




【精选优质专栏推荐】
- 《AI 技术前沿》 —— 紧跟 AI 最新趋势与应用
- 《网络安全新手快速入门(附漏洞挖掘案例)》 —— 零基础安全入门必看
- 《BurpSuite 入门教程(附实战图文)》 —— 渗透测试必备工具详解
- 《网安渗透工具使用教程(全)》 —— 一站式工具手册
- 《CTF 新手入门实战教程》 —— 从题目讲解到实战技巧
- 《前后端项目开发(新手必知必会)》 —— 实战驱动快速上手
每个专栏均配有案例与图文讲解,循序渐进,适合新手与进阶学习者,欢迎订阅。

前言
朴素贝叶斯算法是一种简单而高效的监督式机器学习方法,其高斯变体已在 OpenCV 库中实现。
本教程将带你学习如何使用 OpenCV 的普通贝叶斯算法:先在一个自定义的二维数据集上进行分类实验,再将其应用于图像分割任务。
完成学习后,你将掌握以下内容:
- 贝叶斯定理在机器学习中的核心思想与关键要点
- 如何在 OpenCV 中使用普通贝叶斯算法处理自定义数据集
- 如何基于普通贝叶斯算法实现图像分割
本教程共分为三部分:
- 机器学习中的贝叶斯定理回顾
- OpenCV 中的贝叶斯分类器
- 使用普通贝叶斯分类器进行图像分割
机器学习中的贝叶斯定理回顾
以下是贝叶斯定理中的一些关键要点。
贝叶斯定理之所以在机器学习中有用,是因为它提供了一个统计模型,用来刻画数据与假设之间的关系。
公式如下:
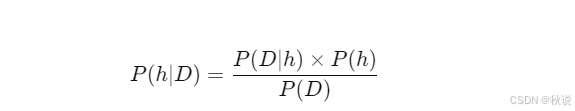
即:给定数据后,某一假设成立的概率(后验概率)可以通过以下方式计算:
-
( P(D|h) ):给定假设时观测到数据的概率(似然)
-
( P(h) ):假设独立于数据成立的概率(先验概率)
-
( P(D) ):独立于假设观测到数据的概率(证据)
贝叶斯定理假设输入数据 ( D ) 的所有变量(或特征)之间存在依赖关系。
在数据分类的上下文中,贝叶斯定理可用于计算给定数据样本属于某一类别的条件概率:
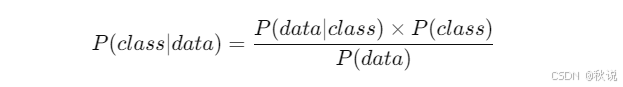
其中类别标签代替了假设。由于 ( P(data) ) 为常数,可忽略。
然而,计算似然 ( P(data|class) ) 通常很困难,因为这要求每个类别中都有足够多的样本来覆盖所有可能的特征组合。这在高维数据中几乎不可能。
为简化问题,出现了朴素贝叶斯(Naive Bayes)模型。它假设输入变量相互独立:
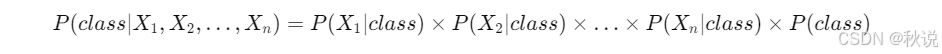
这样,模型由“条件依赖”简化为“条件独立”。虽然这一假设在真实数据中往往并不成立,但大大降低了计算复杂度,因此称为“朴素”。
OpenCV 中的贝叶斯分类器
当输入数据是连续型时,可以用连续概率分布建模,例如高斯(正态)分布。每个类别的数据都由其均值和标准差表示。
OpenCV 实现的贝叶斯分类器是普通贝叶斯分类器(Normal Bayes Classifier),也称为高斯朴素贝叶斯(Gaussian Naive Bayes)。它假设每个类别的输入特征服从正态分布。
正如 OpenCV 官方文档所述:
该简单分类模型假设来自每个类别的特征向量服从正态分布(但不一定彼此独立)。
—— OpenCV, Machine Learning Overview, 2023
接下来,我们将通过一个简单的二维数据集来学习如何在 OpenCV 中使用普通贝叶斯分类器。
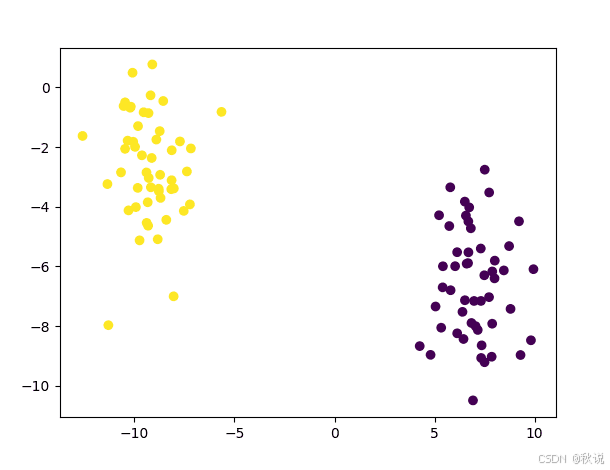
为此,我们生成一个包含 100 个数据点的数据集(通过 n_samples 参数指定),这些数据点平均分为两个高斯簇(通过 centers 参数指定),每个簇的标准差设为 1.5(由 cluster_std 参数指定)。
另外,我们定义 random_state 的值,以确保结果可复现。
# 生成二维数据点及其真实标签
x, y_true = make_blobs(n_samples=100, centers=2, cluster_std=1.5, random_state=15)
# 绘制数据集散点图
scatter(x[:, 0], x[:, 1], c=y_true)
show()
上述代码将生成如下所示的数据点分布图:
接下来,我们将对该数据集进行划分,将 80% 的数据用于训练集,剩余 20% 用于测试集:
# 将数据集划分为训练集和测试集
x_train, x_test, y_train, y_test = ms.train_test_split(x, y_true, test_size=0.2, random_state=10)
随后,我们创建一个普通贝叶斯分类器,并在将数据类型转换为 32 位浮点数后,对其进行训练和测试:
# 创建普通贝叶斯分类器
norm_bayes = ml.NormalBayesClassifier_create()
# 使用训练数据训练分类器
norm_bayes.train(x_train.astype(float32), ml.ROW_SAMPLE, y_train)
# 使用训练好的分类器生成预测结果
ret, y_pred, y_probs = norm_bayes.predictProb(x_test.astype(float32))
通过 predictProb 方法,我们可以获得每个输入向量(即每一行输入样本)的预测类别以及各类别的概率值。
在上述代码中:
-
预测的类别存储在 y_pred 中;
-
y_probs 是一个与类别数量相同列数的数组(此处为 2 列),表示每个输入向量属于各个类别的概率。
理论上,每个样本的概率值之和应为 1,但在此实现中可能不会严格归一化。原因是 OpenCV 的普通贝叶斯分类器返回的值并未除以证据项 ( P(data) )(该项在前面部分被省略)。
无论概率是否归一化,对于每个输入样本,其所属类别可通过选择概率值最大的类别来确定。
截至目前的完整代码如下:
from sklearn.datasets import make_blobs
from sklearn import model_selection as ms
from numpy import float32
from matplotlib.pyplot import scatter, show
from cv2 import ml
# 生成二维数据点及其真实标签
x, y_true = make_blobs(n_samples=100, centers=2, cluster_std=1.5, random_state=15)
# 绘制原始数据集
scatter(x[:, 0], x[:, 1], c=y_true)
show()
# 划分训练集与测试集
x_train, x_test, y_train, y_test = ms.train_test_split(x, y_true, test_size=0.2, random_state=10)
# 创建普通贝叶斯分类器
norm_bayes = ml.NormalBayesClassifier_create()
# 训练分类器
norm_bayes.train(x_train.astype(float32), ml.ROW_SAMPLE, y_train)
# 生成预测结果
ret, y_pred, y_probs = norm_bayes.predictProb(x_test.astype(float32))
# 绘制分类预测结果
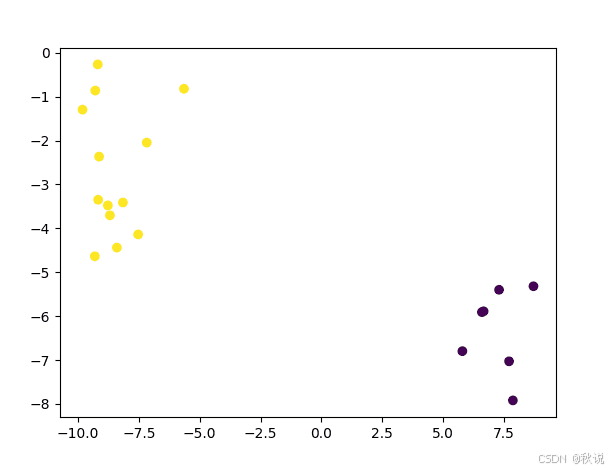
scatter(x_test[:, 0], x_test[:, 1], c=y_pred)
show()
从图中可以看到,普通贝叶斯分类器在该简单数据集上的预测结果是正确的:
使用普通贝叶斯分类器进行图像分割
在众多应用中,贝叶斯分类器常被用于皮肤分割(Skin Segmentation),即从图像中区分皮肤像素与非皮肤像素。
我们可以改写前面的代码,使其用于图像中的皮肤像素分割。
为此,我们使用 Skin Segmentation 数据集,其中包含 50,859 个皮肤样本和 194,198 个非皮肤样本。该数据集中每条记录包含像素的 BGR 值及其对应的 类别标签。
加载数据集后,我们将 BGR 像素值转换为 HSV 色彩空间(色相 Hue、饱和度 Saturation、明度 Value),并使用其中的 Hue(色相)值来训练普通贝叶斯分类器。
在图像分割任务中,Hue 比 RGB 更常用,因为它能更准确地反映颜色本质,且受光照变化影响较小。
在 HSV 模型中,Hue 的取值范围为 0° 到 360°:
from cv2 import ml
from numpy import loadtxt, float32
from matplotlib.colors import rgb_to_hsv
# 从文本文件中加载数据
data = loadtxt("Data/Skin_NonSkin.txt", dtype=int)
# 选择 BGR 像素值
BGR = data[:, :3]
# 将 BGR 转换为 RGB(交换第 1 列和第 3 列)
RGB = BGR.copy()
RGB[:, [2, 0]] = RGB[:, [0, 2]]
# 将 RGB 转换为 HSV
HSV = rgb_to_hsv(RGB.reshape(RGB.shape[0], -1, 3) / 255)
HSV = HSV.reshape(RGB.shape[0], 3)
# 提取色相(Hue)值
hue = HSV[:, 0] * 360
# 提取标签列
labels = data[:, -1]
# 创建普通贝叶斯分类器
norm_bayes = ml.NormalBayesClassifier_create()
# 使用 Hue 值训练分类器
norm_bayes.train(hue.astype(float32), ml.ROW_SAMPLE, labels)
说明 1:
OpenCV 提供了 cvtColor 方法用于图像颜色空间转换,但该方法要求输入图像保持原始三维形状。
而 Matplotlib 的 rgb_to_hsv 函数可接受形如 (…, 3) 的 NumPy 数组输入,且像素值需归一化至 [0,1]。
由于本数据集中的样本是独立像素点(非标准图像结构),因此此处使用 rgb_to_hsv 更合适。
说明 2:
普通贝叶斯分类器假设输入数据符合高斯分布。这不是严格要求,但若数据分布偏离高斯分布,模型性能可能下降。
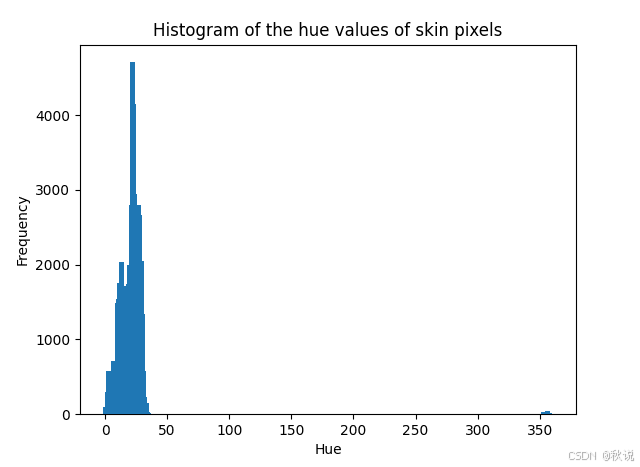
可以通过绘制直方图来检查数据分布。例如,对于皮肤像素的色相(Hue)值,其分布可大致由高斯曲线拟合。
from numpy import histogram
from matplotlib.pyplot import bar, title, xlabel, ylabel, show
# 提取皮肤类别对应的色相值
skin = hue[labels == 1]
# 计算直方图
hist, bin_edges = histogram(skin, range=[0, 360], bins=360)
# 绘制皮肤像素的色相直方图
bar(bin_edges[:-1], hist, width=4)
xlabel('Hue')
ylabel('Frequency')
title('Histogram of the hue values of skin pixels')
show()
当普通贝叶斯分类器训练完成后,可以在图像上进行测试。例如,使用一张人脸图片作为输入:
from cv2 import imread
from matplotlib.pyplot import show, imshow
face_img = imread("Images/face.jpg")
face_BGR = face_img.reshape(-1, 3)
face_RGB = face_BGR.copy()
face_RGB[:, [2, 0]] = face_RGB[:, [0, 2]]
face_HSV = rgb_to_hsv(face_RGB.reshape(face_RGB.shape[0], -1, 3) / 255)
face_HSV = face_HSV.reshape(face_RGB.shape[0], 3)
face_hue = face_HSV[:, 0] * 360
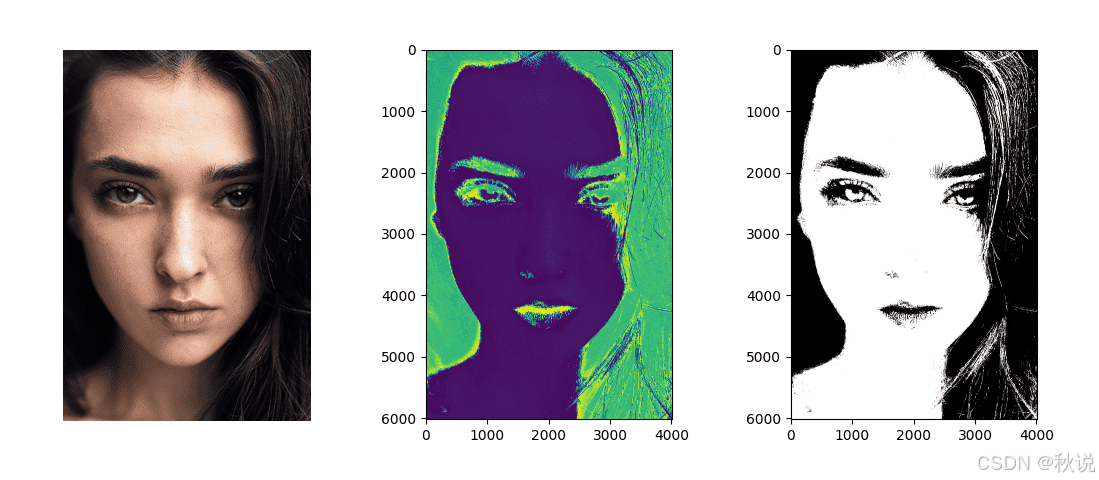
imshow(face_hue.reshape(face_img.shape[0], face_img.shape[1]))
show()
ret, labels_pred, output_probs = norm_bayes.predictProb(face_hue.astype(float32))
skin_mask = labels_pred.reshape(face_img.shape[0], face_img.shape[1], 1) == 1
imshow(skin_mask, cmap='gray')
show()
分类结果中,掩码显示了被识别为皮肤(标签为1)的像素。
从结果可以看出,大部分皮肤像素被正确分类,但也有少量非皮肤区域(如头发)被误标为皮肤。这是因为这些像素的色相值与皮肤区域接近。
此外,使用色相(Hue)进行训练的优势也很明显:即使在原始RGB图像中存在明暗变化,色相值依然保持相对稳定,使得分割效果更为鲁棒。
总结
朴素贝叶斯算法以其高效和易实现的特性,被广泛应用于分类与分割任务中。在 OpenCV 中,其高斯版本——普通贝叶斯分类器(NormalBayesClassifier)提供了一种基于概率模型的分类方式。通过本教程的实践,你可以掌握以下技能:
1.理解贝叶斯定理与朴素假设的数学原理;
2.掌握 OpenCV 中普通贝叶斯分类器的使用方法;
3.使用色相(Hue)特征实现基于像素的图像分割。
这一模型虽然简单,但在面对光照变化、特征独立性假设等复杂场景时,仍展现出较强的鲁棒性,为后续更复杂的图像分类与检测任务奠定了基础。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











