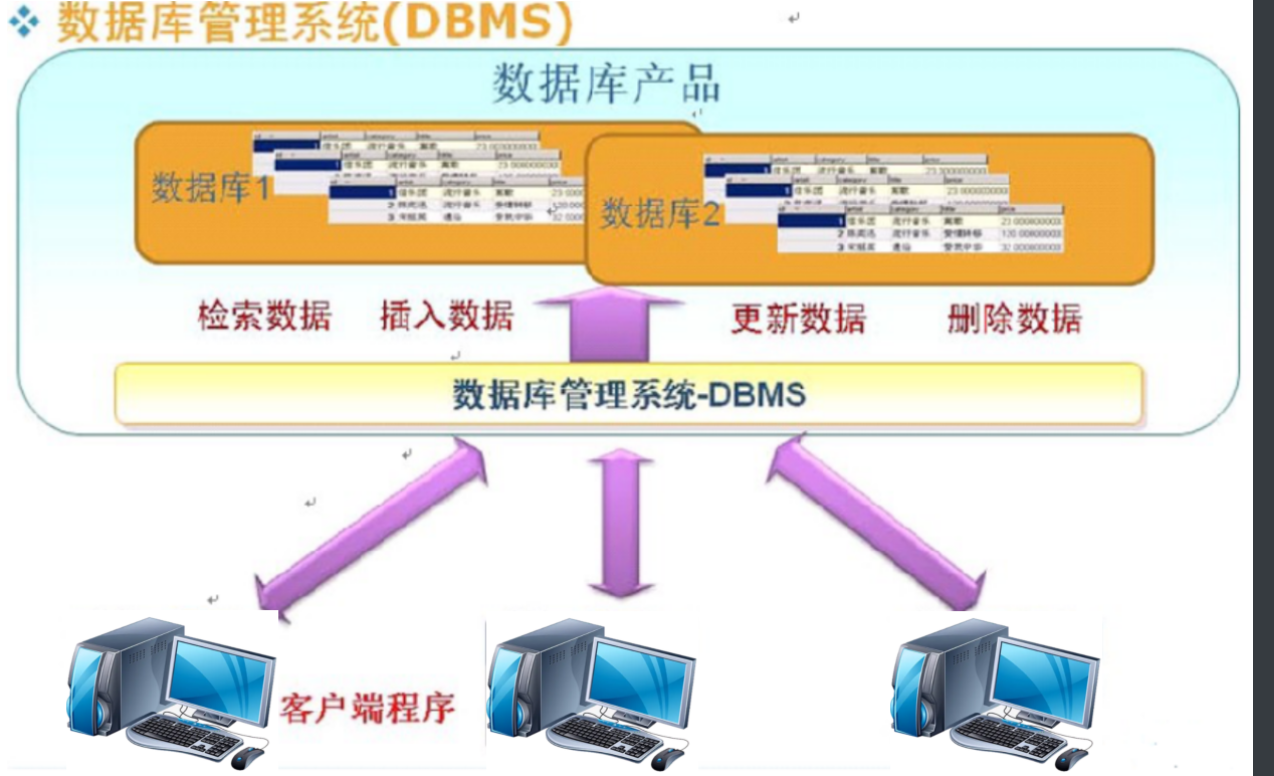
| 数据库管理系统(DBMS) | 数据库管理系统(DataBase ManagermentSystem,简称DBMS)是管理数据库的一个软件,它充当所有数据的知识库,并对它的存储、安全、一致性、并发操作、恢复和访问负责。是对数据库的一种完整和统一的管理和控制机制。 | DBMS是所有数据的知识库,并对数据的存储、安全、一致性、并发操作、恢复和访问负责。 |
系统相关
| 名称 | 概念 |
|---|---|
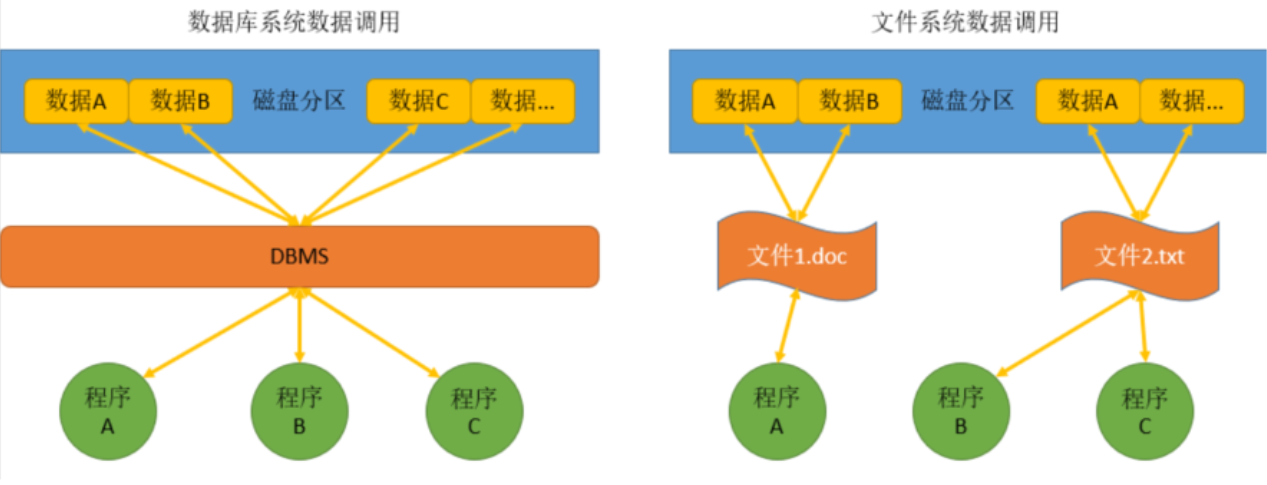
| 文件系统 | 文件系统是操作系统用于明确存储设备(常见的是磁盘)或分区上的文件的方法和数据结构;即在存储设备上组织文件的方法。操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。 |
| 数据库系统 | 数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称 DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。 |
| 区别 | 内容 |
|---|---|
| 管理对象不同 | 文件系统的管理对象是文件,并非直接对数据进行管理,不同的数据结构需要使用不同的文件类型进行保存(举例: txt 文件和 doc 文件不能通过修改文件名完成转换) ;而数据库直接对数据进行存储和管理 |
| 存储方式不同 | 文件系统使用不同的文件将数据分类(.doc/.mp4/.jpg) 保存在外部存储上;数据库系统使用标准统一的数据类型进行数据保存(字母、 数字、符号、时间) |
| 调用数据的方式不同 | 文件系统使用不同的软件打开不同类型的文件;数据库系统由 DBMS 统一调用和管理。 |
特点
- 由于 DBMS 的存在,用户不再需要了解数据存储和其他实现的细节,直接通过 DBMS 就能获取数据,为数据的使用带来极大便利。
- 具有以数据为单位的共享性,具有数据的并发访问能力。 DBMS 保证了在并发访问时数据的一致性。
- 低延时访问,典型例子就是线下支付系统的应用,支付规模巨大的时候,数据库系统的表现远远优于文件系统。
- 能够较为频繁的对数据进行修改,在需要频繁修改数据的场景下,数据库系统可以依赖 DBMS 来对数据进行操作且对性能的消耗相比文件系统比较小。
- 对事务的支持。 DBMS 支持事务,即一系列对数据的操作集合要么都完成, 要么都不完成。在DBMS上对数据的各种操作都是原子级的。
事务的特性
即ACID规则:原子性、一致性、隔离性、持久性
| 特点 | 内容 |
|---|---|
| 原子性 | 事务里 的 所有操作要么全部做完,要么都不做 。( 一个事务要么完全提交要么完全回滚 , 不会介于二者之间 ) |
| 一致性 | 数据库要一直处于 一致的状态 , 事务的运行 不会改变 数据库原本 的 一致性约束 。( 发起一个查询后 不管数据发生 多少变化 , 查询结果 应当为 发起查询 时间一致的数据) |
| 隔离性 | 是指 并发的事务 之间不会 互相影响 。( 提交不同事务时 显示的效果是 串行 的。换句话说,不同事务按照提交的先后顺序执行 )是指 并发的事务 之间不会 互相影响 。( 提交不同事务时 显示的效果是 串行 的。换句话说,不同事务按照提交的先后顺序执行 ) |
| 持久性 | 一旦事务提交后 ,它所做的 修改 将会 永久 的保存在 数据库上 |
不同人员对数据库要求
| 对象 | 要求 |
|---|---|
| 程序员 | 基本的SQL操作、CRUD操作、多表连接查询、分组查询和子查询。、常用数据库的的单行函数、常用数据库的基本命令、常用数据库的开发工具、事务概念。 索引、视图、存储过程和触发器。 |
| 运维人员 | 部署环境、数据库安装、参数配置、权限分配、数据库备份/还原、监控、故障处理、性能优化、容灾、升级/迁移、系统用户反馈的数据库问题 |
数据库运维工作总原则:
- 能不给数据库做的事情不要给数据库,数据库只做数据容器。
- 对于数据库的变更必须有记录,可以回滚。
Mysql
- 概念:MySQL是一个小型关系数据库管理系统
- 特点:体积小、速度快
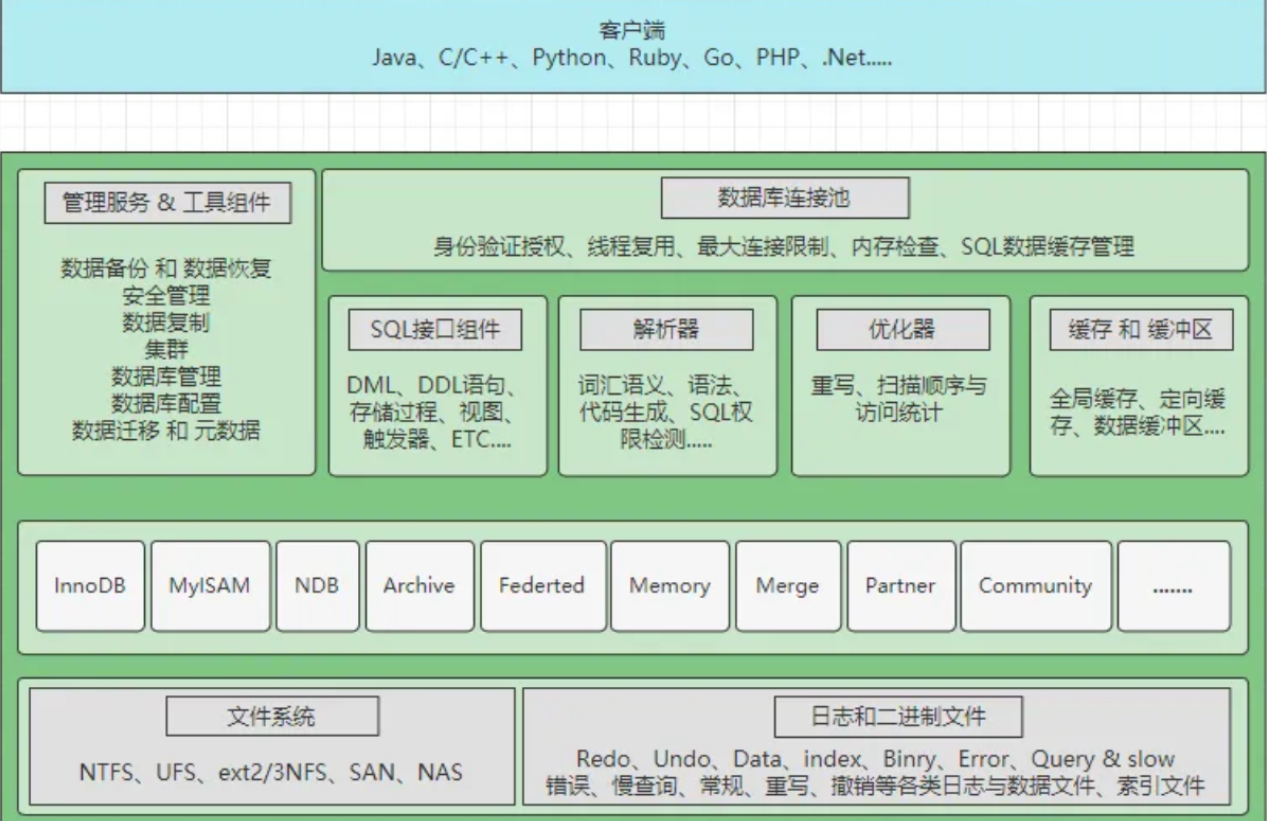
- 组成:网络连接层、数据库服务层、存储引擎层、系统文件层
| 结构 | 作用 |
|---|---|
| 网络连接层 | 负责与外部进行网络通信和数据交互。 |
| 数据库服务层 | 处理数据库相关操作和事务管理等。 |
| 存储引擎层 | 实现数据的存储、检索和管理具体机制。 |
| 系统文件层 | 与底层操作系统的文件系统交互,进行数据的实际存储和读取。 |
Mysql字符集
- 包括字符集和校对规则两个概念
- 字符集:是一套编码
- 校对规则:是在字符集内用于比较字符的一套规则
| 字符集 | 内容 |
|---|---|
| mysql | 字符集: |
| latin1 | 支持西欧字符、希腊字符等 |
| gbk | 支持中文简体字符 |
| big5 | 支持中文繁体字符 |
| utf8 | 几乎支持世界所有国家的字符。 |
| utf8mb4 | 是真正意义上的 utf - 8 |
Mysql数据类型
- 在Mysql中,有三种主要的类型:文本,数值,日期/时间类型
| 文本类型 | 作用 |
|---|---|
| char(size) | 保存固定长度的字符串(可包含字母、数字以及特殊字符)在括号中指定字符串的长度。最多 255 个字符。 |
| varchar(size) | 保存可变长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的最大长度。最多 255 个字符。 注释:如果长度大于 255,则被转换为 text 类型。 |
| tinytext | 存放最大长度为 255 个字符的字符串。 |
| text | 存放最大长度为 65535 个字符的字符串。 |
| blob | 用于 BLOBs (Binary Large Objects),二进制形式的长文本数据。存放最多 65535 字节的数据。 |
| mediumtext | 存放最大长度为 16,777,215 个字符的字符串。 |
| mediumblob | 用于 BLOBs (Binary Large Objects),二进制形式的中等长度文本数据。存放最多 16,777,215 字节的数据。 |
| longtext | 存放最大长度为 4,294,967,295 个字符的字符串。 |
| longblob | 用于 BLOBs (Binary Large Objects),二进制形式的极大文本数据。存放最多 4,294,967,295 字节的数据。 |
| enum(x,y,z,etc) | 允许你输入可能值的列表。可以在 ENUM 列表中列出最大 65535 个值。如果列表中不存在输入的值,则插入空值。 注释:这些值是按照你输入的顺序存储的。可以按照此格式输入可能的值:enum (‘X’,‘Y’,‘Z’) |
| set | 与 enum 类似,set 只能包含 64 个列表项,不过 set 可存储一个以上的值。 |
| 数值类型 | 用途 | 存储需求 | 范围(有符号) | 范围(无符号) |
|---|---|---|---|---|
| tinyint | 小整数值 | 1Bytes | (-128,127) | (0,255) |
| smallint | 大整数值 | 2Bytes | (-32768,32767) | (0,65535) |
| mediumint | 大整数值 | 3Bytes | (-8388608,8388607) | (0,16777215) |
| int或integer | 大整数值 | 4Bytes | (-2147483648,2147483647) | (0,4294967295) |
| bigint | 大整数值 | 8Bytes | (-9223372036854775808,9223372036854775807) | (0,18446744073709551615) |
| float(单精度,size,d) | 带有浮动小数点的小数字。在括号中规定最大位数。在4 Bytes参数中规定小数点右侧的最大位数 | 4Bytes | (-3.402823466E+38, -1.175494351E-38, 0, 1.175494351E-38, 3.402823466E+38) | (0, 3.402823466E+38) |
| double(双精度,size,d) | 带有浮动小数点的大数字。在括号中规定最大位数。在8 Bytes参数中规定小数点右侧的最大位数 | 8Bytes | (-1.7976931348623157E+308, -2.2250738585072014E-308, 0, 2.2250738585072014E-308, 1.7976931348623157E+308) | (0, 1.7976931348623157E+308) |
| decimal(固定点,size,d) | 作为字符串存储的DOUBLE类型,允许固定的小数点 | (size+2)Bytes |
注:
- 这些数值拥有额外的选项unsigned
- 通常,证书可以是负数或整数,如果添加unsigned属性,那么范围将0开始,而不是某个负数。
| 时间类型 | 存储需求 | 描述 |
|---|---|---|
| date | 3Bytes | 日期。格式:YYYY - MM - DD 注释:支持的范围是从’1000 - 01 - 01’到’9999 - 12 - 31’ |
| datetime | 8Bytes | 日期和时间的组合。格式:YYYY - MM - DD HH:MM:SS 注释:支持的范围是’1000 - 01 - 01 00:00:00’到’9999 - 12 - 31 23:59:59’ |
| timestamp | 4Bytes | 时间戳。timestamp值使用Unix纪元(1970 - 01 - 01 00:00:00 UTC)至今的描述来存储。格式:YYYY - MM - DD HH:MM:SS 注释:支持的范围是从’1970 - 01 - 01 00:00:00’ UTC到’2038 - 01 - 19 03:14:07’ UTC |
| time | 3Bytes | 时间。格式:HH:MM:SS 注释:支持的范围是从’-838:59:59’到’838:59:59’ |
| year | 1Bytes | 2位或4位格式的年。注释:4位格式所允许的值:1901到2155。2位格式所允许的值:70到69,表示从1970到2069 |
SQL语法
简介
SQL:结构化查询语言(Structured Query Language),在关系型数据库上执行数据操作、数据检索以及数据维护的标准语言。使用SQL语句,程序员和数据库管理员可以完成如下的任务
- 改变数据库的结构
- 更改系统的安全设置
- 增加用户对数据库或表的许可权限
- 在数据库中检索需要的信息
- 对数据库的信息进行更新
分类
| SQL语句分类 | 定义 | 示例 |
|---|---|---|
| DDL(Data Definition Language) | 数据定义语言,定义对数据库对象(库、表、列、索引)的操作 | CREATE、DROP、ALTER、RENAME、 TRUNCATE等 |
| DML(Data Manipulation Lanuage) | 数据操作语言,定义对数据库记录的操作 | INSERT、DELETE、UPDATE、SELECT等 |
| DCL(Data Control Language) | 数据控制语言,定义对数据库、表、字段、用户的访问权限和安全级别 | 1.GRANT、REVOKE等;2.Transaction Control:事务控制;3.COMMIT、ROLLBACK、SAVEPOINT等 |
书写规范
- 在数据库系统中,SQL语句不区分大小写(建议用大写) ,但字符串常量区分大小写
- SQL语句可单行或多行书写,以“;”结尾。
- 关键词不能跨多行或简写。
- 用空格和缩进来提高语句的可读性。
- 子句通常位于独立行,便于编辑,提高可读性。
- 注释:
- /* */ 和// 为多行注释
- – 和 # 为单行注释
库相关
| 功能 | 格式 | 用法 |
|---|---|---|
| 数据库的登录 | mysql -u 用户名 -h 服务器的主机地址 -p密码 -A | -u 后面跟登录数据库的用户名,这里使用root;-h 后面的参数是服务器的主机地址,在这里客户端和服务器在同一台机器上,所以输入 localhost 或者 IP 地址-p 后面是用户登录密码,注意:-p 和密码之间没有空格。如果出现空格,系统将不会把后面的字符串当成密码来对待,没有密码时不写-;-A参数:不预读数据库信息 |
| 数据库的退出 | exit/quit或者\q | 直接输入即可 |
| 查看数据库 | show databases like ‘sys’; | 也可带有通配符进行查看,如%',(%:匹配任意零个或多个字符;_:匹配任意单个字符) |
| 查看当前使用的数据库 | select database(); | 若当前没有使用数据库,则显示空 |
| 显示数据库版本、时间 | 显示数据库版本: select version();显示数据库时间: select now(); | 直接输入即可 |
| 创建数据库 | create database 数据库名 | 若数据库已存在,则报错 |
| 查看创建数据库的语句 | show create database 数据库名 | 在创建数据库或查看创建数据库语句时,database没有s |
| 选择数据库 | use 数据库名 | 直接输入即可 |
| 删除数据库 | drop database 数据库名 | 直接输入即可 |
| 查看当前用户 | select user() | 直接输入即可 |
表相关
| 功能 | 格式 | 用法 |
|---|---|---|
| 创建表 | create table 表名 (表选项) | 1.默认的情况是,表被创建到当前的数据库中。若表已存在、没有当前数据库或者数据库不存在,则会出现错误;2.要创建的表的名称不区分大小写,不能使用SQL语言中的关键字,如DROP、ALTER、INSERT等;3.必须指定数据表中每个列(字段)的名称和数据类型,如果创建多个列,要用逗号隔开 |
| 查看表 | show tables [from 数据库名][like wild]; | 直接输入即可 |
| 删除表 | drop table [if exists] 表名; | 1.用户必须拥有执行 drop table 命令的权限,否则数据表不会被删除;2.推荐使用if exists字句,即先判断是否存在,存在则删除,如drop table if exists tb1; |
| 修改表名 | 方法一:alter table 表名 rename 新表名; 方法二:rename table 表名 to 新表名; | 直接输入即可 |
| 添加列 | alter table 表名 add 新列名 列类型 [after/first] 列名; | 1.after:在指定列之后插入新列;2.first:在第一列插入新列;3.注意无before关键字 |
| 删除列 | alter table 表名 DROP 列名; | 直接输入即可 |
| 修改列名 | alter table 表名 change 旧列名 新列名 列类型; | 直接输入即可 |
| 修改列类型 | alter table 表名 modify 列名 列类型; | 直接输入即可 |
| 修改列位置 | alter table 表名 modify 列名 列类型 after 某列; | 直接输入即可 |
| 复制表结构 | 方法一:create table 新表名 like 源表;方法二:create table 新表名 select * from 源表 ;方法三:如果已经存在一张结构一致的表,复制数据: | 直接输入即可 |
replace语句
- replace和insert语句的功能基本相同
- 使用replace语句向表中插入新数据时,如果新数据的主键或者唯一键约束的字段值与原有数据相同,则原有数据会被西安删除,在插入新数据
- 使用replace的最大好处就是可以将delete和insert合二为一(效果相当于更新),形成一个原子操作,这样无需将delete操作与insert操作置于事务中了
用户相关
| 语句 | 说明 |
|---|---|
| 查看用户 | select user 用户 from mysql.user; |
| 查看用户权限 | show grants;或show grants for 用户名; |
| 删除用户 | drop user 用户名;或drop user 用户名@‘host’; |
| 给用户授权 | grant 授权列表 on 库名.表名 to ‘username’ [with option参数];或mysql> grant 授权列表 on 库名.表名 to ‘username’@'host‘ [with option参数]; |
| 回收用户权限 | revoke 授权列表 on 库名.表名 from 用户; |
注:原有数据删除时也不能未被外键约束的条件
删除语句
| 语句 | 功能 |
|---|---|
| drop | 删除数据库、表、表中的列,删除速度最快 |
| delete | 删除数据,保留表结构,可以回滚(如果数据量大,很慢) |
| truncate | 删除所有数据,保留表结构,不可以回滚(一次性全部删除所有数据,速度相对很快) |
索引相关
索引本质
- Mysql表建立索引,是为了避免查询时走全表扫描,减少时间开销
- 无论是全表扫描还是通过索引查询,本质上都涉及磁盘 I/O。
- 此外,MySQL 有优化措施,如局部性读取原理,避免不必要的磁盘 I/O。
索引分类
- 按照存储方式层次分类:
| 类型 | 说明 |
|---|---|
| 聚簇索引 | 逻辑上连续且物理空间连续,索引数据和表数据在磁盘中的位置是一起的,一张表中只能存在一个聚簇索引,聚簇索引要求索引必须是非空唯一索引,一般适合采用带有自增性的顺序值。 |
| 非聚簇索引 | 逻辑上连续,物理空间上不连续,索引数据和表数据在磁盘中分开存储,用物理地址的方式维护两者的联系。 |
- 按照功能逻辑层次分类:
| 类型 | 说明 |
|---|---|
| 普通索引 | 加速查找,最常见的索引,允许重复 |
| 唯一索引 | 加速查找,且进行约束(不能重复) |
| 主键索引 | 加速查找,且进行约束,且不为空 |
| 全文索引 | 仅可用于MyISAM表,建立于char字段 |
| 空间索引 | 使用不多,基于GIS(地址信息系统)的空间数据相关字段创建 |
- 创建索引:
| 创建索引 | 语法 |
|---|---|
| 创建表时创建索引 | 创建前缀索引:create table mytable(age int(3), name varchar(20), index index_name(name(3)) |
| 再已存在的表上创建索引 | 1.创建单列索引:create [unique/fulltext/spatial] index 索引名 on 表名(列名);2.创建多列索引:create [unique/fulltext/spatial] index 索引名 on 表名(列名1,列名2…); |
| 使用alter table 语句创建索引 | alter table 表名 add [unique/fulltext/spatial] index 索引名(列名); |
- 其它语法
| 功能 | 语法 |
|---|---|
| 查看索引 | show index from 表名\G |
| 删除索引 | drop index 索引名 on 表名 |
视图相关
视图本质:
- 视图不占用内存,以此无法创建索引
- 对视图的所有修改操作(如插入、删除、更新)都是基于基表的,即对视图的修改操作实际上时对基表的修改
- 再不加with参数的情况下,向视图内插入数据时,视图中的select的where条件会起作用,即会进行where条件判断
- 创建视图需要管理员授权
功能语法
| 功能 | 语法 |
|---|---|
| 创建视图 | CREATE VIEW view_name AS SELECT column1, column2 FROM table_name; |
| 查看视图 | show create view 视图名\G; |
| 查看视图内容 | select * from 视图名; |
| 修改视图结构 | alter view 原视图名[(字段列表)] as select语句; |
| 删除视图 | drop view [if exists] 视图名; |
事务相关
事务四大特性
| 特性 | 内容 |
|---|---|
| 原子性 | 事务不可分割,要么全部成功,要么全部失败。 |
| 一致性 | 事务使数据库从一个一致性状态变到另一个一致性状态。 |
| 隔离性 | 事务之间相互隔离,避免相互干扰。 |
| 持久性 | 事务提交后,数据持久保存,不会因故障丢失。 |
隔离级别
| 级别 | 内容 |
|---|---|
| 读未提交 | 允许读取未提交的数据,存在脏读问题。 |
| 读已提交 | 只能读到已提交的数据,可避免脏读,但有不可重复读问题。 |
| 可重复读 | 同一事务中多次读取结果相同,可避免脏读和不可重复读,但有幻读问题(MySQL 默认)。 |
| 串行化 | 事务串行执行,可避免所有并发问题。 |
语法功能
| 功能 | 语法 |
|---|---|
| 查看自动提交的参数 | select @@autocommit; |
| 开启事务 | begin; |
| 回滚事务 | 设置回滚点:savepoint 回滚点名;回滚到指定的回滚点:rollback to 回滚点名; |
| 提交事务 | commit; |
| autocommit | 说明 |
|---|---|
| 为1 | 开启事务需先写begin,再进行commit或rollback操作 |
| 为0 | MySQL 5.5 版本后会自动加 begin,但每次 DML 操作后若要持久化存储,需进行 commit 提交 |
注
- 回滚点时线性状态,回滚到初始状态会删除中间设置的所有状态
- commit提交数据持久化存储,若要回滚,须在commit之前进行
- Mysql默认开启自动提交,可通过设置开启或关闭
- InnoDB所有操作(插入、删除、更新、查询)都在事务中进行
其它
| 语句 | 功能 |
|---|---|
| select 要查询的信息 from 表名 | ”要查询得信息“可以是:1.表中得一个字段或很多字段(中间用”,“分开) as 字段别名;2.常量值;3.表达式;4.函数 |
| select distinct要查询的信息 from 表名 | 使用distinct关键字可以从查询结果中清除重复行 |
| concat(str1, str2,…) | 用于简单地连接字符串 |
| concat_ws(separator, str1, str2,…) | 用于连接字符串并在连接的字符串之间插入指定的分隔符。 |
| 模糊查询 | 常用的语法格式主要使用LIKE关键字 |
附录
表约束
- 概念:在表上强制执行的数据校验规则
- 功能:1.主要用于保证数据库的完整性,如:当表中数据有相互依赖性时,可以保护相关的数据不被删除
- 创建方法:1.在创建表时规定约束(通过create table语句);2.在表创建之后通过alter table语句规定约束
- 约束分类:
| 分类 | 内容 |
|---|---|
| 单列约束 | 每个约束只约束一列 |
| 多列约束 | 每个约束可约束多列数据 |
- 约束作用
| 约束 | 作用 |
|---|---|
| not null (非空约束) | 非空约束,规定某个字段不能为空 |
| unique(唯一约束) | 唯一约束,规定某个字段在整个表中时唯一的 |
| primary key(主键约束) | 主键约束,非空且唯一 |
| foreign key(外键约束) | 用于建立表之间的关联,保证数据的参照完整性。 |
| check(检查约束) | 定义字段可接受的值的条件或范围。 |
| default(默认值约束) | 指定字段在未明确赋值时的默认值。 |
- 约束作用范围
| 范围 | 内容 |
|---|---|
| 列级约束 | 只能作用域一个列上,跟在列的后面,语法:列定义 约束类型 |
| 表级约束 | 可以作用在多个列上,不与列一起,而是单独定义,有四种类型:主键,外键,唯一,检查 |
注
- 表级约束使用add
- 普通行约束使用modify
总结
| 约束 | 总结 |
|---|---|
| 外键约束 | 1.写外键约束之前,必须存在主表;2.外键参考的只能是主表的主键约束或唯一约束;3.当主表的记录被子表参照时,主表数据不允许被删除;4.外键是构建于一个表的两个字段或者两个表的两个字段(两个表中各一个)之间的关系,外键确保了相关的两个字段的两个关系;5.子表(从表)外键参照的值必须在主表参照列值的范围内,或者为空(也可以加非空约束,强制不允许为空);6.外键约束必须在constraint中单独定义,不能在普通行中定义;7.有外键约束时,当子表中存在主表的数据值,该主表中的数据值不能被删除;当主表中某数据值不存在子表中时,主表中该数据值可以被删除 |
| 主键约束 | 1.主键从功能上看相当于非空且唯一,一个表中只允许一个主键,主键是表中唯一确定一行数据的字段,主键字段可以是单字段或者是多字段的组合;2.当建立主键约束时,Mysql为主键创建对应的索引 |
| 检查约束 | 检查约束在8.0之前,Mysql默认但不会强制地遵循check约束(写不报错,但是不生效,需要通过触发器完成),8.0之后就开始正式支持这个约束了 |
| 唯一约束 | 1.唯一约束条件确保所在的字段或字段组合不出现重复值;2.唯一约束条件的字段允许出现多个NULL;3.同一张表内可建多个唯一约束;4.唯一约束可由多列组合而成;5.建唯一约束时Mysql会为之建立对应的索引;6.如果不给唯一约束起名,该唯一约束默认与列名相同 |
| 自动增长 | 1.为新的行产生唯一的标识,一个表只能有一个auto_increment,且该属性必须为主键的一部分;2.auto_increment的属性可以时任何整数类型(自动排序);3.允许插入null,会自动添加值 |
| 非空约束 | 1.列级约束,只能使用列级约束语法定义2.可确保字段值不允许为空 |
| 默认值约束 | 1.可以使用default关键字设置每一个字段的默认值; |
运算符
| 运算符 | 内容 |
|---|---|
| 比较运算符 | ==、!=、 <、 >、 >=、 <= |
| 逻辑运算符 | and(与)、or(或)、not(非)、xor(异或)、between and、not between and、in、not in、is、is not |
注
- xor(异或):当仅有一个条件为真时,返回真;如果两个条件都为真或都为假,则返回假
正则表达式
| 语句 | 功能 |
|---|---|
| ? | 字符匹配 0 次或 1 次 |
| ^ | 字符串的开始 |
| $ | 字符串的结束 |
| . | 任何单个字符 |
| […] | 在方括号内的字符列表 |
| [^…] | 非列在方括号内的任何字符 |
| p1 | p2 | p3 | 交替匹配任何模式 p1,p2 或 p3,零个或多个前面的元素 |
聚合函数
| 语句 | 说明 |
|---|---|
| count | 1.用于计算行的数量,可以使用count()来计算所有行的数量,也可以使用count(字段名)来计算特定列中非NULL值的数量;2.count()表示所有数据行,不会忽略null值,而count(字段)和其它聚合函数会忽略null值(bull值不统计) |
| avg | 用于计算数值列的平均值 |
| sum | 用于计算数值列的总和 |
| min | 用于找到数值列中的最小值 |
| max | 用于找到数值列中的最大值 |
| group_concat | 1.用于将分组后某一列的值连接成一个字符串;2.默认以逗号分隔 |
| group by | 1.吧该列具有相同值得多条记录当成一组记录处理,最后每组只输出一条记录;2.group by 子句得真正作用于与各种聚合函数配合使用,用来对查询出来得数据进行分组 |
| having | 1.having子句用来对分组后得结果再进行条件过滤(所以having中得条件只能是与查询字段相关);2.where和having都是用来做条件限定得,但是having只能用在group by 之后;3.分组后加条件,使用having |
| order by | 1.用于对查询结果进行排序;2.可以根据一个或多个列的值对结果进行排序,并指定升序或降序排序 |
| limit | 用于限制select查询返回的行数(对于处理大量数据并且只需要部分结果时非常有用) |
注
- having和where的区别:
| 区别 | 进行条件筛选 | 可否使用聚合函数 |
|---|---|---|
| having | 分组前 | 可以 |
| where | 分组后 | 不可以 |
查询类型
完整的select语句
- select 去重选项 字段列表 [as 字段别名] from 数据源 [where子句] [group by 子句]
[having子句] [order by 子句] [limit子句];
查询类型
| 类型 | 说明 |
|---|---|
| 联合查询:union、union all | 1.将多个查询结果合并;2.去重:union;不去重:union all |
| 多表关联查询:内连接(inner join)、左连接(left join)、右连接(right join) | 1.内连接:返回两个表中仅在连接条件满足时,相互匹配的行的组合;2.左连接:以左表为基础,将左表的所有行列出,再根据连接条件与右表匹配,右表中匹配的行与之组合,右表不匹配的行对应部分显示为 NULL;3.右连接:与做连接相反 |
| 自查询 | 1.原理:一张表起多个别名;2.使用inner join实现自查询 |
| 子查询 | 子查询的外部的语句可以是 insert,update,delete,select 中的任何一个 |
三范式小结
若不规范设计表时,会存在以下问题:
- 整张表数据比较冗余,同一个学生信息会出现多条。
- 表结构特别臃肿,不易于操作,要新增一个学生信息时,需添加大量数据。
- 需要更新其他业务属性的数据时,比如院系院长换人了,需要修改所有学生的记录。
三大范式优化:
| 范式 | 说明 |
|---|---|
| 1NF | 确保原子性,表中每一个类数据都必须是不可再分的字段 |
| 2NF | 确保唯一性,每张表都只描述一种业务属性,一张表只描述一件事 |
| 3NF | 确保独立性,表中除主键外,每个字段之间不存在任何依赖,都是独立的 |
经过三范式的设计优化后,整个库中的所有表结构,会显得更为优雅,灵活性也会更强
日志文件
| 日志 | 说明 |
|---|---|
| 错误日志 | 记录数据库运行中的错误信息 |
| 二进制日志 | 记录数据更改操作,用于数据恢复和复制 |
| 查询日志 | 记录执行的查询语句 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









