






一、引言
在数字化浪潮的推动下,数据已成为推动社会进步和企业发展的关键力量。然而,随着数据量的爆炸性增长,如何高效地处理和分析这些数据成为了一个巨大的挑战。Hadoop,作为大数据处理领域的佼佼者,凭借其强大的分布式计算和存储能力,为我们提供了一种高效、可靠的大数据解决方案。
二、Hadoop简介
Hadoop是一个由Apache基金会开发的分布式系统基础架构,它利用集群的威力进行高速运算和存储。Hadoop的核心设计包括HDFS(Hadoop Distributed File System)和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
二、Hadoop的核心组件
1. 核心组件
Hadoop的架构主要由两个核心组件构成:
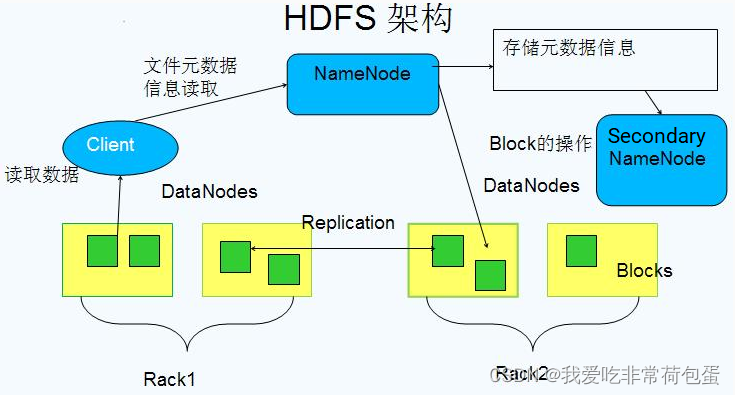
1.1 Hadoop Distributed File System (HDFS)
- 设计目的:HDFS是Hadoop的分布式文件系统,设计用于在普通硬件上存储超大规模数据集。
- 特点:
- 高容错性:HDFS将数据分散存储在集群中的多个节点上,每个节点存储数据的一个分片,并且每个数据块通常有多个副本分散在不同的节点上,以提供高可用性。
- 高吞吐量:HDFS为应用程序提供对大数据集的高效访问能力。
- Master-Slave架构:HDFS包含一个主节点(NameNode)和多个从节点(DataNode)。NameNode负责管理文件系统的命名空间和执行文件系统操作,如打开、关闭文件等;DataNode则存储实际的数据块。
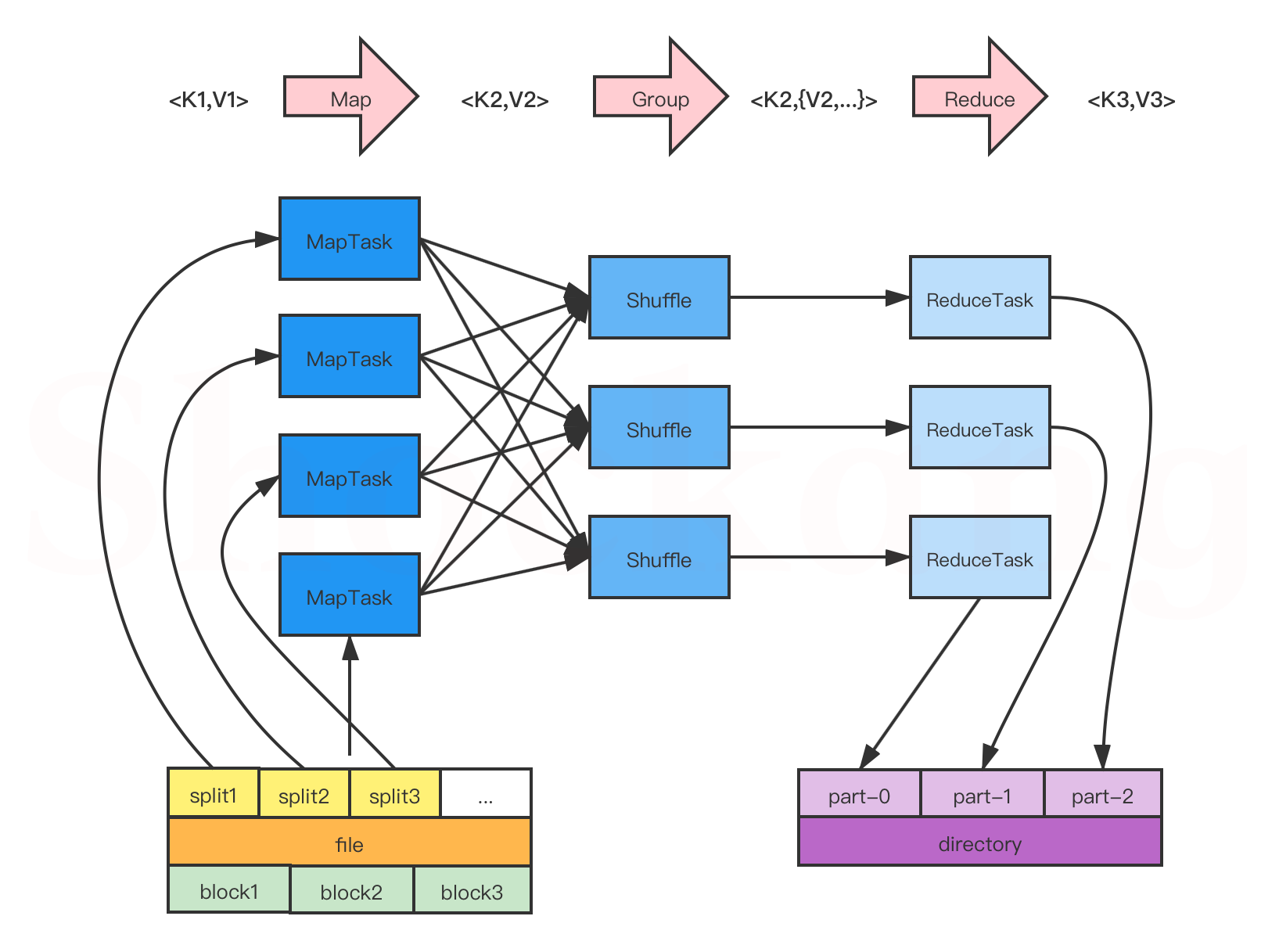
1.2 MapReduce
- 功能:MapReduce是Hadoop的分布式计算框架,它将复杂的任务分解为两个主要阶段:Map阶段和Reduce阶段。
- Map阶段:系统并行处理输入数据,生成一系列的中间键值对。
- Reduce阶段:系统对具有相同键的所有值进行归约操作,生成最终的结果。
2. 生态系统组件
除了HDFS和MapReduce这两个核心组件外,Hadoop的生态系统还包括以下重要组件:
- YARN:Hadoop的资源管理器,负责为多个应用程序分配和管理计算资源,提高计算资源的利用率。
- Hive:基于Hadoop的数据仓库工具,提供了类似SQL的查询语言(HiveQL)来查询存储在HDFS上的数据。
- HBase:一个基于Hadoop的分布式、面向列的NoSQL数据库。
- Zookeeper:用于维护配置信息、命名、提供分布式同步和提供组服务等。
- Spark:与Hadoop兼容的快速、通用的大规模数据处理引擎,提供了比MapReduce更高效的计算方式。
3. 特点和优势
- 可扩展性:Hadoop可以轻松扩展到数千个节点,处理PB级的数据。
- 容错性:HDFS和MapReduce都内置了容错机制,可以在节点故障时自动恢复数据和处理任务。
- 高效性:Hadoop利用并行处理,能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 低成本:Hadoop可以在廉价硬件上运行,降低了大数据处理的成本。
三、Hadoop的应用场景
Hadoop广泛应用于各种大数据处理场景,如搜索引擎、推荐系统、日志分析、金融风控等。在这些场景中,Hadoop可以帮助企业快速处理和分析海量数据,从而发现有价值的信息和趋势。
四、Hadoop的未来展望
随着大数据技术的不断发展,Hadoop也在不断地演进和完善。未来,Hadoop将继续优化其性能和稳定性,提高数据处理的效率和准确性。同时,Hadoop还将与其他大数据技术(如Spark、Flink等)进行深度融合,形成更加完善的大数据生态系统。
五、总结
总之,Hadoop作为大数据处理领域的佼佼者,已经为我们提供了一个强大的解决方案。在未来,Hadoop将继续发挥其在大数据处理领域的优势,为企业带来更多的价值和机会。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









