







事先声明的是,我只是个普普通通的在读大学生,这篇文章并不是专业文章,但我之前在学习计算机的过程中,互联网上有很多计算机的前辈在csdn,知乎,git上分享的文章的帮助,这种开源精神是互利共赢的,我也希望我能为其他人做出一点贡献,虽然不专业,但也可以为其他人节省一些时间,代码我会附录在结尾,该文章只适用于学习领域,切勿用于商业或其它盈利渠道。
本人已将代码分享到Git上,当然本article也附有代码,各位reader任选一个copy即可
适用范围:
本篇拟人化爬虫,适用于一些经过JavaScript加密后的网页,我自己当时初学网页和爬虫后,就兴高采烈的打算去爬虫去做舆情分析,结果发现主流的社交媒体基本都加密的,以我的实力根本没法破解,但平时有些竞赛或期末论文需要数据,那么只能想办法不适用常规网站爬取方法。
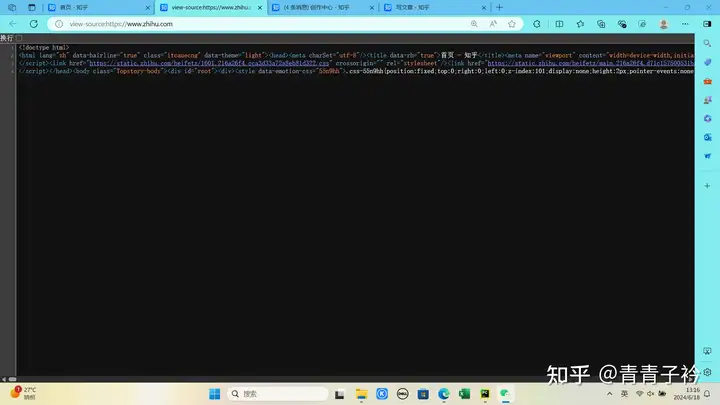
像是这种加密网页
值得注意的是,如果在有源码的情况下,还请通过网页源代码进行爬取,这种方式更准确,更高效。
事前准备:
首先需要Google开源的tesseract的图片提取文字软件,安装之后并添加到环境变量。
尽量安装最新版本,我一年前也用过tesseract5.0,现在5.3明显比5.0效果能好很多。
我是跟着b站 tesseract安装与配置 教程来的。
代码实现:
首先,需要配置环境
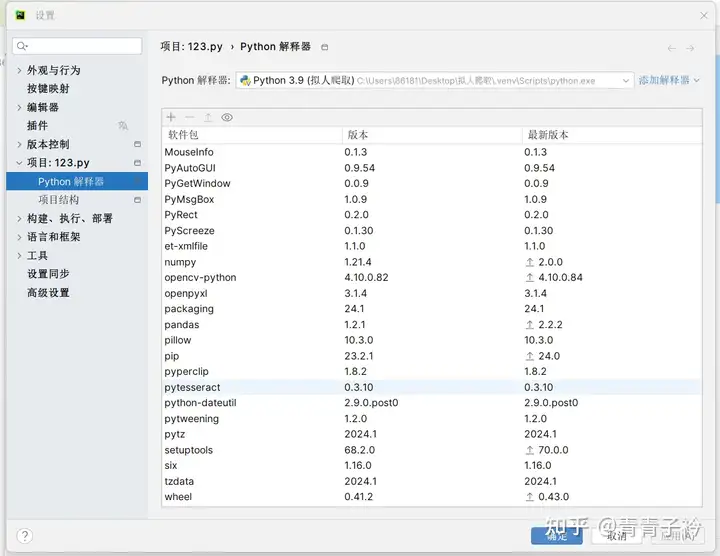
这是我配置的环境,注意版本问题,部分不同的包版本不同可能会报错。
导入需要的包
import os
import cv2
import numpy as np
import pytesseract
import pandas as pd
import pyautogui
import time
from PIL import Image
# 配置Tesseract路径,设置TESSDATA_PREFIX环境变量
pytesseract.pytesseract.tesseract_cmd = r'E:\tesseract\tesseract.exe'
os.environ['TESSDATA_PREFIX'] = r'E:\tesseract\tessdata'定义截图函数,以供之后提取文字
def capture_screenshot(region, file_name):
"""此模块负责截取指定区域图片,并保存到screenshot_dir文件夹下
如果成功返回截取的图片,不成功返回空值"""
try:
screenshot_dir = '截图'
if not os.path.exists(screenshot_dir):
os.makedirs(screenshot_dir)
file_path = os.path.join(screenshot_dir, file_name)
screenshot = pyautogui.screenshot(region=region)
screenshot.save(file_path)
return screenshot
except Exception as e:
print(f"截图模块发生错误: {e}")
return None定义调用tesseract函数
def extract_text_from_image(image):
"""
此模块调用tesseract的图片识别文字功能,(image, lang='chi_sim')两个参数分别是图片,文字
如果成功返回识别后的文本,不成功返回空值
"""
try:
text = pytesseract.image_to_string(image, lang='chi_sim')
return text.strip() # 去除首尾空格和换行符
except Exception as e:
print(f"提取文字模块错误: {e}")
return ""定义输出为excel函数
def save_to_excel(data, filename):
"""
此模块为将输出数据导出为excel,以便进行进一步数据分析
"""
try:
df = pd.DataFrame(data, columns=['Message'])
# 执行替换操作:删除空格,将换行符替换为中文逗号
df['Message'] = df['Message'].str.replace(r'\s+', '', regex=True)
df['Message'] = df['Message'].str.replace(r'\n', ',', regex=True)
df.to_excel(filename, index=False)
except Exception as e:
print(f"输出模块报错: {e}")定义两个限制模块
def extract_white_text_from_rectangles(image, rectangles, screenshot_index):
messages = []
# 转换为OpenCV的BGR格式
open_cv_image = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
for i, rect in enumerate(rectangles):
x1, y1, x2, y2 = rect
# 裁剪出矩形区域
box_image = open_cv_image[y1:y2, x1:x2]
# 设置白色的颜色阈值范围
lower_white = np.array([230, 230, 230], dtype=np.uint8)
upper_white = np.array([255, 255, 255], dtype=np.uint8)
# 根据颜色过滤出白色部分
mask = cv2.inRange(box_image, lower_white, upper_white)
# 转换为PIL图像以进行OCR
pil_image = Image.fromarray(mask)
# 提取白色文字
text = extract_text_from_image(pil_image)
# 将每个消息保存到列表中
messages.append(text)
return messages
def main():
# 定义截图区域 (left, top, width, height)
region = (1360, 0, 540, 940) # 根据实际情况调整
data = []
scroll_step = 800 # 增加滚动步长
scroll_pause_time = 0.5 # 每次滚动后的暂停时间
for i in range(150): # 截图次数
screenshot_name = f'截图{i}.png'
image = capture_screenshot(region, screenshot_name)
if image:
# 检测矩形区域
rectangles = detect_rectangles(image)
# 提取每个矩形区域内的白色文字
messages = extract_white_text_from_rectangles(image, rectangles, i)
data.extend(messages)
# 模拟在选中的区域内向下滚动
pyautogui.moveTo(region[0] + region[2] // 2, region[1] + region[3] // 2)
pyautogui.scroll(-scroll_step)
time.sleep(scroll_pause_time)
save_to_excel(data, 'extracted_messages.xlsx')测试函数
if __name__ == '__main__':
main()代码原理
循环执行:
截图(因为利用的是图片识别技术,需要先截图)
切割矩形区域(为了提高识别的准确性和连贯性,先对每个聊天框进行切割,再识别)
识别文字(可利用颜色识别,一般来讲文字都是一个颜色的)
滚动下滑(替代人手工下滑,实现自动化)
可调参数
# 配置Tesseract路径,设置TESSDATA_PREFIX环境变量
pytesseract.pytesseract.tesseract_cmd = r'E:\tesseract\tesseract.exe'
os.environ['TESSDATA_PREFIX'] = r'E:\tesseract\tessdata'调整Tesseract路径
screenshot_dir = '截图'可以更改引号内容,修改截图存储文件夹名称
text = pytesseract.image_to_string(image, lang='chi_sim')lang='chi_sim'可以调整语言,各种语言可去官网下载,下载后将语言包移动到tessdata文件夹下面
# 边缘检测
edges = cv2.Canny(blurred, 50, 150)
# 形态学操作以闭合边缘
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
closed = cv2.morphologyEx(edges, cv2.MORPH_CLOSE, kernel)因为我这里要找到聊天框都是圆角矩形,其它形状可以更改此处代码
# 过滤掉不符合宽度和高度范围的轮廓
if w >= 500 and h >= 135:可以过滤切割后每个圆角矩形的最小尺寸,避免截取文字分散化
# 设置白色的颜色阈值范围
lower_white = np.array([230, 230, 230], dtype=np.uint8)
upper_white = np.array([255, 255, 255], dtype=np.uint8)识别的文字的颜色阈值
# 定义截图区域 (left, top, width, height)
region = (1360, 0, 540, 940) # 根据实际情况调整截图区域,参数为像素点
scroll_step = 800 # 增加滚动步长
scroll_pause_time = 0.5 # 每次滚动后的暂停时间滚动步长为每次下滑像素
暂停时间可根据刷新时间而定,如果担心被识别,可以增添一个随机函数rand
for i in range(150):下滑次数/截取次数
实现效果:
以我们学校校园墙为例
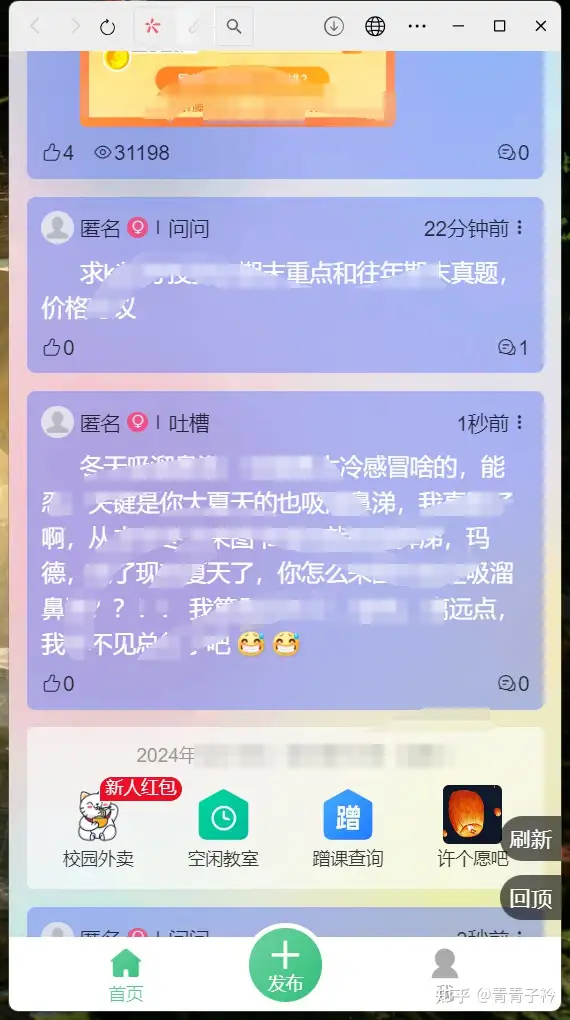
输出表格
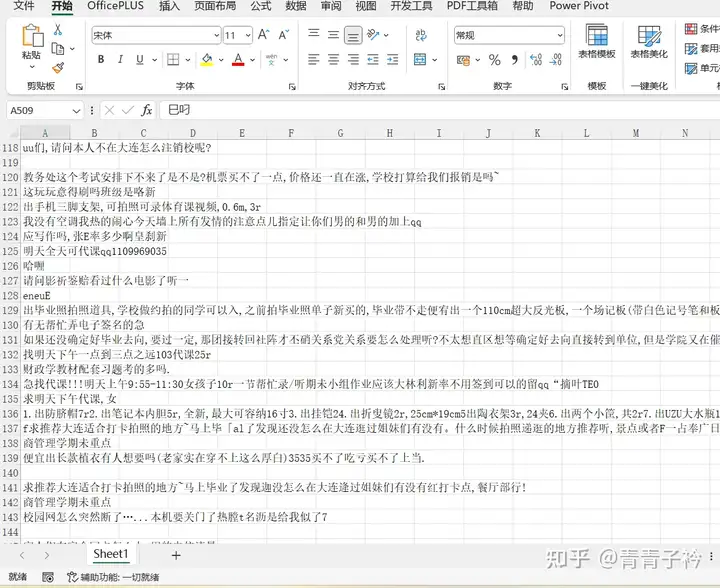
输出结果不是非常完善的数据,但也可以勉强适用,作为无法进行源码爬取的平替。
完整代码
import os
import cv2
import numpy as np
import pytesseract
import pandas as pd
import pyautogui
import time
from PIL import Image
# 配置Tesseract路径,设置TESSDATA_PREFIX环境变量
pytesseract.pytesseract.tesseract_cmd = r'E:\tesseract\tesseract.exe'
os.environ['TESSDATA_PREFIX'] = r'E:\tesseract\tessdata'
def capture_screenshot(region, file_name):
"""此模块负责截取指定区域图片,并保存到screenshot_dir文件夹下
如果成功返回截取的图片,不成功返回空值"""
try:
screenshot_dir = '截图'
if not os.path.exists(screenshot_dir):
os.makedirs(screenshot_dir)
file_path = os.path.join(screenshot_dir, file_name)
screenshot = pyautogui.screenshot(region=region)
screenshot.save(file_path)
return screenshot
except Exception as e:
print(f"截图模块发生错误: {e}")
return None
def extract_text_from_image(image):
"""
此模块调用tesseract的图片识别文字功能,(image, lang='chi_sim')两个参数分别是图片,文字
如果成功返回识别后的文本,不成功返回空值
"""
try:
text = pytesseract.image_to_string(image, lang='chi_sim')
return text.strip() # 去除首尾空格和换行符
except Exception as e:
print(f"提取文字模块错误: {e}")
return ""
def save_to_excel(data, filename):
"""
此模块为将输出数据导出为excel,以便进行进一步数据分析
"""
try:
df = pd.DataFrame(data, columns=['Message'])
# 执行替换操作:删除空格,将换行符替换为中文逗号
df['Message'] = df['Message'].str.replace(r'\s+', '', regex=True)
df['Message'] = df['Message'].str.replace(r'\n', ',', regex=True)
df.to_excel(filename, index=False)
except Exception as e:
print(f"输出模块报错: {e}")
def detect_rectangles(image):
"""detect_rectangles与extract_white_text_from_rectangles模块为限制模块,这里共用了三种限制
1.大部分情况下,文字是在一个聊天框内,那么先把图片切割成一个个聊天框
2.字的颜色可以增加限制,我这里爬取的文字统一都是白色,其它需要爬取的文字也可以通过调节范围去识别
3.设定最小聊天框大小,进行过滤操作"""
rectangles = []
# 转换为OpenCV的BGR格式
open_cv_image = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
# 转为灰度图像
gray = cv2.cvtColor(open_cv_image, cv2.COLOR_BGR2GRAY)
# 高斯模糊
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 边缘检测
edges = cv2.Canny(blurred, 50, 150)
# 形态学操作以闭合边缘
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
closed = cv2.morphologyEx(edges, cv2.MORPH_CLOSE, kernel)
# 寻找轮廓
contours, _ = cv2.findContours(closed, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
# 计算轮廓的外接矩形
x, y, w, h = cv2.boundingRect(contour)
# 过滤掉不符合宽度和高度范围的轮廓
if w >= 500 and h >= 135:
# 保存矩形区域坐标
rectangles.append((x, y, x + w, y + h))
return rectangles
def extract_white_text_from_rectangles(image, rectangles, screenshot_index):
messages = []
# 转换为OpenCV的BGR格式
open_cv_image = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
for i, rect in enumerate(rectangles):
x1, y1, x2, y2 = rect
# 裁剪出矩形区域
box_image = open_cv_image[y1:y2, x1:x2]
# 设置白色的颜色阈值范围
lower_white = np.array([230, 230, 230], dtype=np.uint8)
upper_white = np.array([255, 255, 255], dtype=np.uint8)
# 根据颜色过滤出白色部分
mask = cv2.inRange(box_image, lower_white, upper_white)
# 转换为PIL图像以进行OCR
pil_image = Image.fromarray(mask)
# 提取白色文字
text = extract_text_from_image(pil_image)
# 将每个消息保存到列表中
messages.append(text)
return messages
def main():
# 定义截图区域 (left, top, width, height)
region = (1360, 0, 540, 940) # 根据实际情况调整
data = []
scroll_step = 800 # 增加滚动步长
scroll_pause_time = 0.5 # 每次滚动后的暂停时间
for i in range(150): # 截图次数
screenshot_name = f'截图{i}.png'
image = capture_screenshot(region, screenshot_name)
if image:
# 检测矩形区域
rectangles = detect_rectangles(image)
# 提取每个矩形区域内的白色文字
messages = extract_white_text_from_rectangles(image, rectangles, i)
data.extend(messages)
# 模拟在选中的区域内向下滚动
pyautogui.moveTo(region[0] + region[2] // 2, region[1] + region[3] // 2)
pyautogui.scroll(-scroll_step)
time.sleep(scroll_pause_time)
save_to_excel(data, 'extracted_messages.xlsx')
if __name__ == '__main__':
main()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









