




【精选优质专栏推荐】
- 《AI 技术前沿》 —— 紧跟 AI 最新趋势与应用
- 《网络安全新手快速入门(附漏洞挖掘案例)》 —— 零基础安全入门必看
- 《BurpSuite 入门教程(附实战图文)》 —— 渗透测试必备工具详解
- 《网安渗透工具使用教程(全)》 —— 一站式工具手册
- 《CTF 新手入门实战教程》 —— 从题目讲解到实战技巧
- 《前后端项目开发(新手必知必会)》 —— 实战驱动快速上手
每个专栏均配有案例与图文讲解,循序渐进,适合新手与进阶学习者,欢迎订阅。
前言
过拟合是构建机器学习(ML)模型时最常见的问题之一(甚至可以说是最普遍的问题)。它发生在模型过度学习训练数据中的细节(甚至噪声),而未能抓住能够对未来未见数据进行良好泛化的底层模式。诊断模型是否存在过拟合,对于有效解决该问题以及确保模型在部署到生产环境后能够对新数据保持良好泛化能力至关重要。
本文演示如何在 Python 中诊断和修复过拟合问题。
准备工作
在诊断机器学习模型的过拟合问题之前,首先需要准备训练数据。我们先导入所需的包,并生成一个容易发生过拟合的合成数据集,随后在该数据集上训练回归模型。
导入所需包:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
生成数据集(数据主要遵循正弦曲线规律,并加入一些噪声):
def generate_data(n_samples=20, noise=0.2):
np.random.seed(42)
X = np.linspace(-3, 3, n_samples).reshape(-1, 1)
y = np.sin(X) + noise * np.random.randn(n_samples, 1)
return X, y
X, y = generate_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
这段代码创建了一个小样本数据集,其中训练集和测试集比例为 7:3。
诊断过拟合
诊断过拟合常用两种方法:
1.可视化预测与真实数据的对比
对于低维数据,可以通过绘图观察模型输出与输入的关系,从而判断模型是否仅过度拟合训练数据,而未能捕捉到具有更好泛化能力的底层模式。
2.比较训练集与测试/验证集的性能差异
对于高维、难以可视化的模型,可以检查训练集和测试/验证集的准确率或误差差异。如果训练性能明显优于测试性能,则强烈提示存在过拟合。
在本例中,我们将训练一个低复杂度的多项式回归模型,拟合之前生成的低维随机数据集。
下面定义一个函数,用于训练多项式回归模型并可视化其拟合效果,同时显示训练集和测试集数据,以便诊断过拟合情况:
def train_and_view_model(degree):
model = make_pipeline(PolynomialFeatures(degree), LinearRegression())
model.fit(X_train, y_train)
X_plot = np.linspace(-3, 3, 100).reshape(-1, 1)
y_pred = model.predict(X_plot)
plt.scatter(X_train, y_train, color='blue', label='Train data')
plt.scatter(X_test, y_test, color='red', label='Test data')
plt.plot(X_plot, y_pred, color='green', label=f'Poly Degree {degree}')
plt.legend()
plt.title(f'Polynomial Regression (Degree {degree})')
plt.show()
train_error = mean_squared_error(y_train, model.predict(X_train))
test_error = mean_squared_error(y_test, model.predict(X_test))
print(f'Degree {degree}: Train MSE = {train_error:.4f}, Test MSE = {test_error:.4f}')
return train_error, test_error
重新划分训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
调用该函数,训练并可视化一个多项式回归模型,设置多项式阶数为 10:
overfit_degree = 10
train_and_view_model(overfit_degree)
通常,多项式阶数越高,曲线越复杂,对训练数据的拟合越紧密,但同时更容易导致过拟合,并可能使模型曲线呈现不可预测的模式。
执行后将得到训练集、测试集与模型拟合曲线的可视化图:
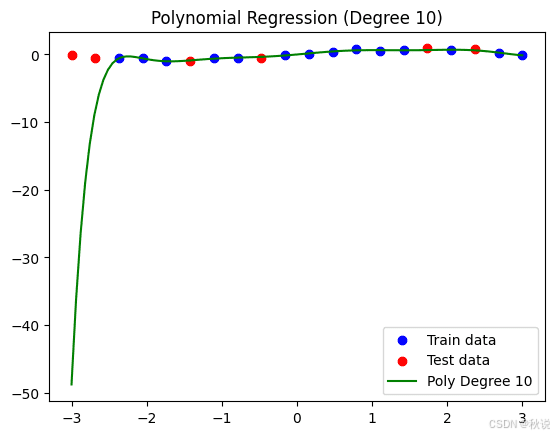
需要注意的是,我们之前定义的自定义函数也会打印训练集和测试集的误差,从而提供另一种诊断过拟合的方法。在该模型中,训练集的均方误差(MSE)为 0.0052,而测试集的误差高达 406.1920。这主要是由于回归曲线左侧出现了剧烈的变化,导致模型在测试数据上的表现很差。
修复过拟合
在本例中,我们可以采用一个简单但常用且有效的策略来修复过拟合:简化模型。对于多项式回归模型,这意味着降低多项式的阶数。
例如,将阶数降低到 3:
reduced_degree = 3
train_and_view_model(reduced_degree)
执行后,将得到新的可视化结果。可以看到,模型曲线更加平滑,对训练数据的拟合不再过度,同时在测试数据上的表现也更好,从而降低了过拟合的风险:
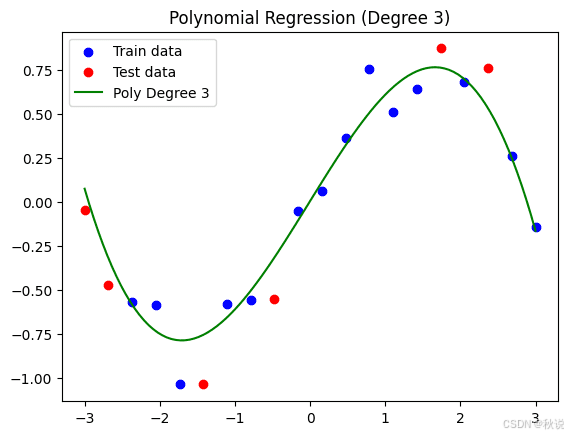
虽然这条曲线对训练集的整体拟合不如之前的模型紧密,但在一定程度上,我们已经克服了过拟合问题,从而得到一个可能对未来不同数据具有更好泛化能力的模型。新的训练集 MSE 为 0.0139,而测试集 MSE 为 0.0394。虽然训练误差与测试误差仍存在差异,但差距明显缩小,这表明该模型具有更好的泛化能力。
总结
本文展示了在 Python 中训练经典机器学习模型时,发现并解决过拟合问题的实际操作步骤。具体而言,我们演示了如何在多项式回归模型中识别并修复过拟合:通过可视化模型与数据、计算训练集和测试集误差,以及简化模型以提升其泛化能力。



















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











