




原创文章,禁止转载。
判断题
1、( x )深度优先搜索具有最优性,故适合于求解大规模搜索问题。
2、( x ){P(x,f(x)),P(y,y)}可合一。
3、( √ )产生式系统推理过程中有多个候选规则时,用冲突消解策略处理。
4、( x )A*算法的效率必优于非 A*的启发式搜索算法。
5、( √ )在不确定推理过程中,当不同的规则指向同一结论时,可用结论合成算法求出最终的结果。
6、( √ )与或图的搜索过程是通过对局部图的评价来选择待扩展的节点。
7、( √ )深度优先搜索以堆栈方式对生成的节点进行排序。
8、( √ )P(f(c),x,a),P(z,n,b)不是可合一的,因为a !=b。
9、( x )在谓词逻辑归结法中,两个置换的合成满足交换律,即λºθ=θºλ。
10、( √ )动态规划算法(h(n)=0)是 A 算法的一个特例且是可纳的。
11、( √ ) 如果 A*算法的启发函数 h(n)满足单调限制条件,则一定可以避免重复扩展结点。
12、( x )对博弈搜索中的极小极大算法采用α-β剪枝策略后得到的结论未必与原来的相同。
13、( x )任何一个谓词公式都可化为与之对应的 Skolem 标准型,且该标准型是唯一的。
14、( √ )P(y,y,B)和P(z,x,z)是可合一的。
15、( √ )一般图搜索过程中,目标节点出现在 OPEN 表的首位时,即表明找到了最优解,搜索过程成功退出。
16、( √ )P(g(f(v)),g(u))和P(y,y)可合一。
17、( √ )框架表示法擅长表达结构化知识。
18、( x )A*算法的优点之一是不会重复扩展一个节点,故其效率较高。
19、( x )在确定性方法中,结论B的更新值有2个来源CF1(B)>0和CF2(B)>0,则合成后B的最终更新值不小于Max{CF1(B),CF2(B)}
20、( √ )与或图的搜索过程是通过对局部图的评价来选择待扩展的节点。
21、( √ ) 编译原理不是人工智能的研究领域。
22、( √ )人工智能研究领域包括但不限于机器证明、模式识别、人工生命。
23、( √ )神经网络研究属于联结主义学派。
注:符号主义基于物理符号系统来模拟人脑功能;联结主义基于神经元及神经元之间的网络联结机制来模拟人脑功能;行为主义基于控制论和“感知-动作”型控制系统来模拟人脑功能。
24、( √ )已知初始问题的描述,通过一系列变换把此问题最终变为一个子问题集合;这些子问题的解可以直接得到,从而解决了初始问题。这种知识表示法称为问题归约法。
25、( √ )在公式中∀y∃xp(x,y)),存在量词是在全称量词的辖域内,我们允许所存在的x可能依赖于y值。令这种依赖关系明显地由函数所定义,它把每个y值映射到存在的那个x。这种函数叫做Skolem函数。
26、( √ )用户不是专家系统的组成部分。
注:专家系统的组成部分为:综合数据库、推理机、知识库。
27、( √ )人工智能是一门综合性的交叉学科和边缘学科。
28、( √ )归结法中,可以通过修改证明树的方法得到问题的解答。
29、( √ )产生式系统推理过程中有多个候选规则时,用冲突消解策略处理。
30、( x )对于一个有限状态空间搜索问题,迭代深入深度优先搜索算法一定可以找到从初始状态到目标状态的最小耗散路径。
31、( √ )双人零和博弈问题中的极小极大搜索算法与α-β剪枝搜索算法搜索得到的当前节点的下一步走法一定相同。
32、( x )广度优先搜索具有完备性和最优性,因此适合于求解大规模搜索问题。
33、( √ )A算法求解一个搜索问题时,分别使用h1(n)和h2(n)作为启发函数,其中 h1(n)<h2(n),则采用h2(n)扩展的节点数(不计重复扩展)一定不多于采用h1(n)扩展的节点数。
34、( √ )与或图的搜索过程是通过对局部图的评价来选择待扩展的节点。
35、( √ )在确定性方法中,结论B的更新值有2个来源 CF1(B)和 CF2(B),则B的最终更新值介于 CF1(B)和 CF2(B)之间。
36、( x )A*算法的优点之一是其效率必优于非 A*的启发式搜索算法。
37、( √ )产生式系统经常用于处理自然语言理解的问题。
38、( √ ){P(x,f(x)),P(y,y)}不可合一。
39、( x )一般图搜索过程中,目标节点第一次出现在OPEN 表中时,即表明找到了最优解,搜索过程成功退出。
40、

41、( √ )A<->B等价于(A∧B)V(~A∧~B)
填空题
1、人工智能三大学派是符号主义,联结主义和行为主义。
2、在知识表示方法中,与谓词逻辑表示为ISA(LIMING,MAN)等效的语义网络形式为:
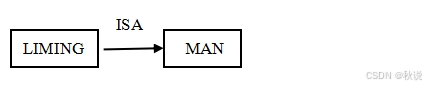
3、状态空间表示法的两个基本概念是状态和操作符。
4、产生式系统的组成:一个总数据库、一套规则、一个控制策略。
5、ANN的中文意义是人工神经元网络。
6、反向传播(back-propagation,BP)算法过程是:从输出节点开始,将误差信号沿原来的连接通路返回,通过修改各层神经元的连接权值,使误差信号减至最小。
7、子句~PvQ和P经过消解以后,得到Q。
8、消解反演证明定理时,若当前归结式是空子句,则定理得证;反演归结(消解)证明定理时,若当前归结式是空子句时,则定理得证。
9、基于规则的正向演绎系统,其规则形式为L->W或L1vL2->W,其中前项要满足的条件是L为单文字。
10、语义网络下的推理是通过继承和匹配实现的。
11、图灵被称为人工智能之父,他曾提出一个机器智能的测试模型。
12、进化策略是在父矢量xi,i=1,2…p中,通过加入一个零均方差的高斯随机变量以及预先选择x的标准偏差来产生子代矢量x。
13、在图搜索中,选择最有希望的节点作为下一个要扩展的节点,这种搜索方法叫做有序搜索。
14、BP网络属于反馈网络。
15、使用一组槽来描述事件的发生序列,这种知识表示法叫做剧本表示法。
16、产生式系统的推理包括正向推理、逆向推理及双向推理,不包括简单推理。
17、启发式搜索是寻求问题满意解的一种方法。
18、语义网络表达知识时,有向弧AKO链、ISA链表达节点知识的继承性。
19、有师学习能够根据期望的和实际的网络输出之间的差来调整神经元之间连接的强度或权。
20、遗传算法、进化编程、进化策略属于进化计算,但认知机不属于进化计算。
21、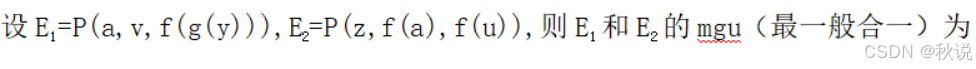 解: 用a替换z,把f(a)替换为v,用g(y)替换u(因为u是变量,g(y)是常量),故最一般合一为:{a/z , f(a)/v , g(y)/u}
解: 用a替换z,把f(a)替换为v,用g(y)替换u(因为u是变量,g(y)是常量),故最一般合一为:{a/z , f(a)/v , g(y)/u}
22、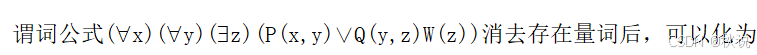
答:

23、在遗传算法中,变量x的定义域为 [-2,5],要求其精度为10^-6,现用二进制进行编码,则码长为23。
解:

24、人工智能的含义最早由一位科学家于1950年提出,并且同时提出一个机器智能的测试模型,这个科学家是图灵。
25、A∧(A∨B)=A 称为吸收律,~(A∧B)=~A∨~B称为摩根律。
26、如果问题存在最优解,则下面几种搜索算法中,( A )必然可以得到该最优解,( D )可以认为是“智能程度相对比较高”的算法。
A.广度优先搜索;B.深度优先搜索;C.有界深度优先搜索;D.启发式搜索
27、要想让机器具有智能,必须让机器具有知识。因此,在人工智能中有一个研究领域,主要研究计算机如何自动获取知识和技能,实现自我完善,这门研究分支学科称为机器学习。
28、
29、从已知事实出发,通过规则库求得结论的产生式系统的推理方式是正向推理。
30、人工智能的英文全称是Artificial Intelligence,缩写为AI。
31、在谓词公式中,紧接于量词之后,被量词作用的谓词公式称为该量词的辖域,而在一个量词的辖域中与该量词的指导变元相同的变元称为约束变元,其他变元称为自由变元。
32、几种常用的归结策略:删除策略、支持集策略、线形归结策略、输入归结策略、单元归结策略。
33、在诸如走迷宫、下棋、八数码游戏等游戏中,常用到的一种人工智能的核心技术称为图搜索技术,解这类问题时,常把在迷宫的位置、棋的布局、八数码所排成的形势用图来表示,这种图称为状态空间图(或状态图)。
34、在启发式搜索当中,通常用启发函数来表示启发性信息。
35、二人博弈问题中,最常用的一种分析技术是极大极小分析法,这种方法的思想是先生成一棵博弈树,然后再计算其倒推值。但它的效率较低,因此人们在此基础上,又提出了α-β剪枝技术。
36、某产生式系统中的一条规则:A(x)->B(x),则前件是A(x),后件是B(x)。
37、在框架和语义网络两种知识表示方法中,框架适合于表示结构性强的知识,而语义网络则适合表示一些复杂的关系和联系的知识。面向对象不仅仅是一种知识表示方法,也是一种流行的软件设计和开发技术。
38、写出图中树的结点两个访问序列,要求分别满足以下两个搜索策略:
(1)深度优先搜索;(2)广度优先搜索

答:(1)1、2、5、6、10、11、3、7、12、13、4、8、9
(2)1、2、3、4、5、6、7、8、9、10、11、12、13
39、(A→B)∧A = B,这是假言推理。
40、命题是可以判断真假的陈述句。
41、仅个体变元被量化的谓词称为一阶谓词。
42、最一般合一的英文缩写是MGU。
43、1997年5月,著名的“人机大战”,最终计算机以3.5比2.5的总比分将世界国际象棋棋王卡斯帕罗夫击败,这台计算机被称为深蓝。
44、人工智能系统的知识包含的4个要素为:事实、规则、控制和元知识,不包含关系。
45、或图通常称为状态图。
46、不确定性类型按性质分:随机性,模糊性,不完全性,不一致性。
47、在删除策略归结的过程中删除以下子句:含有纯文字的子句;含有永真式的子句;子句集中被别的子句类含的子句。
48、对证据的可信度CF(A)、CF(A1)、CF(A2)之间,规定如下关系:
CF(~A)=-CF(A)、CF(A1∧A2)=min{CF(A1),CF(A2)}、CF(A1∨A2)=max{CF(A1),CF(A2)}
49、图:指由节点和有向边组成的网络。按连接同一节点的各边的逻辑关系又可分为或图和与或图。
50、合一算法用于:求非空有限具有相同谓词名的原子公式集的最一般合一(MGU)。
51、产生式系统的推理过程中,从可触发规则中选择一个规则来执行,被执行的规则称为被触发规则。
52、P(B|A) 表示在规则A→B中,证据A为真的作用下结论B为真的概率。
53、人工智能的远期目标是制造智能机器,近期目标是实现机器智能。
54、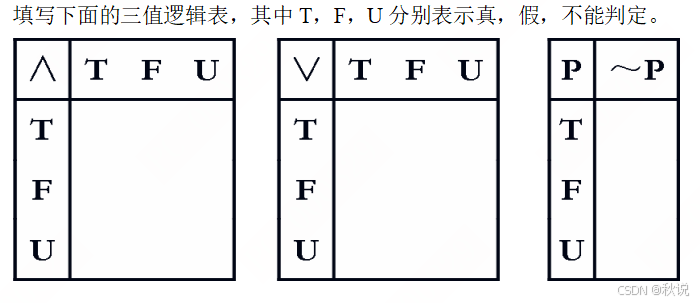
答:
55、人工智能产生于1956年。
56、人工智能的基本技术包括搜索技术、推理技术、知识表示和知识库技术、归纳技术、联想技术。
57、目前所用的知识表示形式有框架、语义网络、面向对象等。
58、产生式系统有三部分组成:综合数据库、知识库和推理机。其中推理可分为正向推理和反向推理。
59、谓词逻辑中,重言式(tautlogy)的值是真。
60、利用归结原理证明定理时,若得到的归结式为空集,则结论成立。
61、若C1=┐P∨Q,C2=P∨┐Q,则C1和C2的归结式R(C1,C2)= ┐P∨P或┐Q∨Q
62、若C1=P(x) ∨Q(x),C2=┐P(a) ∨R(y),则C1和C2的归结式R(C1,C2)= Q(a)∨R(y)。
63、在归结原理中,几种常见的归结策略并且具有完备性的是:删除策略、支持集策略、线性归结策略。
64、C(B|A) 表示在规则A->B中,证据A为真的作用下结论B为真的信度。
65、
66、仅个体变元被量化的谓词称为一阶谓词。
67、所谓不确定性推理就是从不确定性的初始证据出发,通过运用不确定性的知识,最终推出具有一定程度的不确定性但却是合理或者近乎合理的结论的思维过程。
68、合一算法:求非空有限具有相同谓词名的原子公式集的最一般合一。
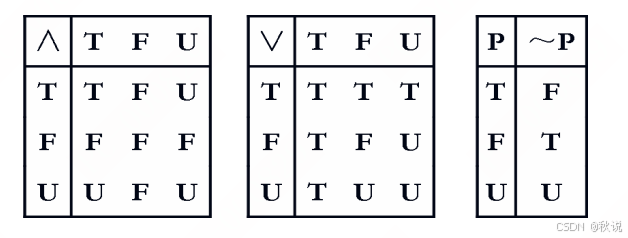
69、补充以下表格
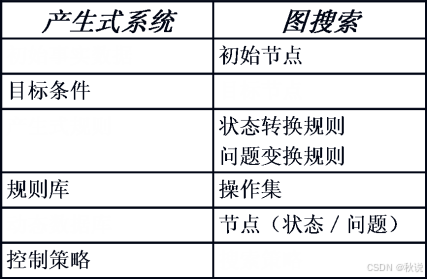
答:
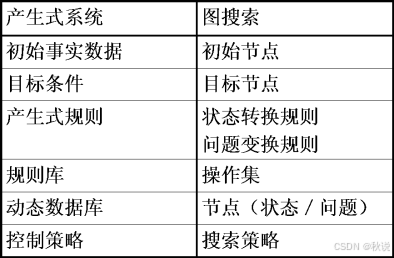
70、开发专家系统所要解决的基本问题有三个,那就是知识的获取、知识的表示和知识的运用,知识表示的方法主要有逻辑表示法(谓词表示法)、框架、产生式和语义网络等,在语义网络表示知识时,所使用的推理方法有AKO和ISA。
语义网络
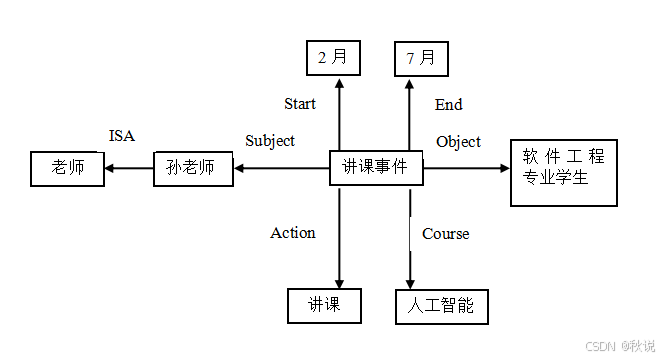
题目一
给出表示包含下面句子含义的语义网络:孙老师从2月至7月给软件工程专业讲授“人工智能”课程。
答:语义网络如图所示。
题目二
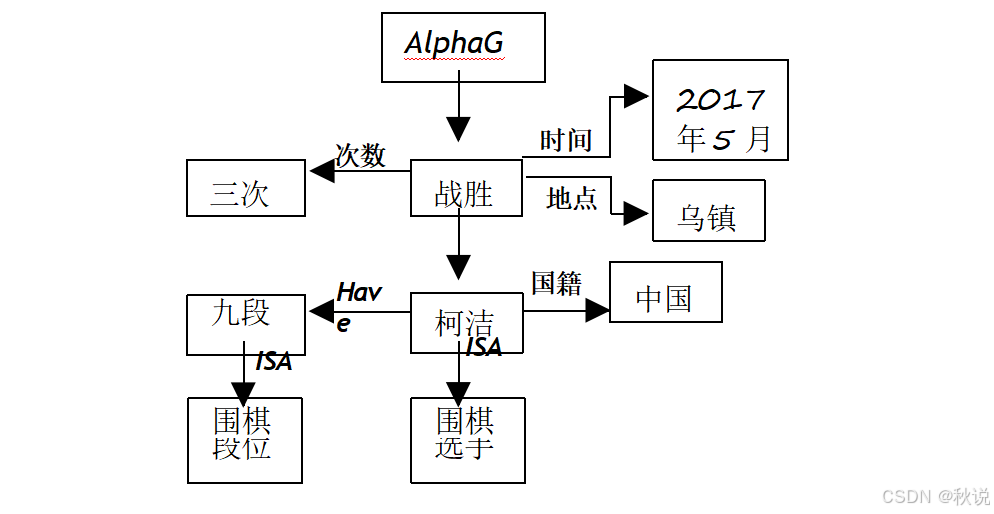
用语义网络结构表达如下信息:2017年5月AlphaGo在乌镇三胜中国九段围棋选手柯洁。
答:语义网络如图所示。
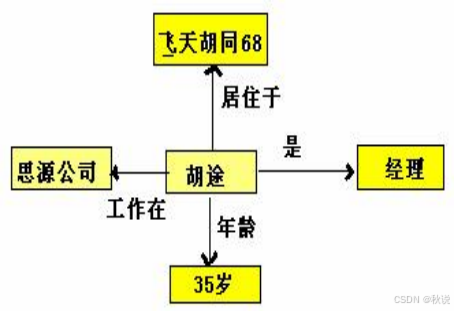
题目三
胡途是思源公司的经理,他35岁,住在飞天胡同68号。
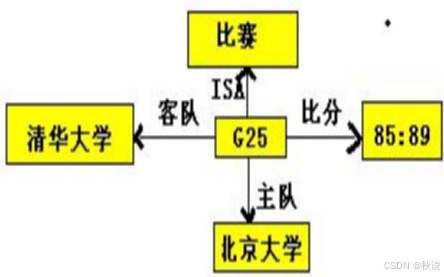
题目四
清华大学与北京大学进行G25篮球比赛,最后以85:89的比分结束。
简答题
题目一
简述简单遗传算法的基本原理。
答: 遗传算法是一种随机搜索算法。该算法将优化问题看作是自然界生物的进化过程。模拟大自然生物进化的遗传规律来达到寻优的目的。
题目二
人工神经网络的构成与特性是什么?
答: 人工神经网络由神经元(信息处理单元)、网络拓扑(神经元连接结构)和学习算法(权重调整机制)三部分组成。
特征:
(1)能较好的模拟人的形象思维。
(2)具有大规模并行协同处理能力。
(3)具有较强的学习能力。
(4)具有较强的容错能力和联想能力。
(5)是一个大规模自组织、自适应的非线性动力系统。
题目三
人工智能的主要研究和应用领域有哪些?(至少列出7个)哪些是新的研究热点?(至少列出3个)
答: 主要研究和应用领域有:1.自然语言处理(NLP);2.人工神经网络(ANN);3.数据库智能检索;4.智能控制;5.专家系统;6.知识发现与数据挖掘(KDD);7.机器人学;8.模式识别;9.博弈与强化学习;10.智能调度与组合优化。
新的研究热点有:1.大模型与生成式人工智能:如 ChatGPT 等语言生成模型的研发与应用;2.多模态人工智能:结合语言、图像、视频等多种数据模态的统一建模;3.可解释性人工智能(XAI):让 AI 系统的决策过程透明化,提高信任度和可用性。
题目四
什么是图灵测试?其测试原则和目的是什么?
答: 图灵测试,也称图灵实验,是由图灵提出的一种判断机器系统是否具有人的智能的方法。
测试原则:如果机器在与人隔离的房间回答人提出的问题,且人无法判断回答问题的是机器还是人时,则应该认为机器已经具备人的智能。
图灵测试的目的在于判断机器是否达到了人工智能或人类感知的水平。然而,即使机器通过了图灵测试,也无法真正说明机器拥有像人一样的思维和意识。
图灵测试的具体过程如下:
1.设有一位测试者(人类)与两位被测试者(一个是机器,另一个是人类)进行隔离的对话。
2.测试者通过打字或其他文字交流方式提出问题,与两位被测试者交互。
3.测试者的任务是判断哪一方是机器,哪一方是人类。
4.如果机器的回答能够让测试者无法区分它和人类,则认为该机器通过了图灵测试。
或者按如下内容回答:
所谓“图灵实验”,是为了判断一台机器是否具备智能的实验。实验由三个封闭的房间组成,分别放置主持人、参与人和机器。主持人向参与人和机器提问,通过提问的结果来判断谁是人,谁是机器。如果主持人无法判断谁是人,谁是机器,则这台机器具备智能,即所谓的“智能机器”。
题目五
主观 Bayes 方法中,规则的表示形式为:If A(LS,LN) then B(P(B)),请解释 LS 和 LN 的含义。
答:
LS体现规则成立的充分性,表示A真时对B的影响;
LN体现规则成立的必要性,表征的是A不发生时对B发生的影响程度。
题目六
设有下列语句,分别用相应的谓词公式把它们表示出来:
(1)并不是每一个人都想出国留学;(2)欲穷千里目,更上一层楼。
答: 设A(x):想出国留学;P(x):欲穷千里目;Q(x):更上一层楼。
则(1)可表示为∃ x( ¬A(x) )
则(2)可表示为∀x( Q(x) -> P(x) )
题目七
什么是产生式规则?产生式规则的语义是什么?
答: 产生式规则基本形式:P→Q 或者 IF P THEN Q。其中P是产生式的前提(前件),用于指出该产生式是否可用的条件;Q是一组结论或操作(后件),用于指出当前提 P所指示的条件满足时,应该得出的结论或应该执行的操作。
产生式规则的语义:如果前提P被满足,则可推出结论Q或执行Q所规定的操作
题目八
谓词公式G通过8个步骤所得的子句集合S,称为G的子句集。请写出这8个步骤。
答:
(1)消去蕴含式→和等价式<->
(2)缩小否定词的作用范围,直到其作用于原子公式
(3)适当改名,使量词间不含同名指导变元和约束变元
(4)消去存在量词(形成Skolem标准型)
(5)消去所有全称量词
(6)化成合取范式
(7)适当改名,使子句间无同名变元
(8)消去合取词∧,用逗号代替,以子句为元素组成一个集合S
题目九
已知S={P(f(x),y,g(y)),P(f(x),z,g(x))},z为常数,求MGU。

题目十
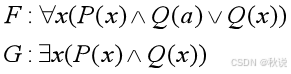
证明G是否是F的逻辑结论(注:合取的优先级高于析取)
答:

题目十一
剪枝方法只是极小极大方法的一种近似,剪枝可能会遗漏掉最佳走步。这种说法是否正确?
答: 不正确。剪枝方法利用已经搜索的信息,剪掉哪些对于搜索最佳走步没有意义的分枝,其找到的最佳走步与极小极大方法找到的结果是一样的,而且搜索效率有很大提高。
题目十二
解释下列模糊性知识:
1、(张三,体型,(胖,0.9))。
2、(患者,症状,(头疼,0.95))∧(患者,症状,(发烧,1.1))→(患者,疾病,(感冒,1.2))
答:
(1)表示命题:张三比较胖。
(2)解释为:如果患者有些头疼并且发高烧,则他患了重感冒。
题目十三
产生式系统由哪些部分组成?
答:
产生式系统由三要素组成:综合数据库;一组产生式规则(或者规则集);一个控制系统(或者控制策略)。
或回答如下:
1)产生式规则库:描述相应领域知识的产生式规则集。
2)数据库:(事实的集合)存放问题求解过程中当前信息的数据结构(初始事实、外部数据库输入的事实、中间结果事实和最后结果事实)
3)推理机:(控制系统)是一个程序,控制协调规则库与数据库的运行,包含推理方式和控制策略。
题目十四
深度优先方法的特点是什么?
答:
(1)属于图搜索;(2)是一个通用的搜索方法;(3)如果深度限制不合适,有可能找不到问题的解;(4)不能保证找到最优解。
题目十五
什么是置换?置换是可交换的吗?
答:
通常用有序对的集合s={t1/v1,t2/v2,…,tn/vn}来表示任一置换,置换集的元素ti/vi的含义是表达式中的变量vi处处以项ti来替换,用s对表达式E作置换后的例简记为Es。
一般来说,置换是不可交换的,即两个置换合成的结果与置换使用的次序有关。
题目十六
试实现一个“大学教师”的框架,大学教师类属于教师,包括以下属性:学历(学士、硕士、博士)、专业(计算机、电子、自动化、……)、职称(助教、讲师、副教授、教授)
答:
框架名:<大学教师>
类属:<教师>
学历:(学士、硕士、博士)
专业:(计算机、电子、自动化、……)
职称:(助教、讲师、副教授、教授)
题目十七
将命题:“某个学生读过三国演义”分别用谓词公式和语义网络表示
答:
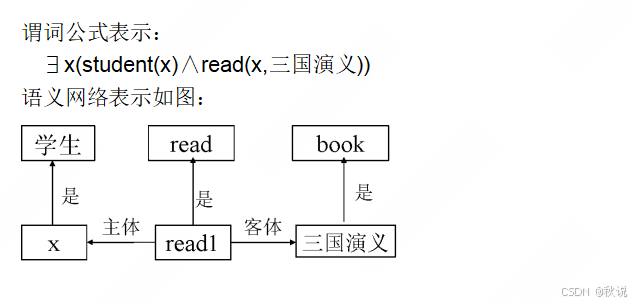
题目十八
α-β剪枝的条件是什么?
答:
α剪枝:若任一极小值层节点的β值小于或等于它任一先辈极大值节点的α值,即α(先辈层)≥β(后继层),则可中止该极小值层中这个MIN节点以下的搜索过程。这个MIN节点最终的倒推值就确定为这个β值。
β剪枝:若任一极大值层节点的α值大于或等于它任一先辈极小值层节点的β值,即α(后继层)≥β(先辈层),则可以中止该极大值层中这个MAX节点以下的搜索过程。这个MAX节点的最终倒推值就确定为这个α值。
题目十九
谓词逻辑形式化该描述:“不存在最大的整数”。
答:
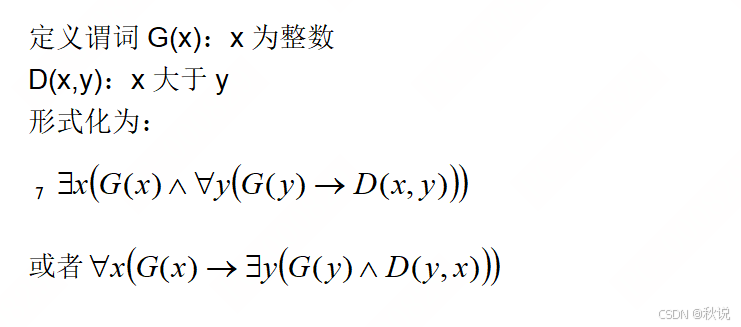
题目二十
专家系统的一般步骤有哪些?专家系统的开发与一般的软件系统开发相比较,有哪些共同点和特点?
答:
(1)专家系统与一般的软件系统开发无异,其开发过程同样要遵循软件工程的步骤和原则,即也要进行系统分析、系统设计等几个阶段的工作。
(2)但由于它是专家系统,而不是一般的软件系统,所以,又有其独特的地方,主要包括以下几个步骤:
- 系统总体分析与设计;
- 知识获取;
- 知识表示与知识描述语言设计;
- 知识库设计、知识库管理系统设计;
- 推理机与解释模块设计;
- 总控与界面设计
- 编程与调试
- 测试与评价
- 运行与维护
(3)可以看出它有如下特点:知识获取和知识表示设计是一切工作的起点;知识表示与知识描述语言确定后,其他设计可同时进行。
题目二十一
给1~9九个数字排一个序列,使得该序列的前n(n=1,…,9) 个数字组成的整数能被n整除。
(1)哪些知识可以帮助该问题的求解。
(2)用产生式系统描述该问题。
答:
(1)序列中,偶数在偶数位置,奇数在奇数位置;
(2)综合数据库:用一个1到9的序列表示:N = {x},其中x为1到9的数字之一。
规则集:
r1: IF len(N)=4 THEN {x}∪{5}
r2: IF len(N)为偶数and n=In(1, 3, 7, 9) THEN {x}∪{n}
r3: IF len(N)为奇数and n=In(2, 4, 6, 8) THEN {x}∪{n}
其中len(N)为求序列的长度,In(a, b, c, d)为取a、b、c、d之一。
初始状态:{}
结束条件:得到的序列N前i个数组成的整数能被i整除。
题目二十二
什么是人工智能?人工智能与计算机程序的区别?
答:
人工智能是研究如何制造人造的智能机器或智能系统来模拟人类智能活动的能力以延伸人类智能的科学,它与计算机程序的区别是:
1、AI研究的是符号表示的知识而不是数值数据为研究对象
2、AI采用启发式搜索方法而不是普通的算法
3、控制结构与知识是分离的
4、允许出现不正确的答案
题目二十三
人工智能主要有哪几种研究途径和技术方法,简单说明。
答:
(1)符号智能,是主要以符号知识为基础,通过符号推理进行问题求解而实现的智能,主要包括知识工程和符号处理技术;
(2)计算智能,是以数据计算为基础,通过数值计算进行问题求解而实现的智能,包括人工神经网络,进化计算,模糊技术等。
题目二十四
化下列逻辑表达式为不含存在量词的前束范式
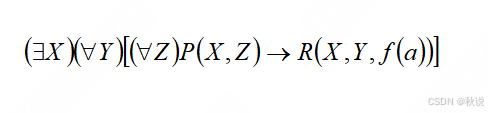
答:
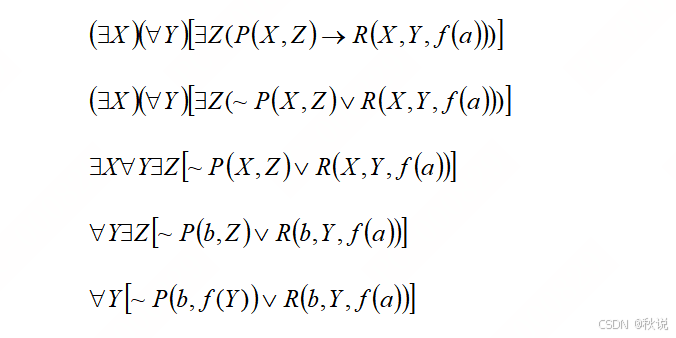
题目二十五
求下列谓词公式的子句集
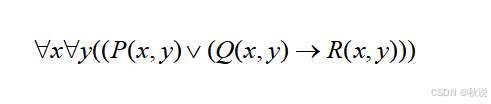
答:
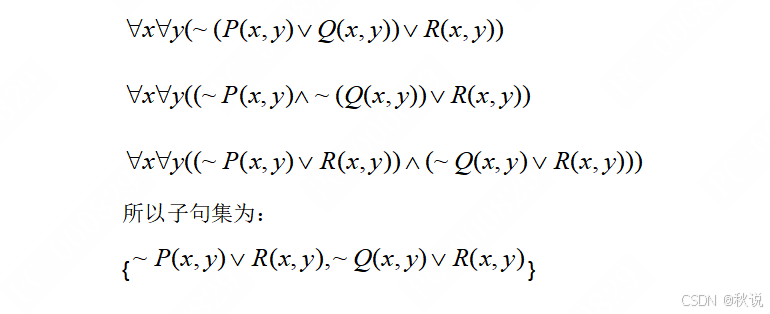
题目二十六
[虚拟社3月16日电]昨日 ,沙尘暴袭击韩国汉城 ,机场与高速公路被迫关闭,造成的损失不详 。韩国官方示,如果需要直接损失情况,可待一周后的官方公布 。此次沙尘暴起因专家认为是由于某地过分垦牧破坏植被所致。
提示:分析概括用下划线标出的要点,经过概念化形成槽(Slot)并拟出槽的名称,选填侧面(face)值。侧面包含“值(value)”,“默认值(default)”,“如果需要值(if-needed)”,“如果附加值(if-added)”几个方面,用不到的侧面值可删除。

答:
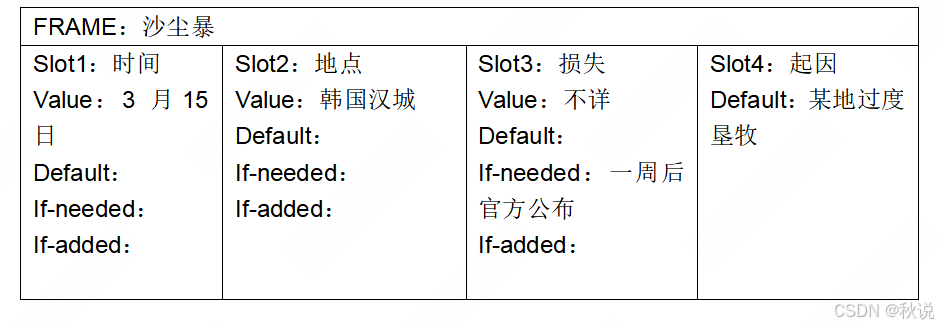
题目二十七

答:

题目二十八

答:
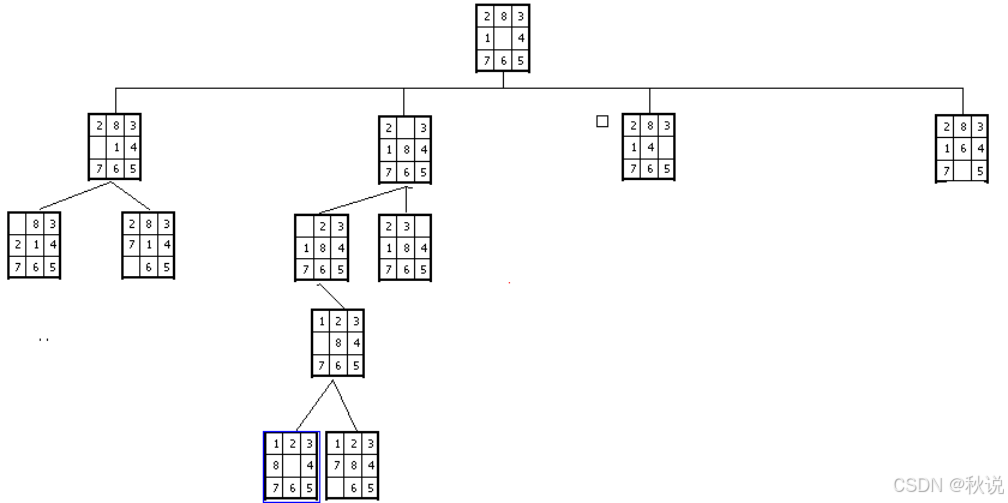
题目二十九
已知确定性方法的规则A→B,有CF(B,A)=0.6,CF(B)=-0.5,CF(A)=0.2,写出CF(B|A)的计算公式并求其值。
答: 由于CF(A)=0.2<1,所以使用如下公式

又由于CF(B)<0,CF(A)xCF(B,A)>0,所以用如下公式:
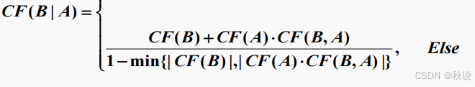
求得CF(B|A)=-0.43
题目三十
某识别框架U={x,y,z},基本概率分配函数为:M({x})=0.3,M({x,z})=0.2,M(U)=0.5,填写下表:
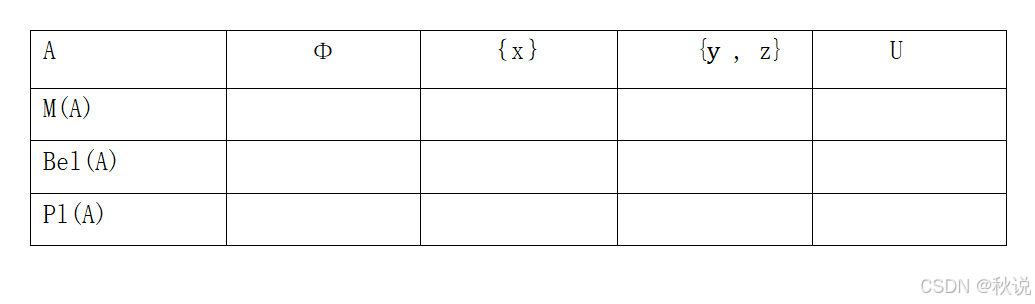

题目三十一
人工智能围绕着知识的表示、获取和利用三个方面展开研究,请解释它们的具体含义并各给出知识的表示、获取和利用的一种相关方法。
答:
人工智能中的知识表示是将现实世界的事实、规律和信息以形式化的方式存储在计算机中,使其能够理解和处理这些信息。知识表示的形式多种多样,常见的方法包括语义网络,它通过节点表示概念或实体,用边描述它们之间的关系。例如,可以用语义网络表示“猫是一种动物,动物有毛发”,其中“猫”和“动物”是节点,“是一种”和“有”是边,从而使机器能够通过这种结构化的表示方式处理知识。
知识的获取是指通过多种手段从数据或专家经验中提取有用的信息,并转化为机器可以处理的形式。这一过程可以通过手工编码规则、自动学习算法或自然语言处理技术完成。其中,机器学习是一种常见的知识获取方法,通过对大量标注数据的训练,模型可以自动提取规律并生成知识。例如,使用监督学习训练一个分类器,让它学会区分图片中的“猫”和“狗”,就是从数据中获取知识的过程。
知识的利用则是将表示和获取的知识应用到实际问题中,进行推理、决策或问题求解。专家系统中的推理引擎是一种典型的知识利用方法,它基于知识库中的规则,通过逻辑推导得出结论。例如,当规则库中包含“如果天冷且下雨,则穿外套”和“如果穿外套,则带雨伞”,推理引擎在收到“天冷且下雨”的输入后,可以推导出“穿外套并带雨伞”的结论,从而实现智能化的决策支持。
题目三十二
写出图对应的式子。
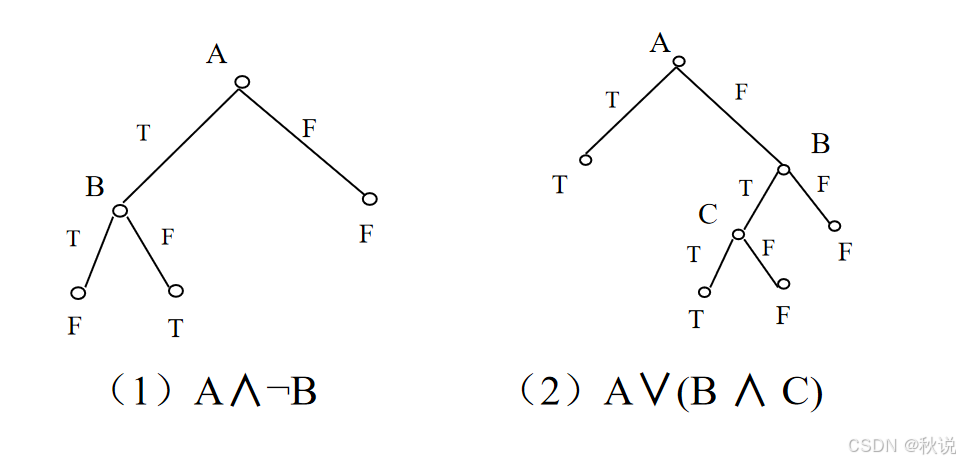
题目三十三
写出以下公式的子句集:

题目三十四

题目三十五


题目三十六


题目三十七

题目三十八
将谓词公式化为子句集:
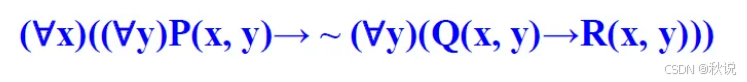
答:

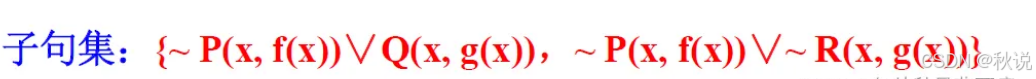
题目三十九

题目四十
从手机中找出5种以上(含)与人工智能相关的应用,并回答这些应用分别与哪种人工智能技术相关。
1、语音助手(如 Siri、Google Assistant)
相关技术:
自然语言处理(NLP):用于理解用户语音命令和生成对话。
语音识别:将语音转换为文本。
语音合成:将文本转换为语音进行响应。
机器学习:个性化推荐和理解用户习惯。
2、地图与导航应用(如 Google Maps、高德地图)
相关技术:
路径规划算法:用于计算最佳路线。
机器学习:分析交通状况并预测拥堵。
计算机视觉:通过 AR 提供实景导航。
强化学习:优化导航和路线规划。
3、社交媒体平台(如抖音、Instagram)
相关技术:
推荐算法:基于用户兴趣推送个性化内容。
计算机视觉:视频识别、内容标注、滤镜应用。
深度学习:内容分类、评论分析、反垃圾内容检测。
4、音乐或视频流媒体应用(如 Spotify、网易云音乐)
相关技术:
推荐系统:个性化推荐歌曲、视频。
深度学习:分析用户行为以优化推荐模型。
自然语言处理:用于处理搜索查询和歌词匹配。
5、电子商务应用(如淘宝、亚马逊)
相关技术:
推荐算法:基于用户购买历史和兴趣推送商品。
自然语言处理:语音购物助手、搜索优化。
计算机视觉:图片搜索功能,通过照片找到相似商品。
6、新闻阅读应用(如今日头条、Flipboard)
相关技术:
推荐系统:基于用户阅读历史和兴趣推荐新闻内容。
自然语言处理(NLP):提取新闻关键信息和自动摘要。
情感分析:分析新闻评论的情感倾向。
题目四十一
1.有界深度(迭代深入)是否每次变更深度时重新从根结点开始搜索?
是的,每次变更深度时,迭代加深深度优先搜索(Iterative Deepening Depth-First Search, IDDFS)都会重新从根结点开始搜索。
这是因为它需要在每次增加搜索深度时,确保完整搜索所有可能路径,直到当前深度限制。
2.迭代深入算法能否从中间某个最接近目标状态的节点继续?
不能。在 IDDFS 中,每次深度限制的递增会重新从根结点开始搜索,而不是从中间节点继续。原因如下:搜索算法必须保证在新的深度限制下探索完整的搜索空间;如果直接从中间节点继续,可能会遗漏从其他路径到达目标状态的可能性。
3.比较迭代深入与广度优先搜索生成节点的次数
迭代加深深度优先搜索(IDDFS):在每次增加深度限制时都会重新探索之前已经生成的节点,因此会重复生成节点。
广度优先搜索(BFS):一次性搜索到目标深度,每个深度的所有节点都需要生成一次。
尽管 IDDFS 在浅层重复生成节点,但实际总生成节点数与 BFS 相差不大,因为浅层节点通常数量较少。IDDFS 的空间复杂度比 BFS 更低,因此适合内存受限的场景。
4.树搜索如何处理重复?
树搜索并不主动检测重复节点,因为它假设搜索的空间是树形结构,节点之间没有交叉或循环。因此:如果搜索空间中存在重复节点,树搜索会多次探索同一个节点;为避免重复节点的问题,可以使用图搜索方法,通过记录访问过的节点状态(通常用一个“已访问集合”)来防止重复探索。
5.深度优先搜索何种情况下出现无穷分支?
深度优先搜索会出现无穷分支的典型情况是:
1、存在无穷状态空间:搜索空间无限,例如在没有限制的整数范围内搜索某个数。
2、没有检测循环:当搜索空间是一个图结构,但没有记录已访问节点时,可能在循环中无限递归。
3、路径过长或无解:在某些问题中,深度优先可能沿着某条路径一直下探,陷入无穷分支,即使目标状态并不存在。示例:某些生成函数不合理,导致状态空间膨胀。
解决办法:限制搜索深度(如使用迭代加深);检测并避免重复节点(如图搜索)。
题目四十二
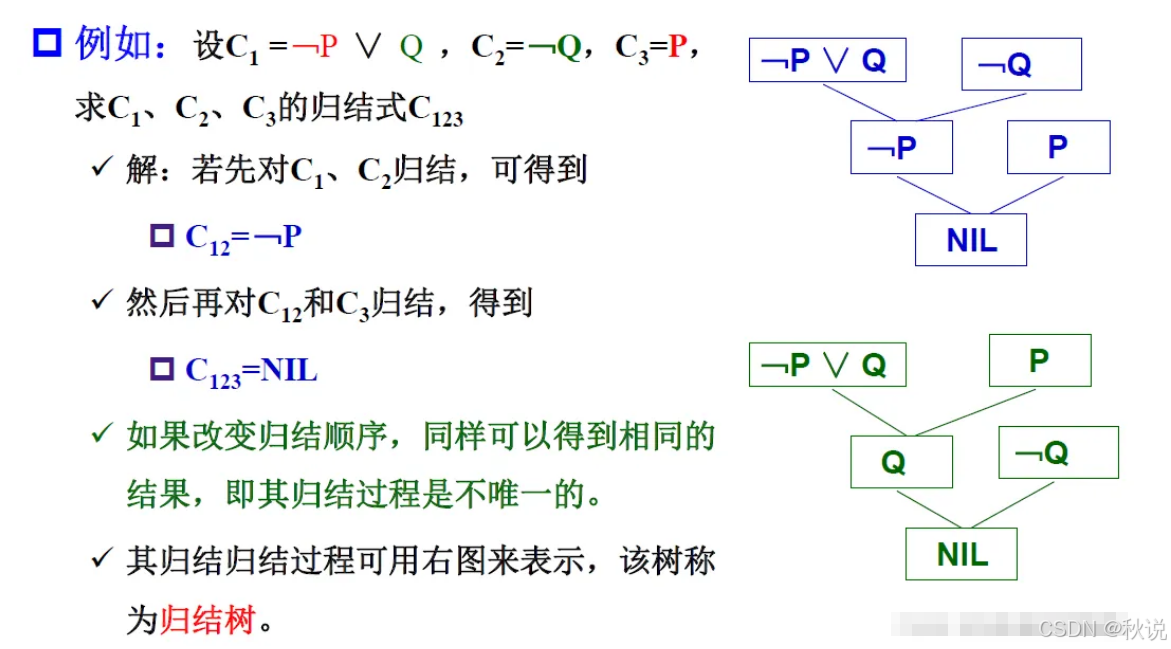
补充OPEN表与CLOSED表:
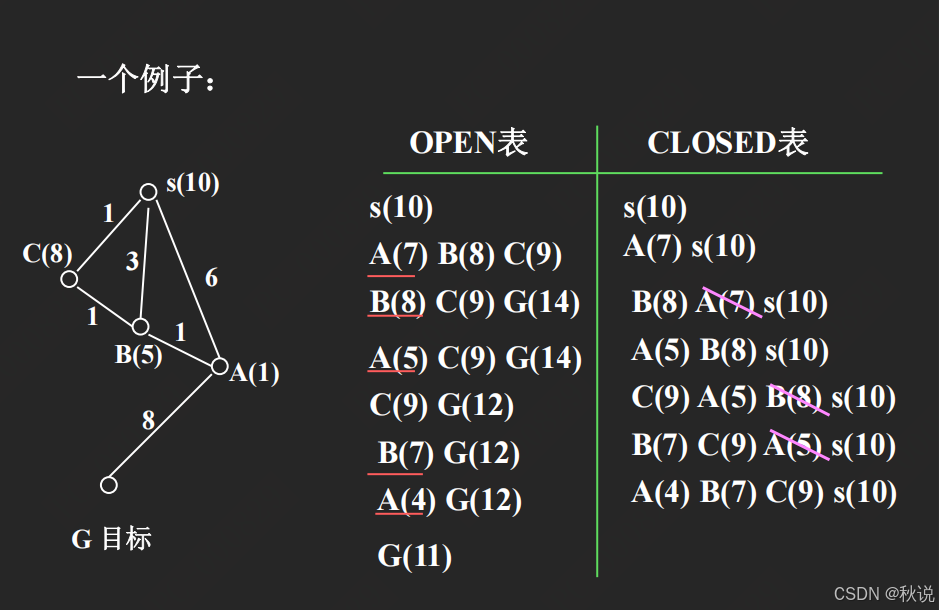
每次都从OPEN表中选择最小的节点进行拓展,但可以看到,一个节点在OPEN表中拓展了多次。
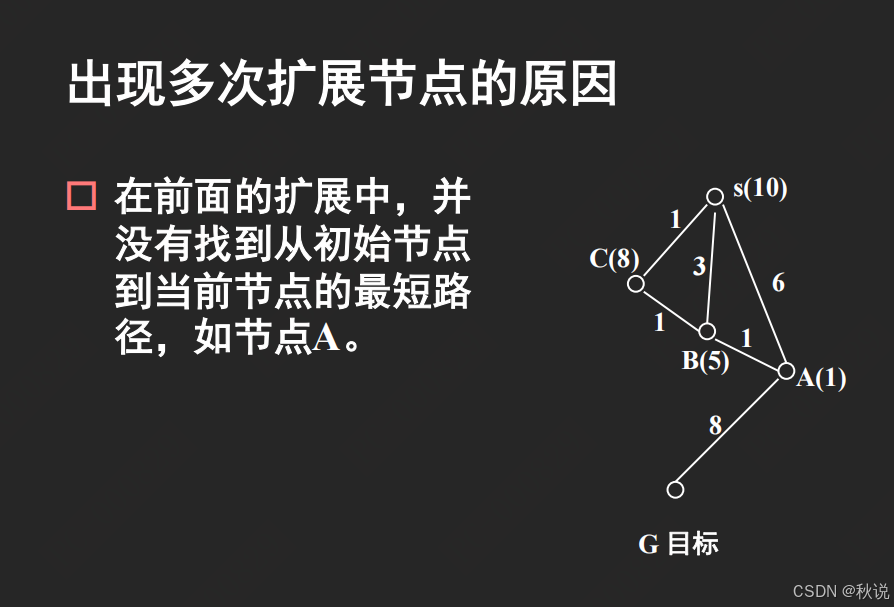
改进措施,每次选择最大的节点进行拓展:
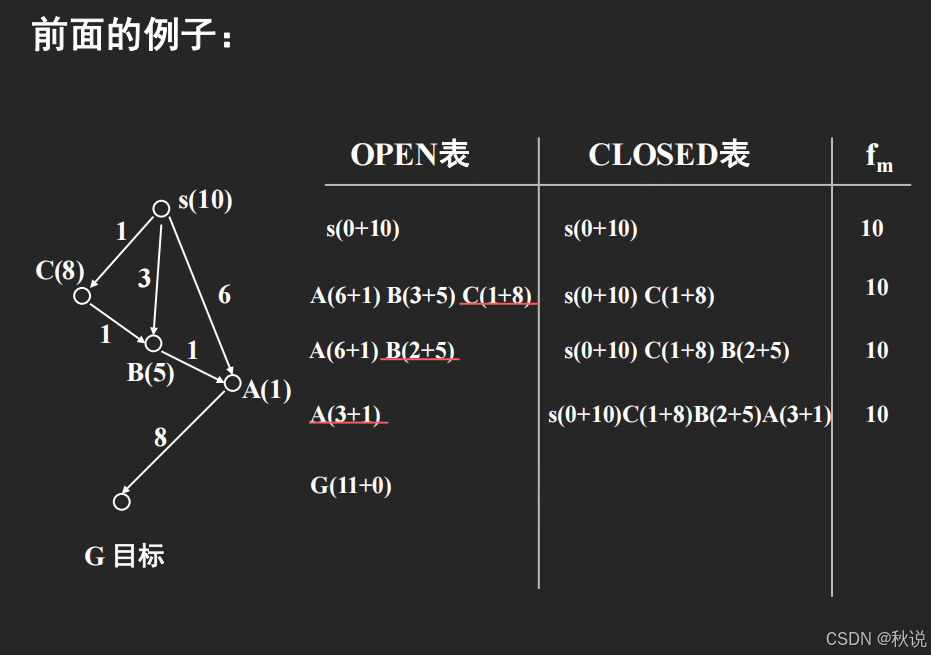
题目四十三
如何在盲目搜索中避免重复状态?对广度和深度优先算法这种策略有何不同?
在盲目搜索中(如广度优先和深度优先),可以通过记录访问过的状态来避免重复状态。通常使用一个"已访问集合"(closed set)来存储所有已经探索过的状态,并在扩展新节点时检查该状态是否已存在。
广度优先搜索(BFS):BFS天然适合使用已访问集合,因为它按照层次扩展节点,每个节点在访问时都能确保它的路径最短。因此,只需在扩展节点时检查是否已访问即可,效率较高。
深度优先搜索(DFS):DFS因其回溯特性,如果没有深度限制,可能会重新访问父节点甚至形成循环。因此,使用已访问集合在 DFS 中更为重要,但可能增加内存开销,尤其在深层递归时。
树与图的区别是什么?其搜索方法有何不同?如何选择?
树是没有环的结构,每个节点仅能由一个父节点到达;图则可能包含环和多条路径通向同一节点。
树搜索:无需记录已访问节点,因为每个节点的状态都是唯一的,无需担心重复访问。
图搜索:需要记录访问过的节点,以避免在环或多条路径上浪费时间重复探索同一状态。
选择方法:
- 如果问题的状态空间是树形(例如分支不重复扩展的问题),可以直接使用树搜索。
- 如果状态空间是图(例如滑块问题、TSP问题),应选择图搜索,避免循环或重复状态。
若干经典搜索问题的最新进展与通用启发函数的构造方法
皇后问题的最新进展包括基于位运算的高效回溯算法和分布式计算在大规模实例中的应用,进一步减少解空间的对称性剪枝技术,以及量子计算在求解此类组合优化问题中的尝试。
滑块问题(8数码问题)近年来在启发式搜索算法上取得进展,尤其是A*算法结合深度学习预测启发式函数的研究,以及基于状态压缩和哈希表的记忆化搜索实现。
TSP问题的研究侧重于基于强化学习和图神经网络的近似算法,以及结合量子退火和混合整数规划的求解方法,同时也有基于元启发式算法的进一步优化。
规划问题的最新进展主要体现在基于PDDL(Planning Domain Definition Language)的通用规划系统开发,深度学习驱动的规划器生成,以及通过强化学习和模拟环境的实时规划优化。
巡游问题的研究涉及结合生成对抗网络(GAN)的路径生成,利用区块链技术优化路径计划中的协作机制,以及动态环境下路径重新规划的高效算法设计。
通用启发函数构造方法:构造启发函数时,需满足可接受性(h(n) ≤ h*(n))和一致性(h(n) ≤ c(n, n’) + h(n’))。通用方法包括:
- 直接基于问题目标状态的几何距离。
- 分解问题为多个子问题,构造子问题的启发式函数并求和。
- 结合领域知识,将问题的复杂性简化为低维估计。
8数码问题更有效的启发式函数有哪些?
8数码问题中,除了曼哈顿距离和错位数,以下启发式函数可提升效率:
1、线性冲突(Linear Conflict):在曼哈顿距离基础上,考虑相邻数码之间的冲突。例如,两个数码在同一行或列且最终位置互相阻碍时,每对冲突增加2的代价。
2、逆序数冲突:统计当前状态中是否存在逆序(两个数码顺序与目标状态相反),以增加额外的估计代价。
这些改进的启发式函数能更准确地评估节点的未来代价,从而减少搜索路径。
一般图搜索、A算法、A*算法的异同
一般图搜索:不使用启发函数,仅依靠队列或堆栈结构展开节点。效率低,但适合全盲搜索。
A算法:引入启发函数 f(n)=g(n)+h(n),其中 g(n) 是已走路径的代价,h(n) 是估计的未来代价。适合目标明确的问题。
A*:A 的改进版本,要求启发函数满足可接受性和一致性,确保算法的完备性和最优性。A* 更高效,但对启发函数依赖更大。
评价f(n)=g(n)+h(n)中右边两项各自引导的作用
g(n):引导算法考虑当前已走的路径代价,保证实际成本最小化。
h(n):引导算法朝目标状态靠近,减少搜索空间的扩展。
合理平衡 g(n) 和 h(n) 是设计高效启发函数的关键。
h(n)未知,如何设计满足 A* 算法的 h(n)?
当 h ∗ (n)(到目标的实际代价)未知时,可以设计满足可接受性的 h(n):
- 使用简单的距离估计(如几何距离或曼哈顿距离)。
- 使用问题的松弛版本(relaxed problem)作为估计值,例如在滑块问题中允许数码直接移动到目标位置的代价。
- 利用问题分解,将整体问题拆分为多个子问题并估算各子问题的最优解。
A*算法优缺点与改进策略
优点:
完备性:保证能找到解。
最优性:保证找到代价最小的解。
适用范围广:适合多数目标导向的搜索问题。
缺点:
空间复杂度高:需要存储所有已生成节点。
依赖启发函数:启发函数的质量直接影响效率。
改进策略:
使用外存(External Memory A*)存储部分节点,减小内存压力。
动态调整启发函数的权重,使搜索更灵活。
引入剪枝策略(如 IDA*),结合迭代加深减少不必要的扩展。
A*是否一定在效率上优于一般启发式算法?
不一定。A* 的效率依赖于启发函数 h(n) 的质量。如果启发函数过于简单或与问题无关,A* 可能扩展过多的节点,效率甚至低于简单的贪婪算法或深度优先搜索。此外,某些问题中更轻量级的启发式算法(如贪婪搜索)在空间和时间上可能更优。
题目四十四
结合当前人工智能的发展现状,简述你对图灵测试的认识。
答:
在当前人工智能高速发展的背景下,图灵测试仍然具有重要的指导意义。虽然近年来深度学习和其他AI技术的进步使得机器的语言处理能力得到了显著提升,但要真正达到人类的智力水平,还有很长的路要走。
图灵测试不仅是对机器智能的一种衡量方法,也推动了人工智能技术的发展和应用。它促使研究人员和开发者不断探索新的算法和技术,以提高机器的智能化水平,使其能够更好地理解和生成自然语言,与人类进行更自然、更流畅的交互。
同时,我们也应该认识到,图灵测试并不是评价一个人工智能系统优劣的唯一标准。在实际应用中,我们还需要考虑系统的可靠性、可解释性、安全性等多个方面。因此,在追求高智能化的同时,也需要注重其他关键指标的提升,以实现更全面、更实用的人工智能应用。
大题
启发式搜索+状态空间图
题目一
下图为一简单迷宫示意图及其平面坐标表示。从入口到出口有若干条通路,请用启发式搜索方法求从入口到出口处最短路径的走法,并画出状态空间图。
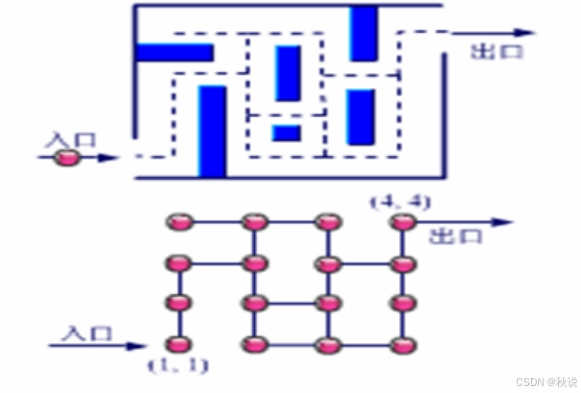
答:启发式搜索图如下。
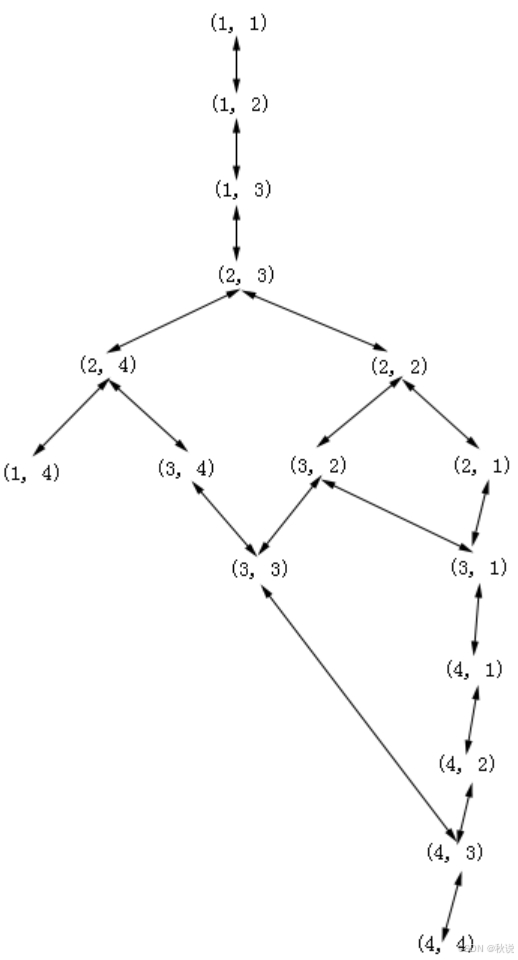
状态空间图:
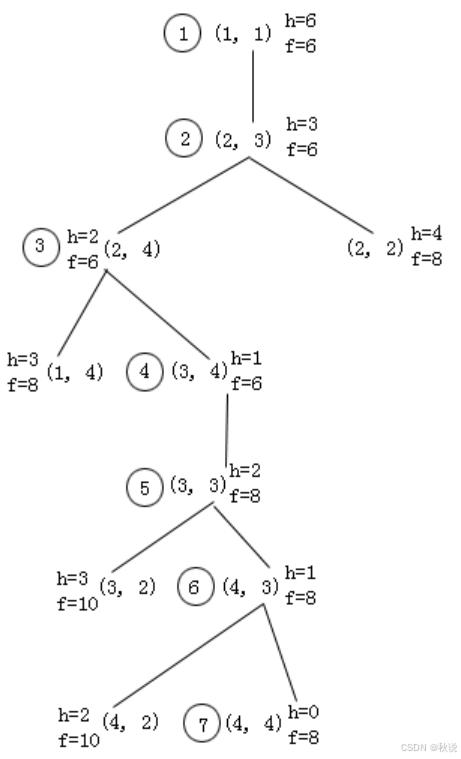
h表示当前点距离出口的距离,例如(2,3)距离出口(4,4)为(4-2)+(4-3)=3,因此(2,3)的h为3。
每次迭代,我们只选取h小的节点进行拓展。
f表示深度+h,由于(1,1)到达(2,3)的深度为3,(2,3)的f=(2,3)的深度+(2,3)的h=3+3=6
题目二
下图边上的数值表示边代价,节点处的数值表示该点的启发函数值h(n);A为初始节点,G为目标节点,采用启发式图搜索算法 A。
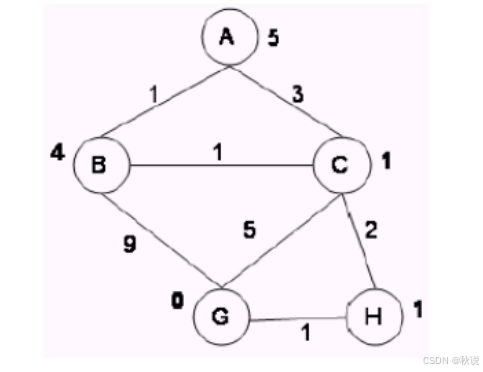
回答下列问题:
(1)简要说明一般情况下A算法每次扩展出的节点类型和处理原则;
答: a.若节点是新节点,直接标注父指针;b.若节点是已生成但未被扩展的,计算其评价函数值,父指针指向值较小的;c.若节点是已生成且已被扩展的,计算其评价函数值,父指针指向值较小的,且该节点重新放回 open表。
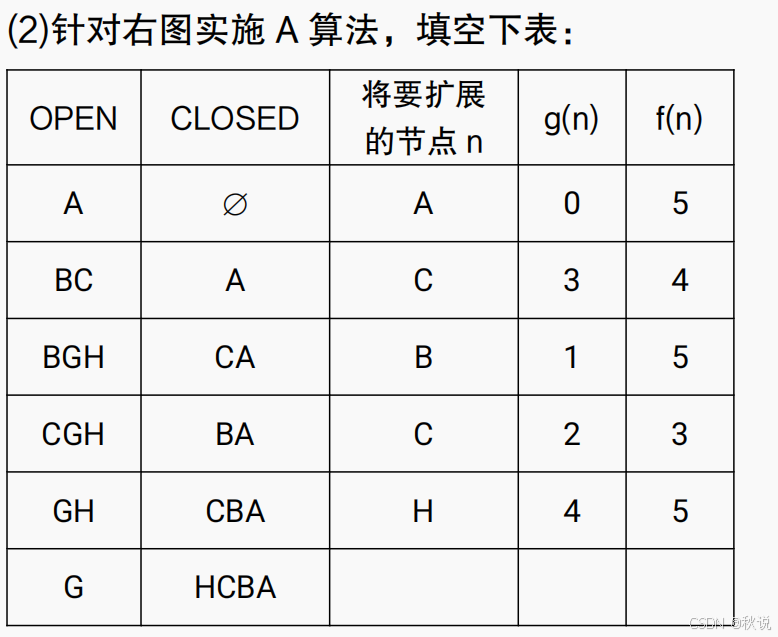
g(n)代表当前路径代价(即边上的数值),h(n)表示启发函数值,即节点旁的数字,f(n)=g(n)+h(n),哪个结点的f(n)最小,就选取该结点进行拓展。
(3)上述算法是 A*的吗?请详细说明你的理由。

怎么判断启发式函数是否满足单调性原则?

题目三
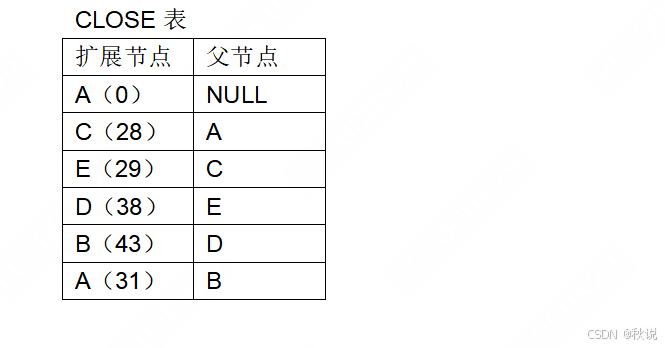
用代价优先算法求解下图的旅行推销员问题,请找一条从北京出发能遍历各城市的最佳路径(旅行费最少),每条弧上的数字表示城市间的旅行费用。并用CLOSED表记录遍历过的结点,OPEN表记录待遍历的结点。画出closed和open表的变化过程,然后根据closed表找出最佳路径。
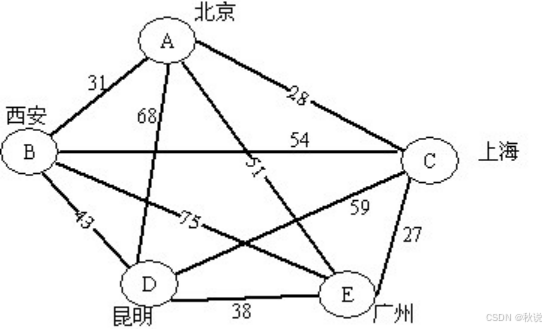
答:
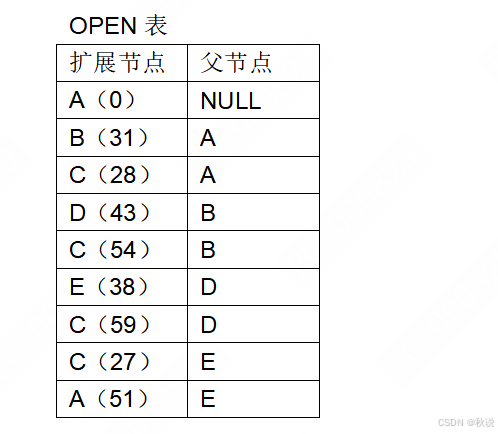
方法:按最小值的结点进行拓展。
博弈树
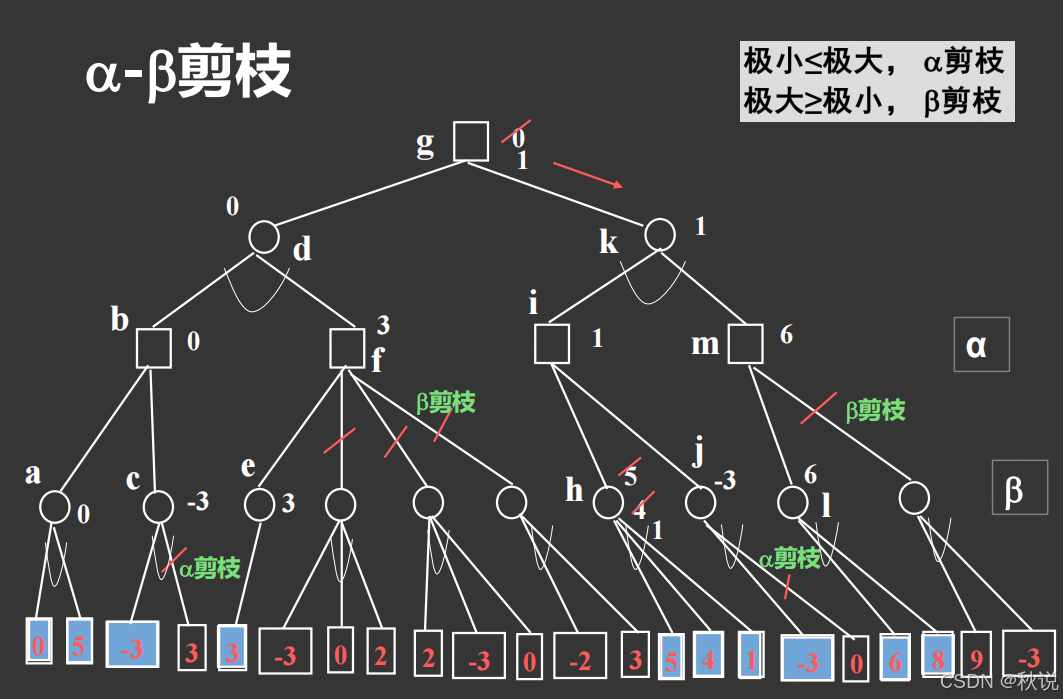
题目一
下图所示博弈树,按从左到右的顺序进行α-β剪枝搜索,试标明各生成节点的倒推值,何处发生剪枝(用“/” 在图上标记),及应选择的走步。
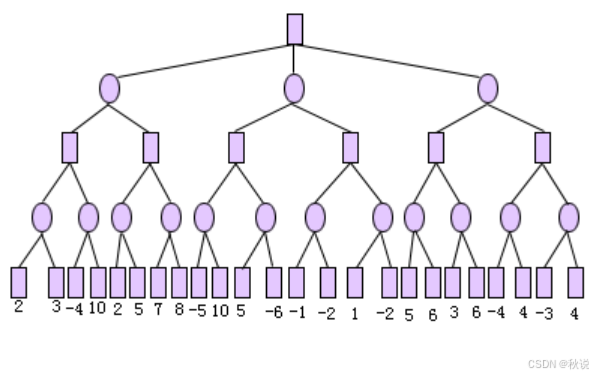
答:
题目二
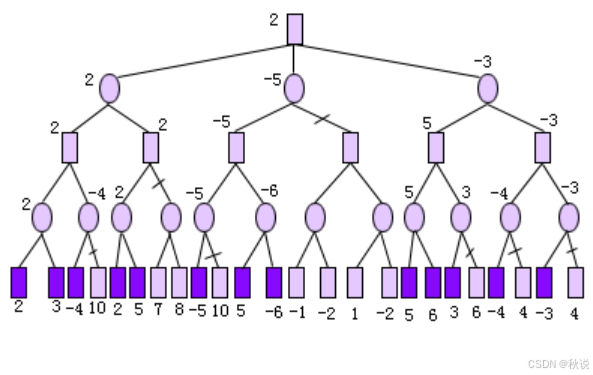
如图所示的双人博弈树,我方先手,已标出的数字为端结点的评估值。
1)标出每层的极大极小标记;
2)在框中填入用极小极大算法获得的倒推值并用箭头标出下一步应选择的走法;
3)采用从左到右的顺序进行α-β剪枝,用×标明剪枝处。
题目三
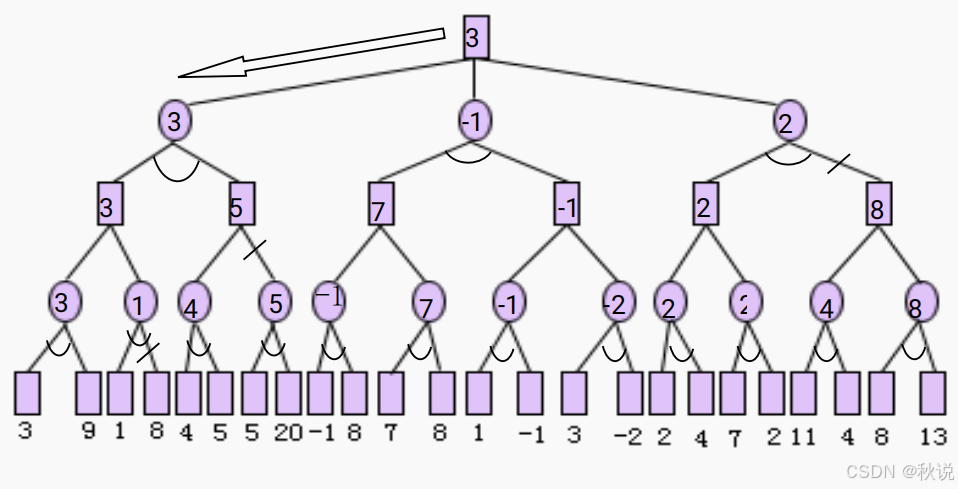
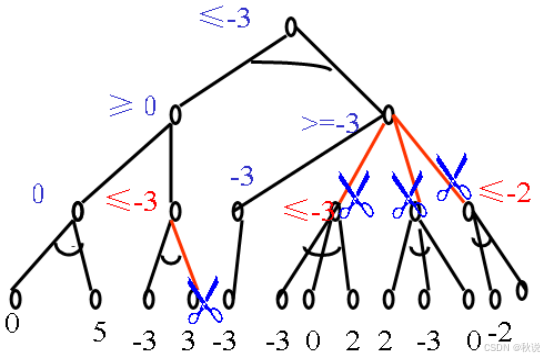
图示博弈树,其中末一行的数字为假设的估值,请利用α-β剪枝技术剪去不必要的分枝。(在节点及边上加注释)
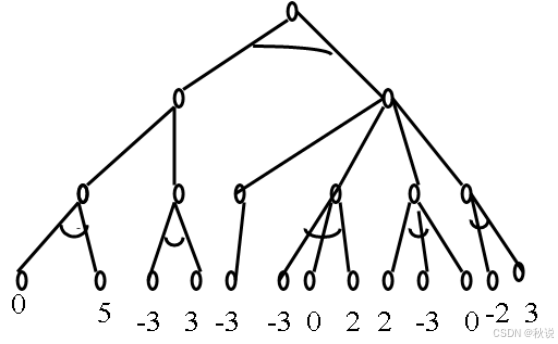
答:
题目四
A算法+搜索图
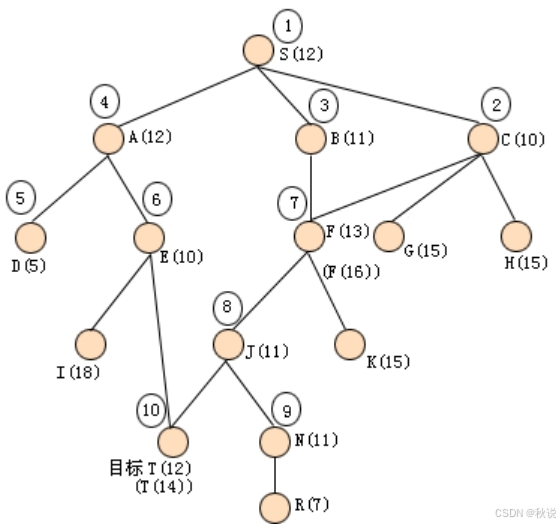
某问题的状态空间图如下图所示,其中括号内标明的是各节点的h值,弧线边的数字是该弧线的耗散值,试用A算法求解从初始节点S到目标节点T的路径。要求给出搜索图,标明各节点的f值,及各节点的扩展次序,并给出求得的解路径。
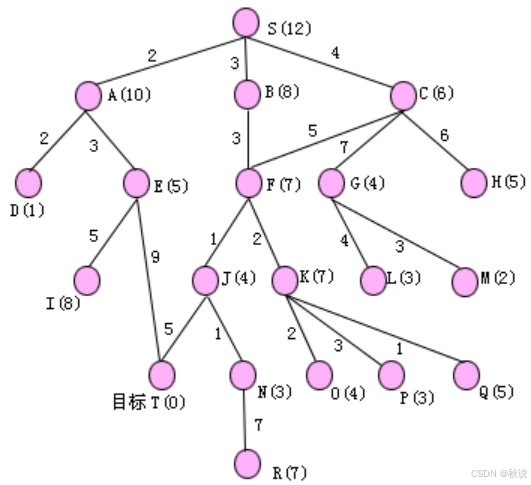
答:搜索图如下,得到的解路径为:S-B-F-J-T。
推理
题目一

题目二
凡是清洁的东西就有人喜欢;人们都不喜欢苍蝇。利用归结原理证明:苍蝇是不清洁的。要求:
(1)定义合适的谓词,用一阶谓词逻辑方式表示上述情况;
(2)将所得的一阶谓词逻辑公式化成相应的子句集;
(3)用归结反演法证明结论并写出完整的归结过程。
(1) A(x):x是清洁的;L(u,v):u喜欢 v;

(2)子句集:

(3)
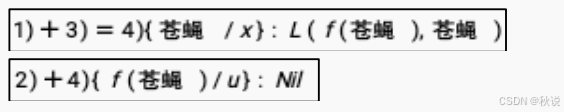
题目三
设有如下关系:(1)如果x是y的父亲,y又是z的父亲,则x是z的祖父;(2)老李是大李的父亲;(3)大李是小李的父亲;问上述人员中谁和谁是祖孙关系?
答:

题目四

题目五
设有A,B,C三人中有人从不说真话,也有人从不说假话,某人向这三人分别提出同一个问题:谁是说谎者?A 答:“B和C都是说谎者”;B答:“A和C都是说谎者”;C答:“A和B中至少有一个是说谎者”。求谁是老实人,谁是说谎者?

题目六
张某被盗,公安局派了五个侦察员去调查。研究案情时,侦察员A说:“赵与钱中至少有一人作案”;侦察员D说:“钱与孙至少有一人作案”;侦察员C说:“孙与李中至少有一个作案”;侦察员D说“赵与孙至少一个与案无关”;侦察员E说“钱与李中至少有一人与此案无关”。如果这五个侦察员的话都是可信的,试用消解原理推理求出谁是盗窃犯。

题目七
设已知:
(1)能阅读者是识字的
(2)海豚不识字
(3)有些海豚是聪明的
求证:有些聪明者并不能阅读

题目八

答:

题目九
某企业欲招聘一个JAVA程序员,定义如下产生式规则(要求):
r1: IF有工作经验 or (本科以上学历 and 有相关知识背景) then 录用(0.9)
r2:IF 工作两年以上 and 作过相关工作 then 有工作经验 (0.8)
r3:IF 学过数据结构 and 学过JAVA and 学过数据库 and 学过软件工程 then 有相关知识背景(0.9)
r4:学过数据结构(相关课程的成绩/100 )
r5:学过JAVA(相关课程的成绩/100 )
r6:学过数据库(相关课程的成绩/100 )
r7:学过软件工程(相关课程的成绩/100 )
r8:做过相关工作:
JAVA程序员:1,项目经理:1,数据库开发工程师:0.9,数据库管理员:0.7,网络管理员:0.6,客服人员:0.4
设有一本科毕业生甲,其相关课程的成绩为数据结构=85,JAVA=80,数据库=40,软件工程=90
另有一社会招聘人员乙,参加工作三年,曾做过数据库管理员和数据库开发人员。
根据确定性理论,问该公司应该招聘谁?如果你是该本科生,为了能在招聘中胜出,你应该加强哪门课程,并使该门课程的成绩至少达到多少?
答:
(1)对于本科毕业生,由r4,r5,r6,r7:
CF(学过数据结构)=0.85
CF(学过JAVA)=0.8
CF(学过数据库)=0.4
CF(学过软件工程)=0.9
由r3,CF(有相关知识背景)=0.9*min{0.85,0.8,0.4,0.9}=0.36
CF(本科学历)=1
由r1,CF(录用)=0.9*min{0.36,1}=0.324
(2)对于社会招聘人员,由r8,CF(相关工作)=0.9
CF(工作两年以上)=1
由r2,CF(有工作经验)=0.8*min{1,0.9}=0.72
由r1,CF(录用)=0.9*0.72=0.648
所以,该公司应录用社会招聘人员乙。
(3)可以看出,应该加强数据库的学习,并使该门课程达到80分以上。
题目十
题目十一
二元归结式

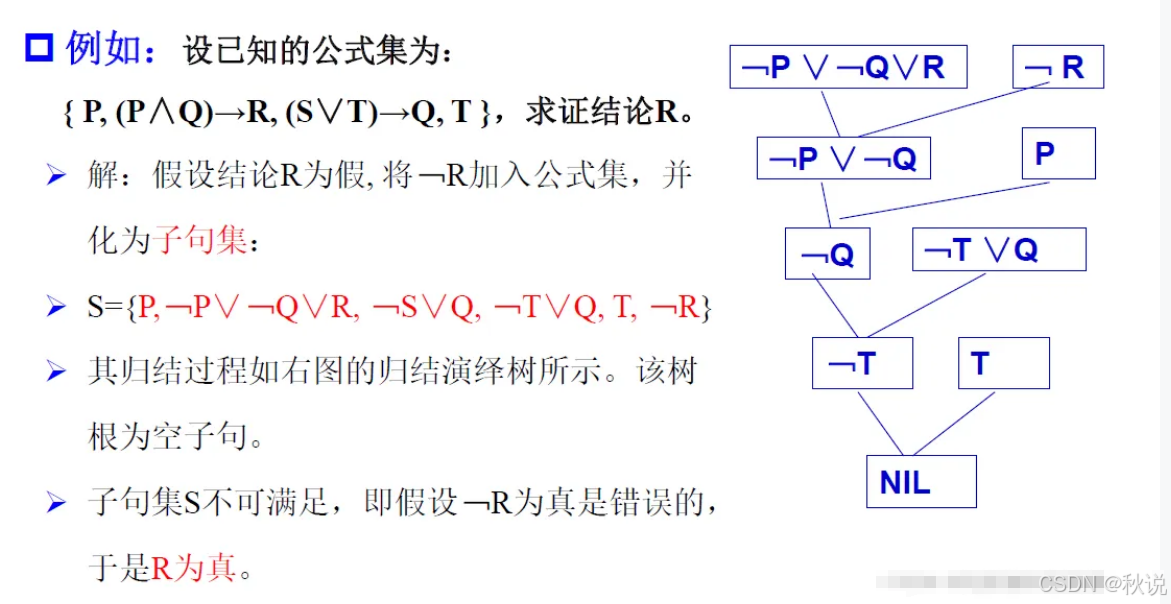
例题如下:

例题如下:

例题如下:


例题如下:

题目十二




题目十三
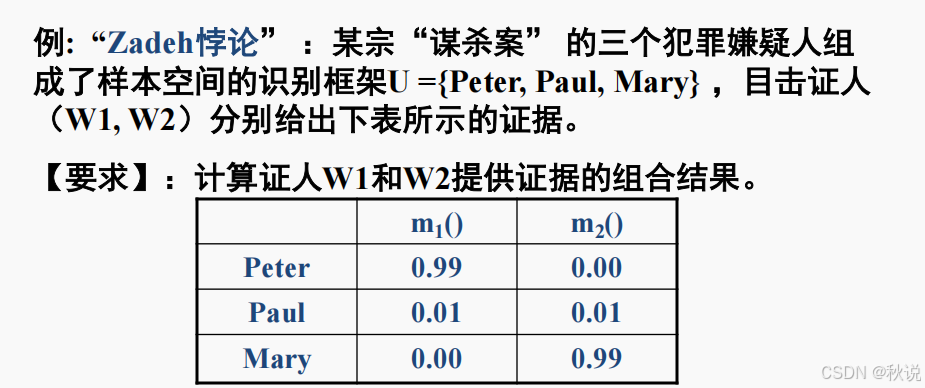
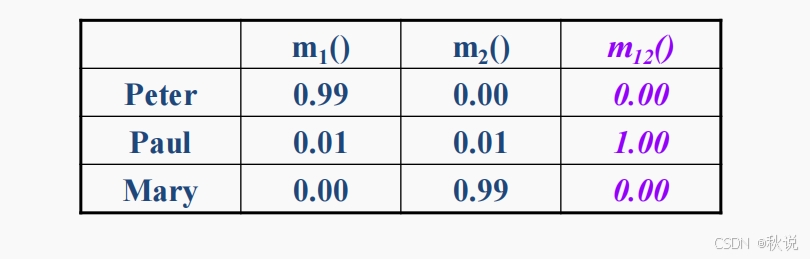
运用到的知识:

具体计算如下:

因此最终结果为:
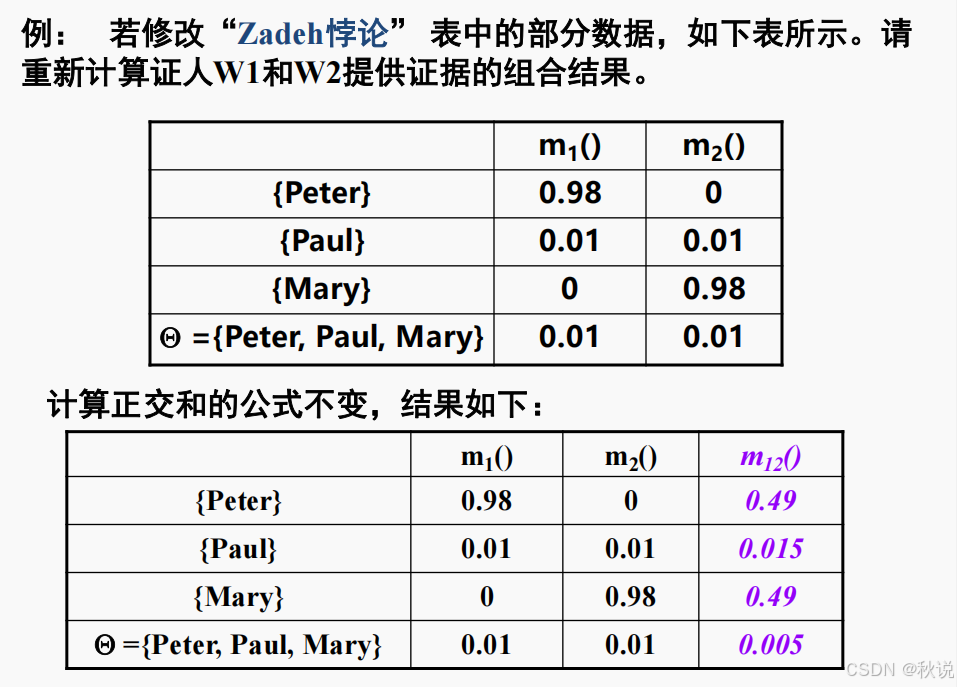
似然函数、信任函数
识别框架 U={晴,阴,雨},基本概率分配函数为:M({阴})=0.3,M({阴,雨})=0.5,M({晴})=0.01,M(U)=0.19,求子集{晴,阴}的信任函数和似然函数(列出计算过程)。
解:
Bel({晴,阴})= M({阴})+ M({晴})+ M({晴,阴})=0.3+0.01+0=0.31
Pl({晴,阴})=1-Bel(┐{晴,阴})=1- Bel({雨})=1
或Pl({晴,阴})=M({阴})+ M({晴})+ M({晴,阴})+ M({晴,雨})+ M({阴,雨})+ M(U)=1
主观贝叶斯方法
题目一
设有产生式规则 A→B,P(B)=0.01,LS=101,LN=0.4;写出主观 Bayes方法求 P(B|A)和 P(B|┐A)的公式并求其值;对结果做简要解释。
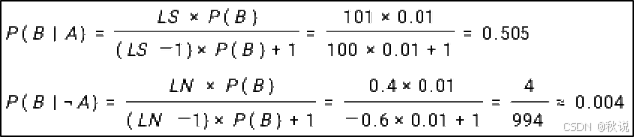
解释:A发生对结果B的发生有较大的支持,A不发生进一步减小了B发生的概率。
题目二
给定如下所示的一个Bayes网络及其条件概率表(CPT)
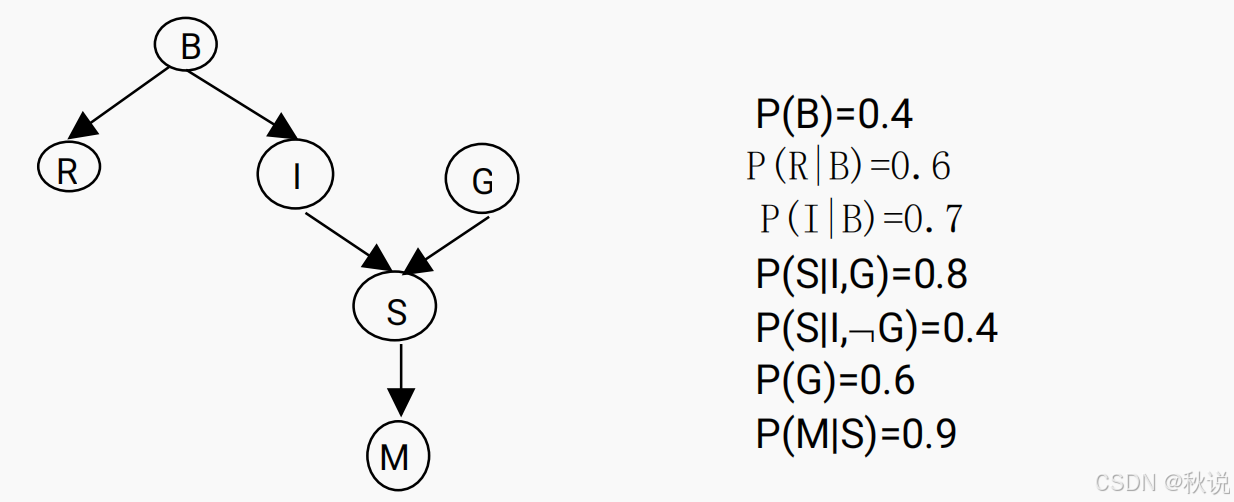
(1)用 Yes 或 No 填空下表,其中D-Sep(H1,H2|H)表示 H1、H2 在已知H的情况下被 D 分离

(2)利用条件独立性,计算联合分布概率 P(BRIGSM),写出计算过程(应包含使
用条件独立性之前和之后的公式)。

(3)求 P(S|I),写出计算过程。

决策树
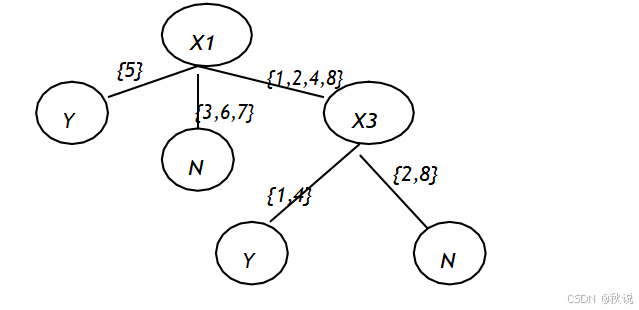
题目一
下表给出了根据学生平时的表现提供勤工俭学名额的决策表,试用 ID3 算法构造决策树,并写出相应的规则。
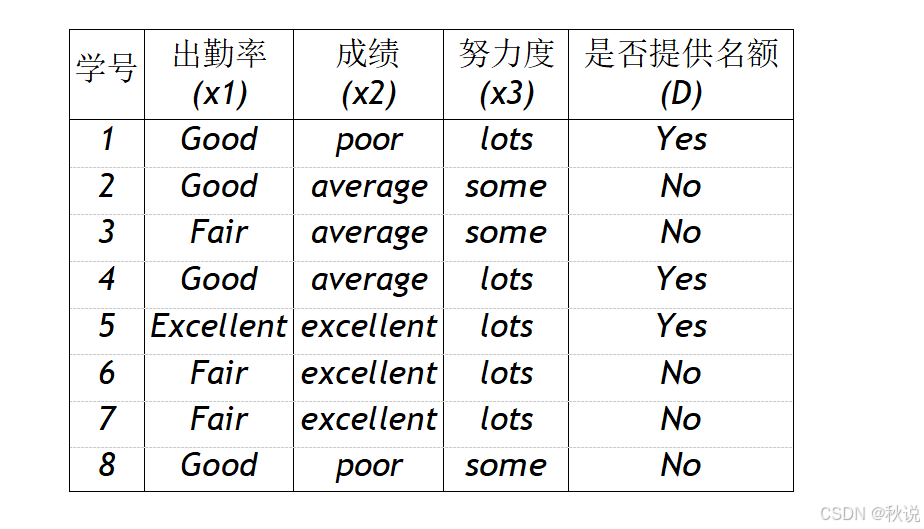
解:

规则 1:如果出勤率为 Excellent 则提供名额
规则 2:如果出勤率为 Fair 则不提供名额
规则 3:如果出勤率为 Good 且努力度为 lots 则提供名额
规则 4:如果出勤率为 Good 且努力度为 some 则不提供名额
题目二
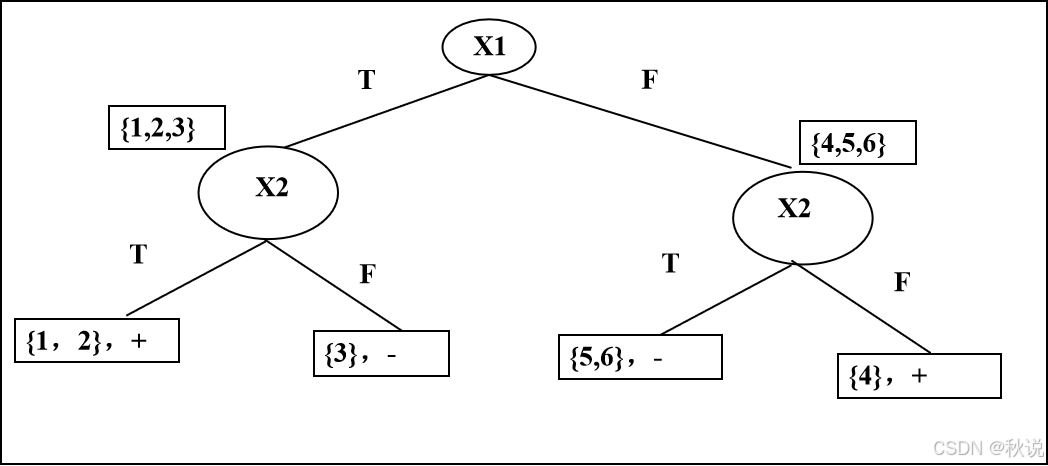
试用ID3算法构造决策树,并写出组别相应的规则。

答:
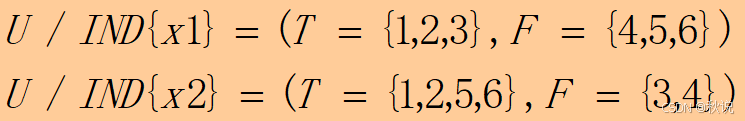
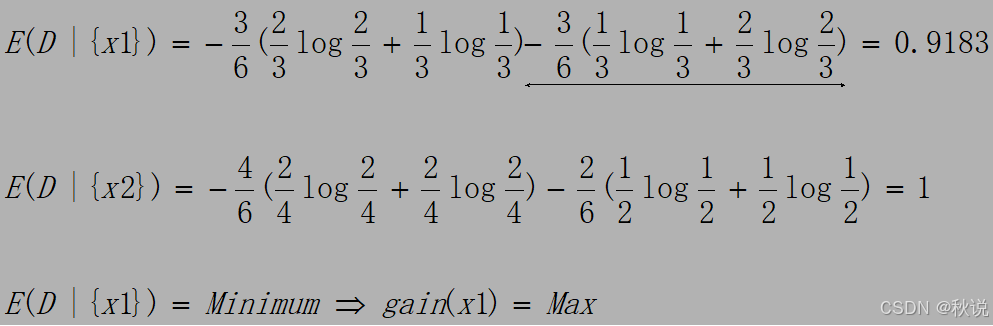
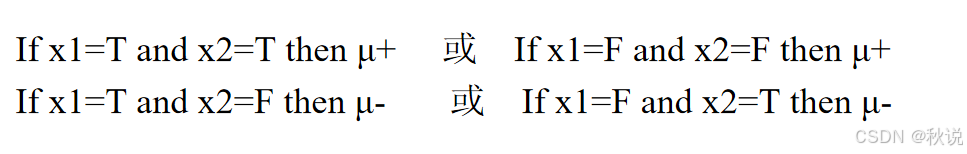


















 1079
1079

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











