






 文章详细介绍了Redis在热点数据缓存、限时服务、计数器、排行榜、分布式锁、延迟队列、分页模糊搜索、点赞关系存储、队列等场景的应用,并讨论了Redis的RDB和AOF两种持久化方式的优缺点。此外,还阐述了Redis的主从模式、哨兵模式和集群模式,以解决单机压力和故障问题。
文章详细介绍了Redis在热点数据缓存、限时服务、计数器、排行榜、分布式锁、延迟队列、分页模糊搜索、点赞关系存储、队列等场景的应用,并讨论了Redis的RDB和AOF两种持久化方式的优缺点。此外,还阐述了Redis的主从模式、哨兵模式和集群模式,以解决单机压力和故障问题。
1. redis的应用场景
(1) 热点数据的缓存: 由于redis访问速度块,支持的数据类型比较丰富,所以redis很适合用来储存热点数据,另外结合expire,我们可以设置国企时间然后进行缓存更新操作, 这个功能最为常见
(2)限时服务的运用: redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除该键,利用这一特点可以是运用在限时的优惠活动信息,手机验证码等场景。
(3)计数器相关问题: 计数器---比如电商网站商品的浏览量、视频网站视频的播放量等,为了保证数据实时效,每次浏览都会+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力,redis提供的incr命令来实现计数器功能, 内存操作, 性能非常好,非常适用于这些技术场景。
(4)排行榜相关问题: 关系型数据库在排行榜方面查询速度非常偏慢,所以可以借助redis的SortedSet进行热点数据的排序,在奶茶活动中,我们需要展示各个部门的点赞排行榜,所以我针对每个部门做了一个SortedSet,然后用户的openid作为上面的username,以用户的点赞数作为上面的score,然后针对每个用户做一个hash信息, 这个当时在实际运用中新能体验也是挺好的。
(5)分布式锁 ----Sys---本地锁: 在很多互联网公司中都使用了分布式技术,分布式技术带来的技术挑战是对同一个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不大的场景可以使用数据库的悲观锁、乐观锁来实现,但在并发量高的场合中,利用数据库锁来控制资源的并发访问是不太理想的,大大影响了数据库的性能。可以利用Redis的setnx功能来编写分布式的锁,如果设置返回1说明获取锁成功,否则获取锁失败,实际应用中要考虑的细节要更多。
这个主要利用redis的setnx命令进行,setnx:"set if not exists"就是如果不存在则成功设置缓存同时返回1,否则返回0 ,这个特性在俞你奔远方的后台中有所运用,因为我们服务器是集群的,定时任务可能在两台机器上都会运行,所以在定时任务中首先 通过setnx设置一个lock,如果成功设置则执行,如果没有成功设置,则表明该定时任务已执行。 当然结合具体业务,我们可以给这个
lock加一个过期时间,比如说30分钟执行一次的定时任务,那么这个过期时间设置为小于30分钟的一个时间 就可以,这个与定时任务的周期以及定时任务执行消耗时间相关。
当然我们可以将这个特性运用于其他需要分布式锁的场景中,结合过期时间主要是防止死锁的出现。(6)延时操作---延迟队列: 比如在订单生产后我们占用了库存,10分钟后去检验用户是够真正购买,如果没有购买将该单据设置无效,同时还原库存。 由于redis自2.8.0之后版本提供Keyspace Notififications功能,允许客户订阅Pub/Sub频道,以便以某种方式接收影响Redis数据集的事件。 所以我们对于上面的需求就可以用以下解决方案,我们在订单生产时,设置一个key,同时设置10分钟后过期, 我们在后台实现一个监听器,监听key的实效,监听到key失效时将后续逻辑加上。 当然我们也可以利用rabbitmq、activemq等消息中间件的延迟队列服务实现该需求。
(7)分页、模糊搜索: redis的set集合中提供了一个zrangebylex方法,语法如下:
ZRANGEBYLEX key min max [LIMIT offffset count]
通过ZRANGEBYLEX zset - + LIMIT 0 10 可以进行分页数据查询,其中- +表示获取全部数据 ,zrangebylex key min max 这个就可以返回字典区间的数据,利用这个特性可以进行模糊查询功能,这个也是目前我在redis中发现的唯一一个支持对存储内容进行模糊查询的特性。
前几天我通过这个特性,对学校数据进行了模拟测试,学校数据60万左右,响应时间在700ms左右,比mysql的like查询稍微快一点,但是由于它可以避免大量的数据库io操作,所以总体还是比直接mysql查询更利于系统的性能保障。(8)点赞、好友等相互关系的存储: 点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,社交网站的访问量通常来说比较大,而且传统的关系数据库类型不适合存储这种类型的数据,Redis提供的哈希、集合等数据结构能很方便的的实现这些功能Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。 又或者在微博应用中,每个用户关注的人存在一个集合中,就很容易实现求两个人的共同好友功能。
这个在奶茶活动中有运用,就是利用set存储用户之间的点赞关联的,另外在点赞前判断是否点赞过就利用了sismember方法,当时这个接口的响应时间控制在10毫秒内,十分高效。(9)队列: 由于redis有list push和list pop这样的命令,所以能够很方便的执行队列操作。 Redis列表结构,LPUSH可以在列表头部插入一个内容ID作为关键字,LTRIM可用来限制列表的数量,这样列表永远为N个ID,无需查询最新的列表,直接根据ID去到对应的内容页即可。
总结:
1.热点数据得缓存
2.限时任务
3.计算器--incr decr
4.分布式锁。==setnx
5.排行榜---sort set
2.redis的持久化
2.1 redis持久化的方式
(1)RDB---快照模式---在一定的时间内,对当前redis内存中的数据进行拍照储存。
(2)AOF---日志追加---每次执行的写命令,都会通过一个函数wirte记录到日志中。
2.2 RDB快照储存
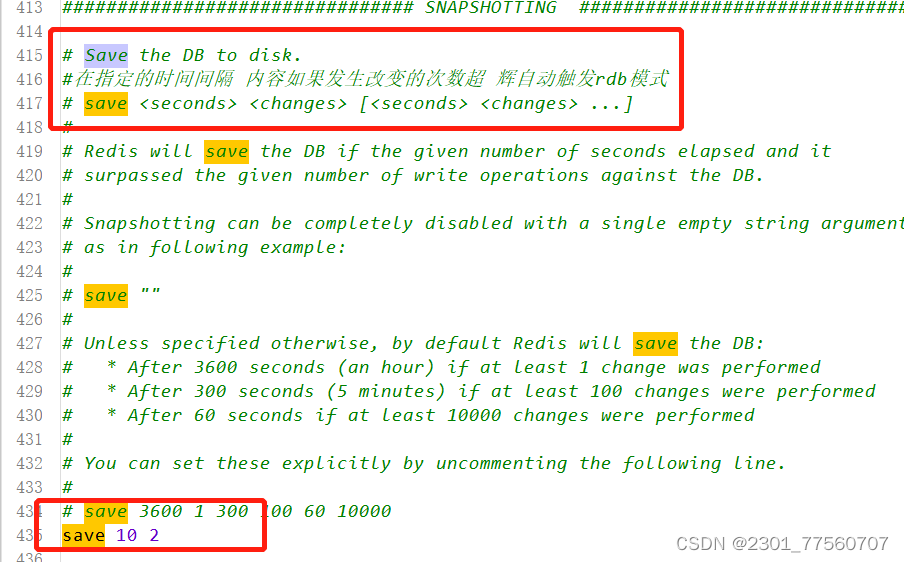
三种方式: save bgsave 通过配置文件
默认保存的文件名称: dump.rdb
(1)save和bgsave的区别
save模式:该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。
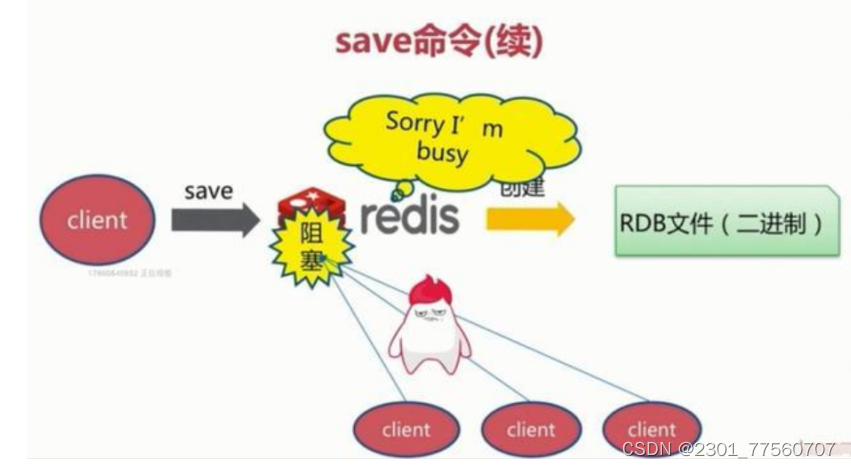
执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取。
bgsave模式:执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体流程如下:
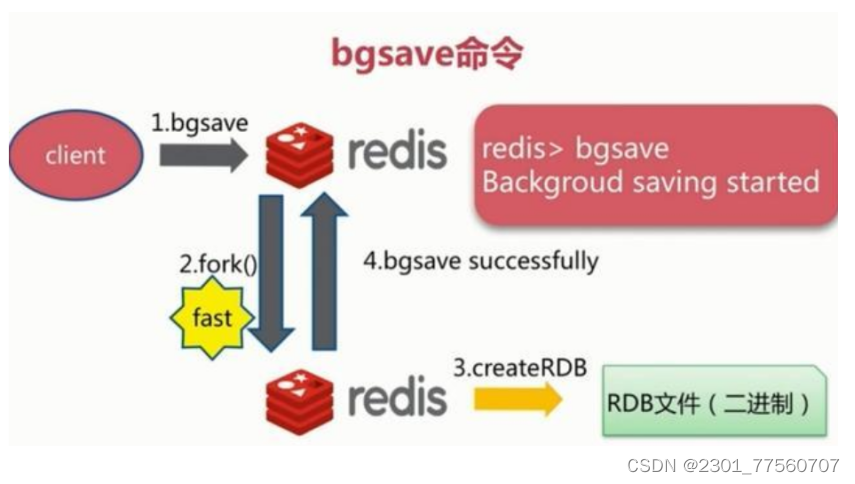
自动触发: 需要指定配置文件---一般不建议改,采用默认值---底层自动执行bgsave命令。
2.3 rdb数据回复
只需要把dump.rdb文件放入按照目录,当redis服务器启动时,会读取dump.rdb文件 并加载到内存中。
2.4 AOF持久化
他会把每个命令通过write函数记录到日志文件中,默认改持久化没有开启,需要修改配置文件来开启aof模式
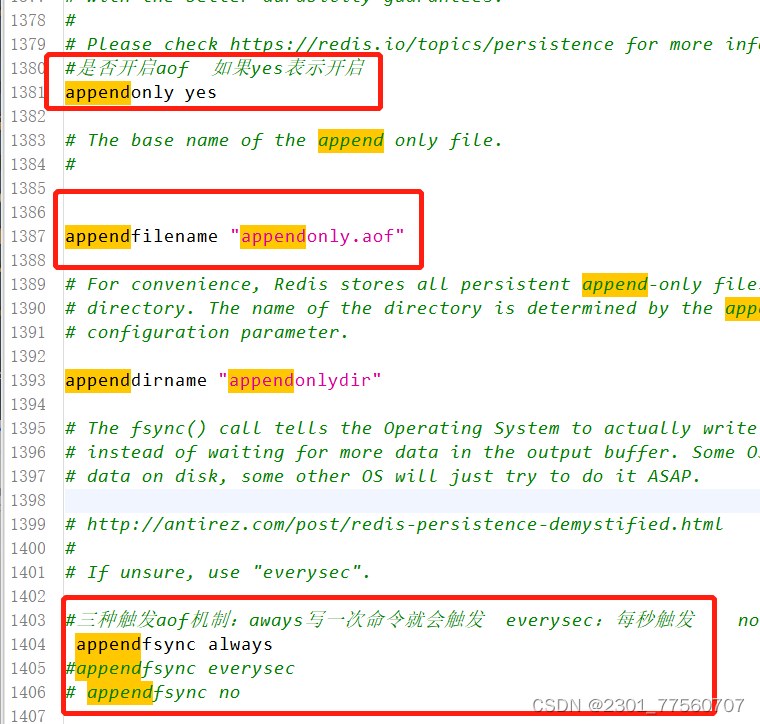
2.5 RDB和AOF的优缺点
(1)RDB: ---优点: 数据恢复速度块。 ---缺点:数据完整性差。
(2)AOF: ---优点: 数据恢复完整性强,最多丢失一条写命令;
-----缺点:数据恢复速度比较慢,因为需要把日志文件中所有命令执行一遍。
如果两个同时开启:恢复数据时采用的是AOF
3.redis的集群
3.1 为什么要使用redis集群
可以减少单机的压力, 解决单机的故障问题
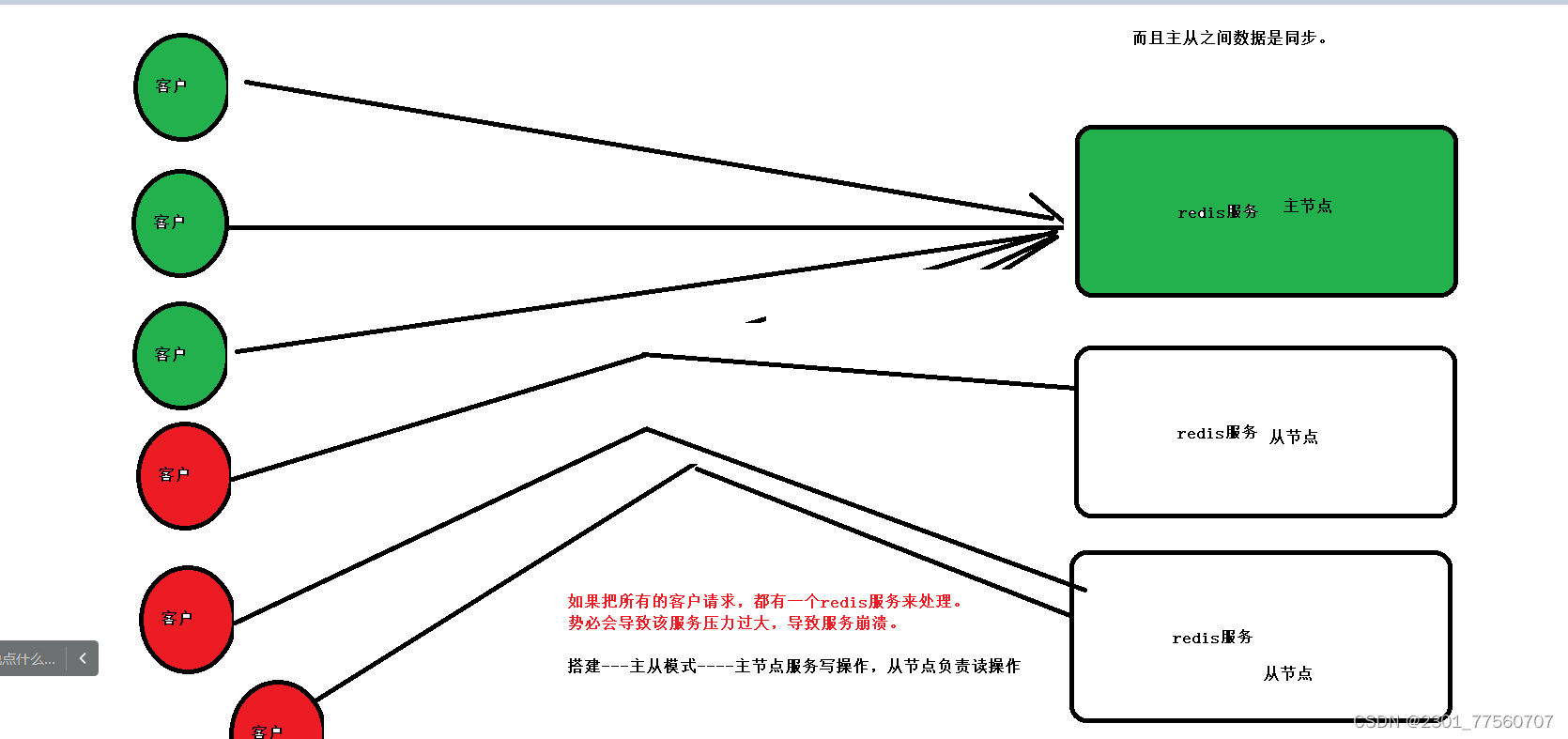
3.2 第一种集群方式----主从模式
(1)配置主从模式----配从不配主。
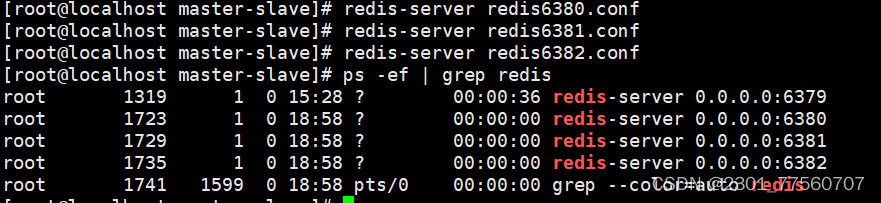
模拟: 以太linux系统,启动三台redis服务,依靠端口号:6380主节点,6381从节点,6382从节点
1. 复制三个redis配置文件放入master-slvae目录
 2.修改三个文件的配置
2.修改三个文件的配置
bind 0.0.0.0 -::1
# 关闭保护模式
protected-mode no
port 6380 | 6381 | 6382
dbfilename dump6380.rdb | dump6381.rdb | dump6382.rdb
appendfilename "appendonly6380.aof"
3.启动三台redis
4.三台客户端访问redis相应的服务器
redis-cli -p 6380 redis-cli -p 6381 redis-cli -p 6382

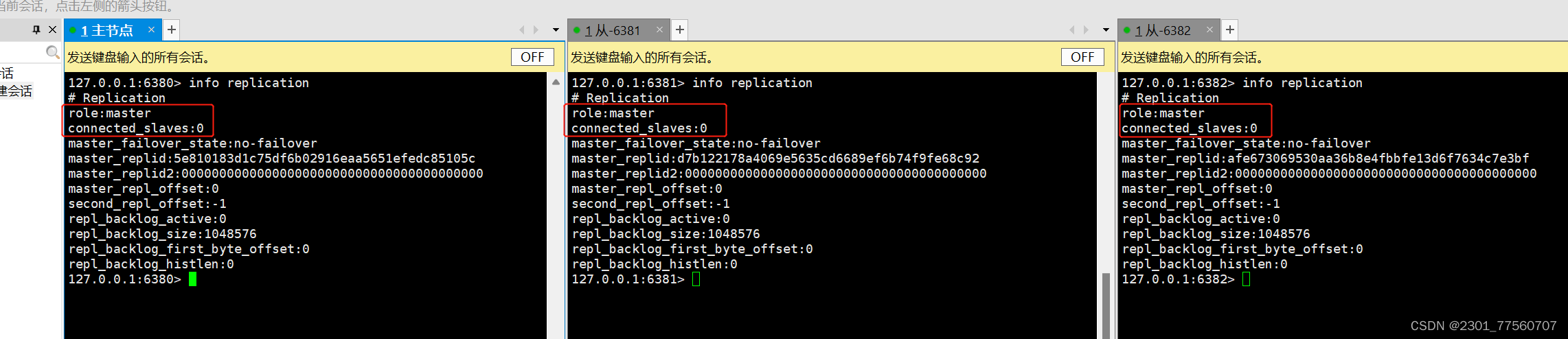
5.查看redis的角色--------info replication
他们之间没有主从关系
 6.配置主从关系----从节点
6.配置主从关系----从节点
slaveof 主节点ip 主节点port
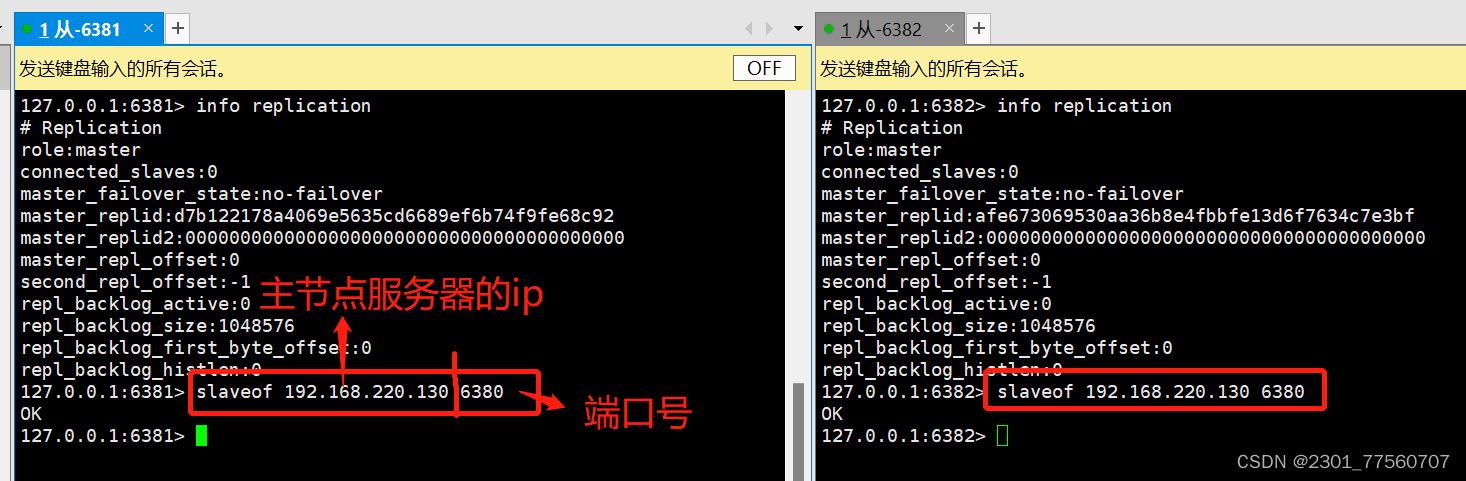
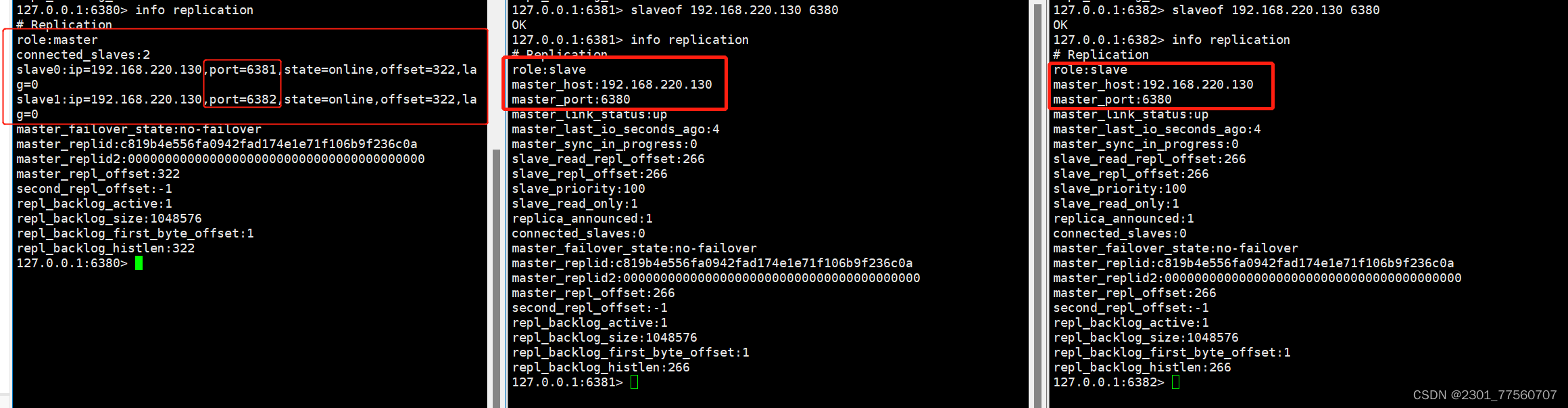
7.往主节点添加数据

思考:如果主节点挂掉---从节点是否可以上位?---------不会

如果新增一个小弟--该小弟是否可以把之前的数据同步过来。----可以
小弟是否可以进行写操作------只负责读操作不能负责写操作。
主节点是否可以进行写操作和读操作。-----> 可以负责读写操作。
3.3 第二种集群模式-----哨兵模式
上面的主从模式的缺点: ----如果主机宕机后, 从节点无法上位,该redis服务就无法执行写操作 。
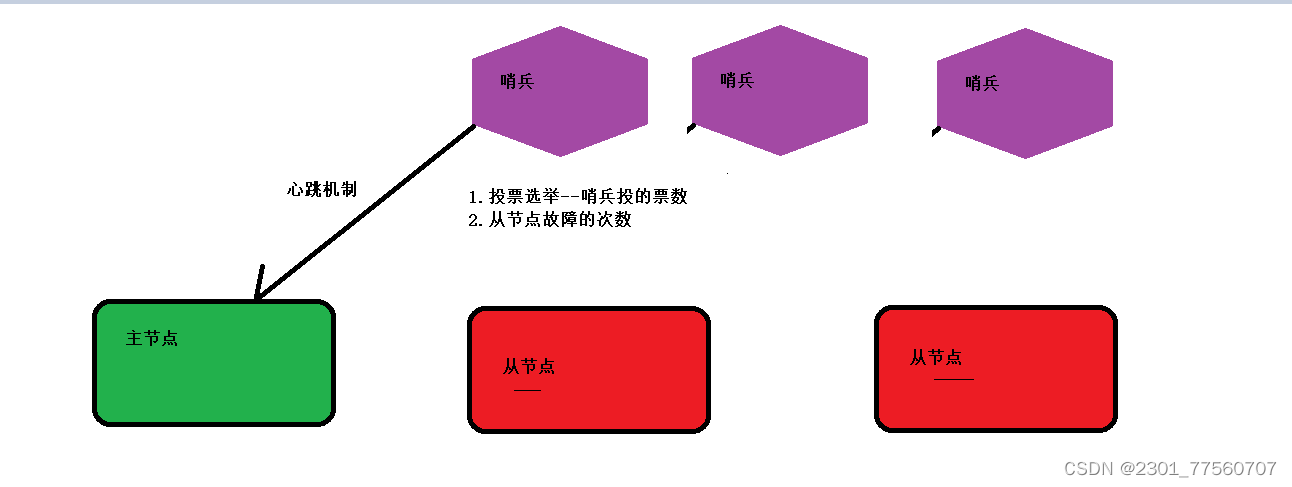
sentinel.conf文件

开启哨兵服务 ------- redis-sentinel sentinel.conf
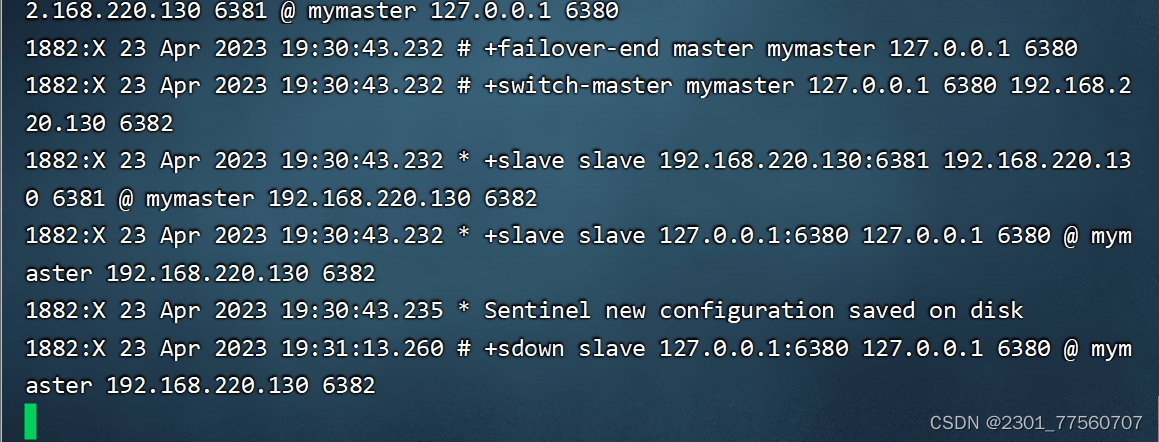
演示:主节点宕机,从节点上位
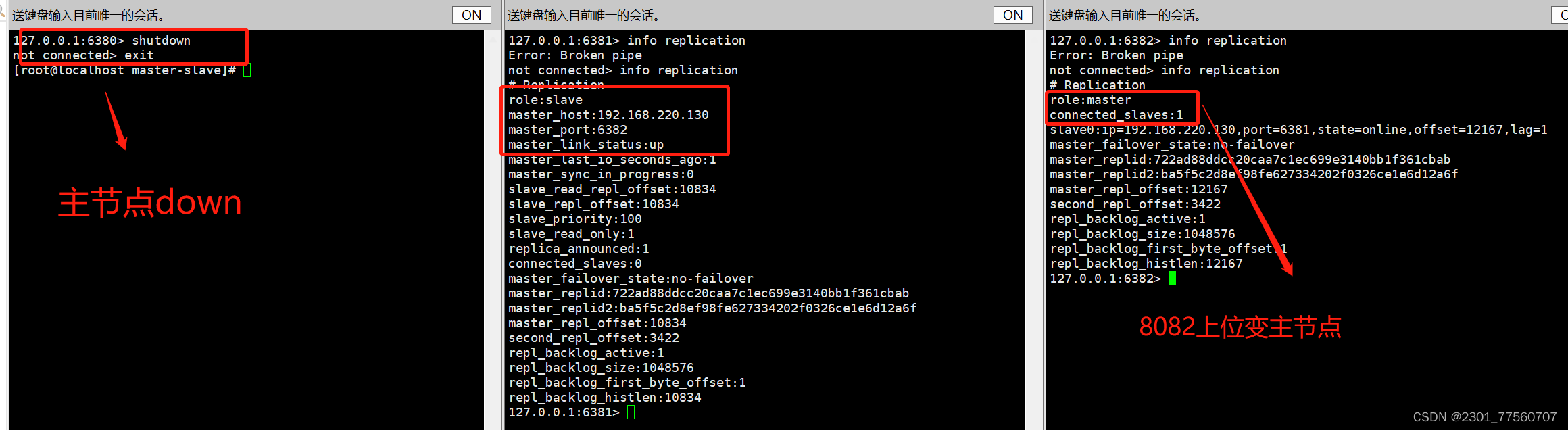
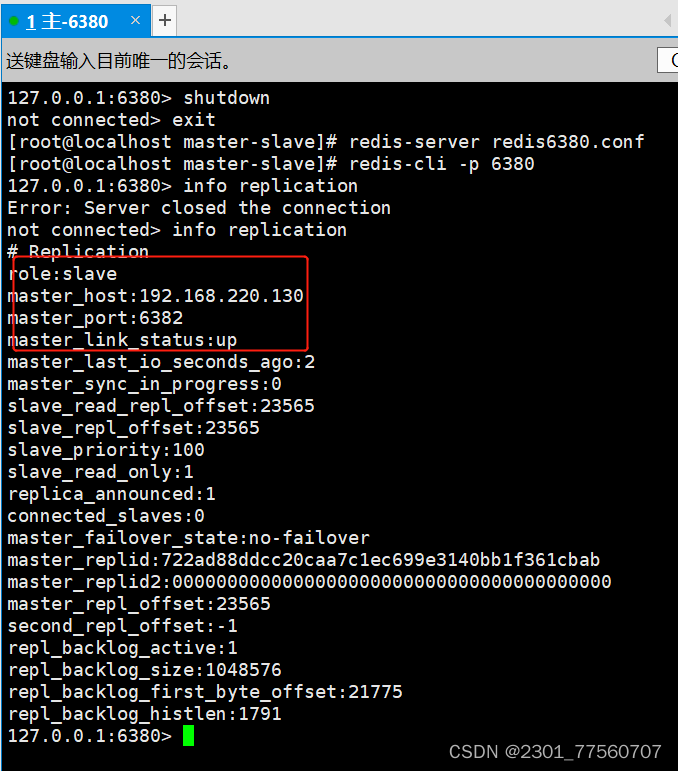
如果原来的主节点回来---它需要跟在现在的主节点混。
3.4 第三种-----集群模式
哨兵模式的缺点: 它只有一个主节点---如果现在写操作并发高,那么还会导致主节点压力过大。
去中心化-----
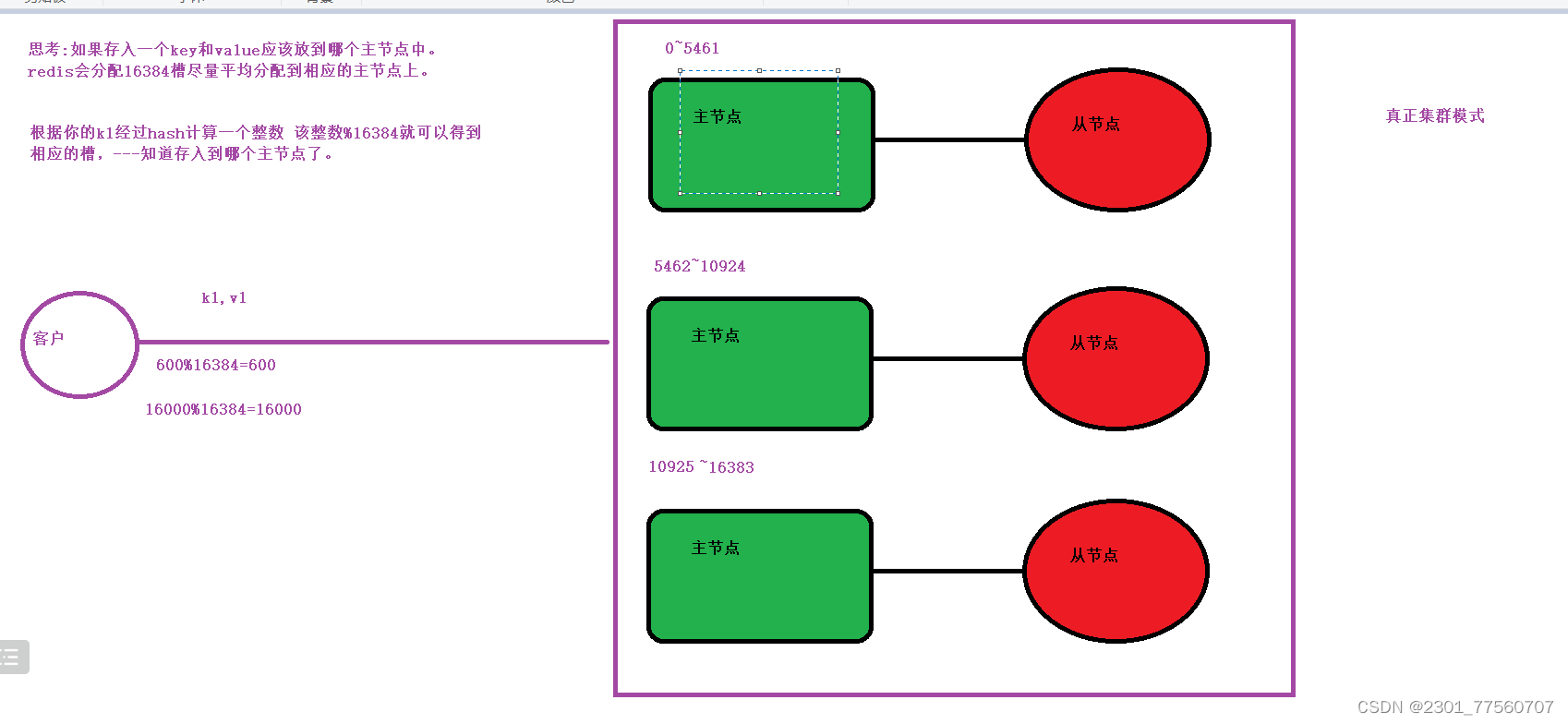
准备: 6台redis服务。---6个服务中不能有数据。
7001、7002、7003 =============主节点
7004、7005、7006 =====从节点
修改配置文件:都需要改
bind 0.0.0.0 port 7071 daemonize yes
appendonly yes ---#打开AOF持久化 cluster-enabled yes ---#开启集群
cluster-config-file nodes-7001.conf -----# 集群的配置文件,该文件自动生成
cluster-node-timeout 5000 -------# 集群的超时时间
开启上面6台redis服务器
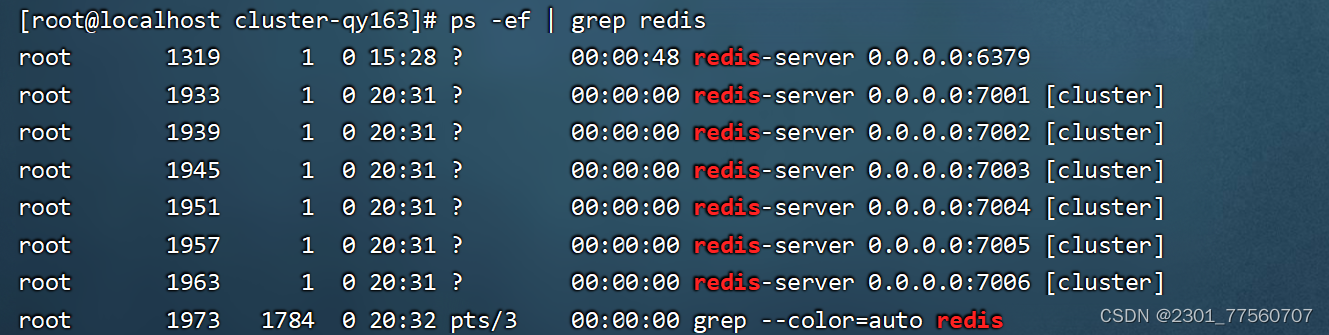
为6台redis配置槽以及主从关系
redis-cli --cluster create --cluster-replicas 1 192.168.220.130:7001 192.168.220.130:7002 192.168.220.130:7003 192.168.220.130:7004 192.168.220.130:7005 192.168.220.130:7006
---------cluster-replicas 1 : 从节点的个数
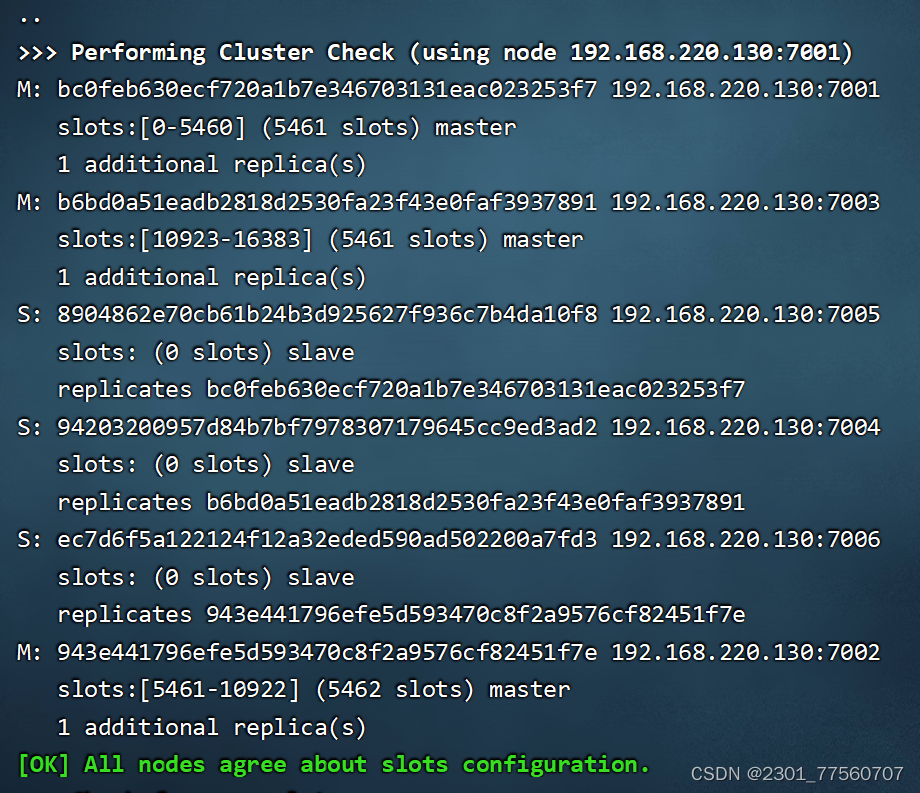
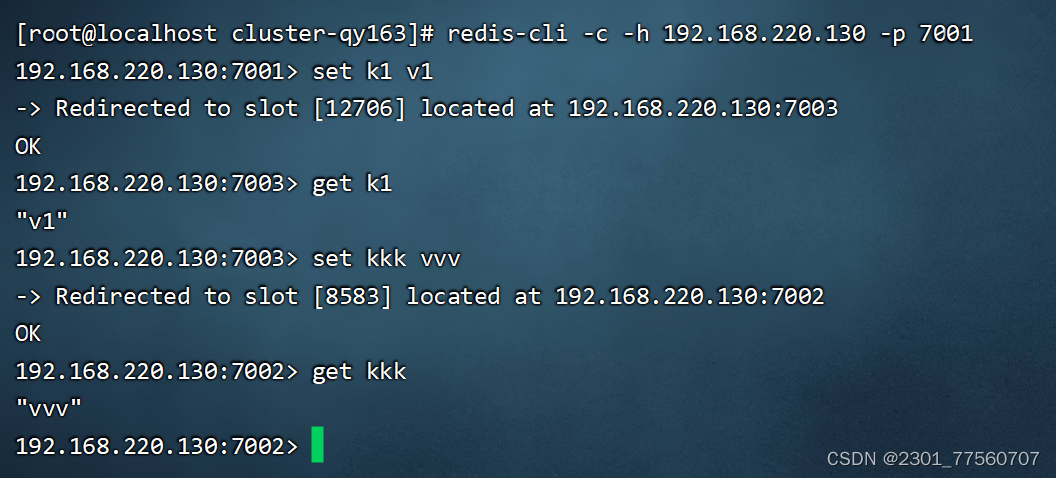
验证:redis-cli -c -h 127.0.0.1 -p 7001


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









