







这里使用的编译器是vscode
Python 含有丰富的数据库扩展,我们只需要导入 requests 库就可以简单的进行一些操作
import requests
目前我们在浏览器中传输数据常见的使用HTTP(超文本传输)协议 在网络层,是万维网的数据通讯的基础,HTTP有两种报文,请求报文(客户向服务器发送)和响应报文(从服务器到客户的回答)以下我们需要先了解以下基础结构,如下图所示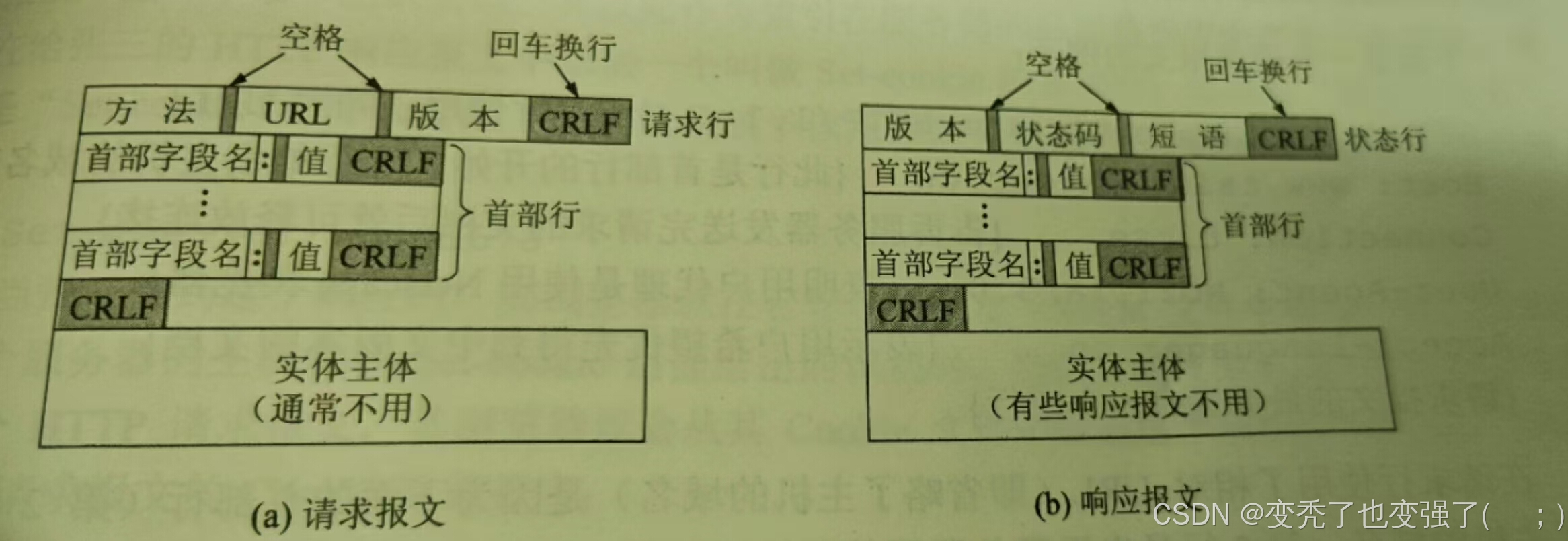
HTTP请求报文和相应报文都是由三部分构成,分为开始行,首部行,实体主体。这两种报文的格式区别就在于开始行的不同。下面先介绍请求报文的主要特点。
第一行只有三个内容,即方法,URL(统一资源定位符),HTTP的版本。不同版本的HTTP能使用的方法也不同,现在基本上使用的都是HTTP1.1了。URL新手这里可以理解为我们要搜索内容所到达的网址。方法也就是一些命令,常见的有post,get,push等,废话不多说直接上图:
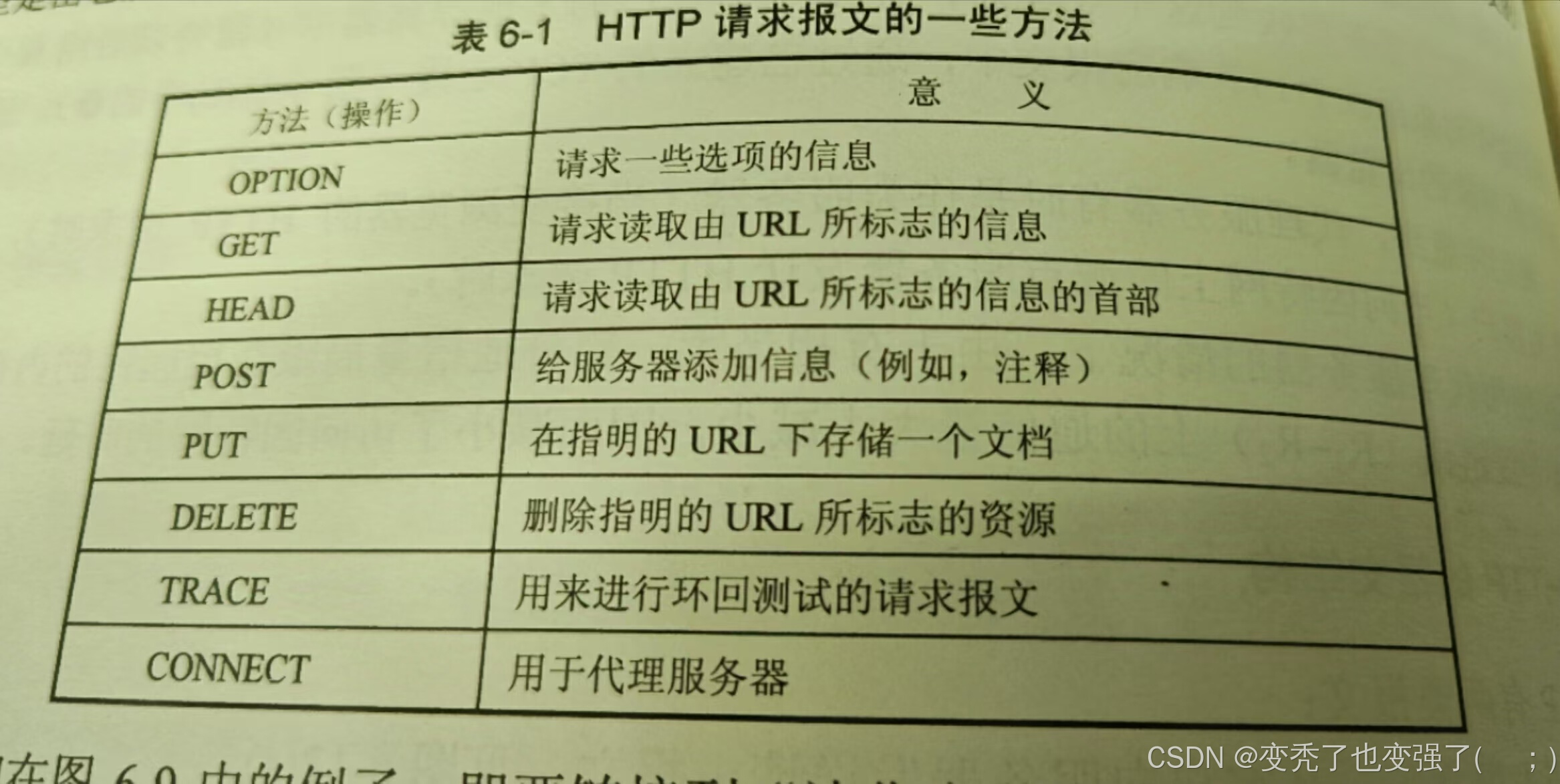

了解一下大概知识,开始简单使用
##这里输入你想爬取的界面的网址。
url = "https://www.baidu.com/"
##建立一个对象接受一下
reponse=requests.get(url=url)
打印输出。
##1 reponse.text 获取到的是字符串
print(reponse.text)
# 2 reponse.centent() 获取到的是原始的二进制数(bytes)
# 需要用decode()转换为字符串
print(reponse.content.decode())爬取的内容显示,我们可以将他写入文件中打开看看
写入文件
国内中文目前使用的大多数都是UTF-8编码也有使用“GBK"编码,加上encoding 防止出现乱码
with open("tssf.html",'w',encoding='utf-8') as f:
f.write(reponse.content.decode())#
# reponse.status_code 相应状态码
# reponse.request.headers 相应对应的请求头
# reponse.headers 响应头
# reponse.request.prepare_cookies
# reponse.cookies 相应的cookie (经过了set-cookie动作)
#
打开保存的html文件,可以看到链接是本地文件了

然而有些网站有简单的防爬虫方法,我们需要装饰一下我门这个请求报文的头部、
headers ={
"user-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0"
}
reponse=requests.get(url=url,headers=headers)如法炮制,我们还可以下载免费的视频和音乐


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









