







引言:欧克,弥补上一篇的后续 : 趁现在还有时间 !!!

一. 原理:
ArrayList底层是基于数组实现的
数组(Array):是一种用连续的内存空间存储相同数据类型数据的线性数据结构。
数组的名字其实就是指向的数组的首地址,这其实c语中也是如此 !!!
当我们获取数组中的元素的时候:可以通过索引来获取元素,基于底层就是通过寻址公式来获取的 .
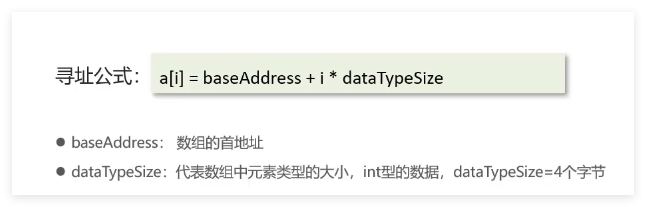
这里其实也就是为什么我们索引每次都是从0开始的,因为当我们从索引从1开始的时候,我们的寻找公式自然也就变成了
a[i] = baseAddress + (i-1)* dataTypeSize
注: 可以看到对于cpu来说,增加了一个减法指令。所以,索引从0开始,其实也是一个优化!!! 更加高效 !!
总结:
问:为什么数组索引从0开始呢?假如从1开始不行吗?

答:
- 在根据数组索引获取元素的时候,会用索引和寻址公式来计算内存所对应的元素数据,寻址公式是:数组的首地址+索引乘以存储数据的类型大小
- 如果数组的索引I从1开始,寻址公式中,就需要增加一次减法操作,对于CPU来说就多了一次指令,性能不高。
二. 3个构造方法:
Arraylist:源码分析:

成员变量:
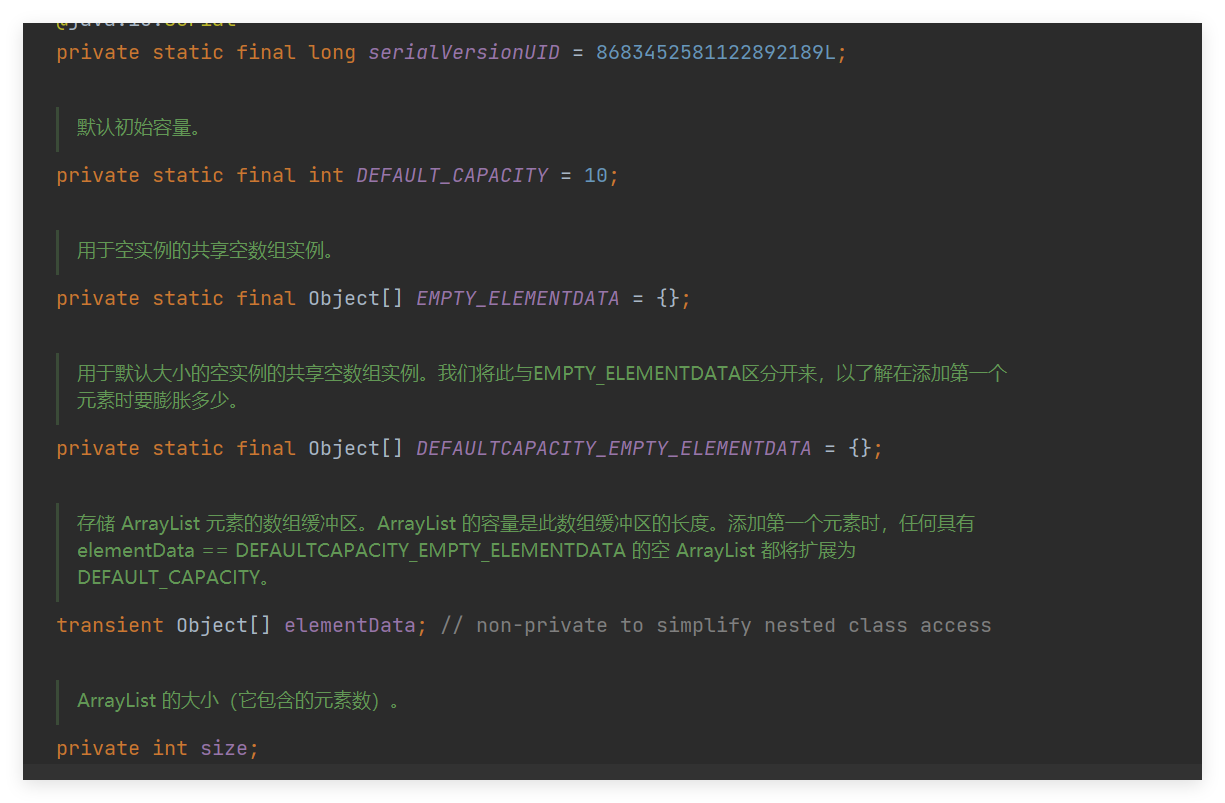
无参构造方法:
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}默认。会创建一个空的集合
带int 参数的构造方法:
/**
* Constructs an empty list with the specified initial capacity.
*
* @param initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
// 如果初始容量大于0
if (initialCapacity > 0) {
// 将elementData初始化为一个长度为initialCapacity的Object数组
this.elementData = new Object[initialCapacity];
}
// 如果初始容量为0
else if (initialCapacity == 0) {
// 将elementData初始化为一个空的Object数组
this.elementData = EMPTY_ELEMENTDATA;
}
// 如果初始容量小于0
else {
// 抛出IllegalArgumentException异常,提示非法的容量
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
会判断用户初始给的大小来初始化数组的大小,如果大于0就直接创建一个当前大小的数组,如果等于0就默认创建一个空的集合,如果小于0就抛出 IllegalArgumentException 异常 !
带父接口 Collection 的参数:
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public ArrayList(Collection<? extends E> c) {
// 将集合转换为数组
Object[] a = c.toArray();
// 如果数组长度不为0
if ((size = a.length) != 0) {
// 如果集合是ArrayList类型
if (c.getClass() == ArrayList.class) {
// 直接使用集合的数组
elementData = a;
} else {
// 将集合的数组拷贝到一个新的数组中
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// 如果数组长度为0,则替换为空数组
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
首先会把当前的参数集合转化成数组,如果数组长度不为0,并且类型是ArrayList 类型的,直接把当前对象的引用赋值给当前数组如果是不是,就copyOf 拷贝,当然,如果数组长度为0的话。就直接给当前数组设置为空对象 !!!

三. 添加和扩容操作(第一次添加数据 )
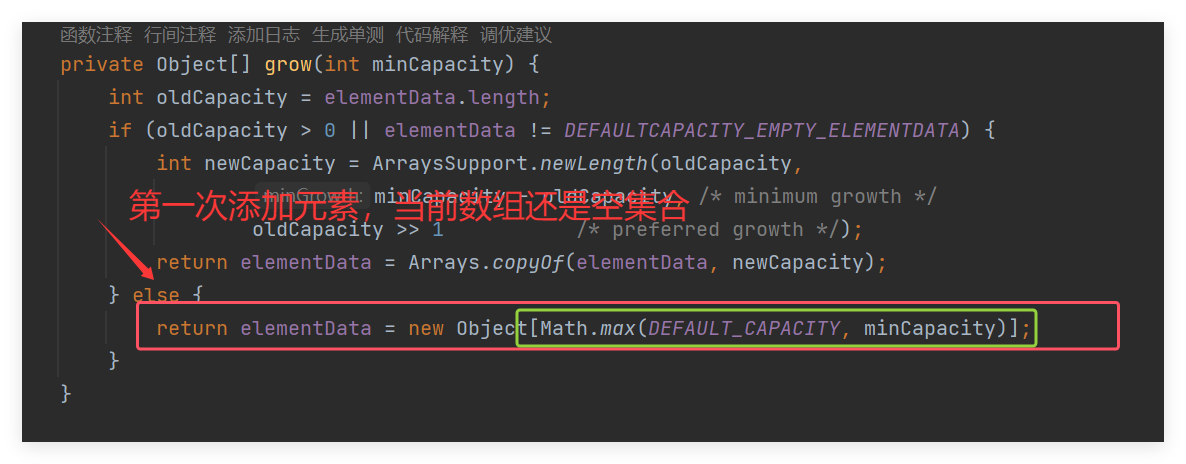
当我们创建集合的时候,此时这个集合是一个空集合,
当我们首次通过add()方法添加元素的时候,源码跟踪可以看到最后会给我们的数组默认初始化DEFAULT_CAPACITY=10,
关键源码:
首次添加元素的时候,因为s 初始化为0 当前数组也是0 等效于当前数组满了,需要扩容了,然后内部调用grow()方法扩容
进入 grow() 方法内部:可以看当因为我们用的 add()添加一个元素,标志当前数组的元素为size +1 ,因为首次,所以就是1
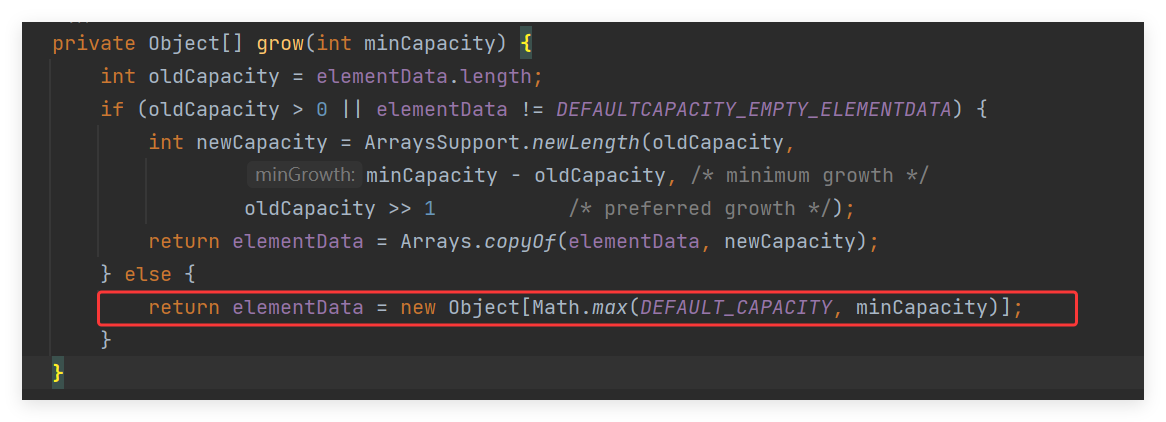
然后又因为当前第一次添加,数组的大小是为0的,并且 是一个空数组,就直接走else 条件了:
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)]
private static final int DEFAULT_CAPACITY = 10: 是大于我们第一次添加时 传来的 minCapacity参数也就是1的,所以就放回一个 默认初始为10的空数组 大小了!!!
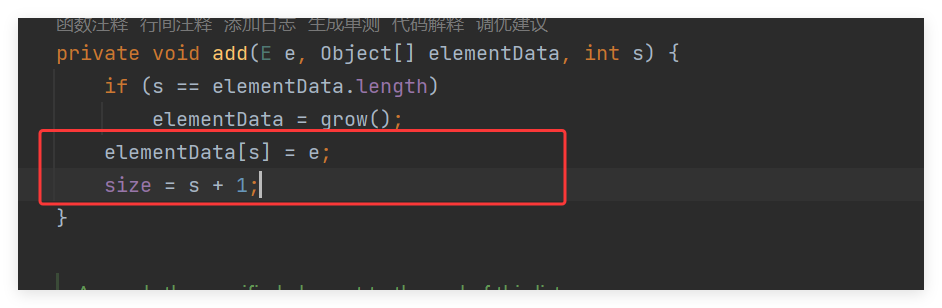
当触发扩容之后:在返回到源码的部分来执行后续的代码:然后就是赋值,并且size+1,记录当前的数组的长度。我这里是jdk17版本,其实看jdk 前的版本,这里好像是 elementData[size++] = e
整体源码:
/**
* 将指定的元素追加到此列表的末尾。
*
* @param e 要追加到此列表的元素
* @return {@code true}(由 {@link Collection#add} 指定)
*/
public boolean add(E e) {
// 修改计数器加1
modCount++;
// 调用add方法,将元素添加到列表的末尾
add(e, elementData, size);
// 返回true,表示添加成功
return true;
}
/**
* This helper method split out from add(E) to keep method
* bytecode size under 35 (the -XX:MaxInlineSize default value),
* which helps when add(E) is called in a C1-compiled loop.
*/
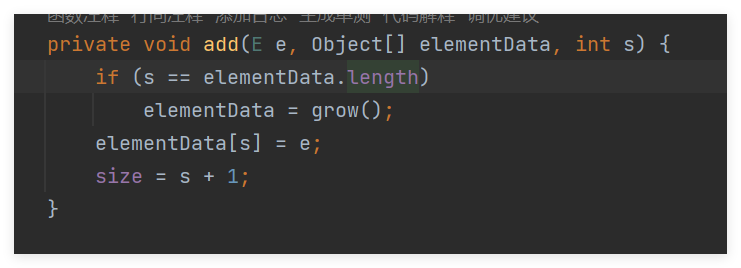
private void add(E e, Object[] elementData, int s) {
// 如果数组已满
if (s == elementData.length)
// 扩展数组
elementData = grow();
// 将元素e添加到数组的s位置
elementData[s] = e;
// 更新数组大小
size = s + 1;
}
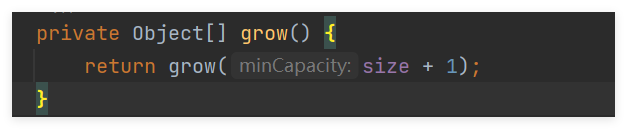
private Object[] grow() {
return grow(size + 1);
}
/**
* 增加容量以确保它可以容纳至少由最小容量参数指定的元素数量。
*
* @param minCapacity 期望的最小容量
* @throws OutOfMemoryError 如果minCapacity小于零
*/
private Object[] grow(int minCapacity) {
// 获取旧的容量
int oldCapacity = elementData.length;
// 如果旧容量大于0或elementData不是默认的空数组
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 计算新的容量
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* 最小增长量 */
oldCapacity >> 1 /* 期望的增长量 */);
// 返回新的数组
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
// 返回新的数组,容量为DEFAULT_CAPACITY和minCapacity中的较大值
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
其实这里看源码,如果首次调用的是addAll(Collection<? extends E> c) 方法来添加元素的时候,这里初始化数组的大小就要看初始容量10和 传的这个集合的大小谁更大了,就默认根据最大的大小来创建当前大小的数组源码:
 return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)]
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)]
后续的添加逻辑:
2~10次的add()方法添加元素,就会直接添加元素了,不会走扩容机制了,没问题把。因为不会满足 s == elementData.length这个条件的。当前数组的大小是大于数组元素的个数的 !!
触发扩容机制:
扩容是一个相对耗时的操作,因为需要分配新的内存并复制元素。频繁的扩容会影响性能,因此建议在创建ArrayList时根据预期的元素数量设置合适的初始容量。
负载因子
ArrayList的扩容机制与负载因子(即当前元素数量与数组容量的比值)无关,不同于哈希表等数据结构。ArrayList采用固定比例的扩容策略。
这里扩容其实分了2个方法,一个add() 方法,一个是addAll() 方法,其实原理都是一样:
先来看看add()方法:
当添加元素的时候,会判断当前数组的元素是否已经满了,等于当前数组的大小了:
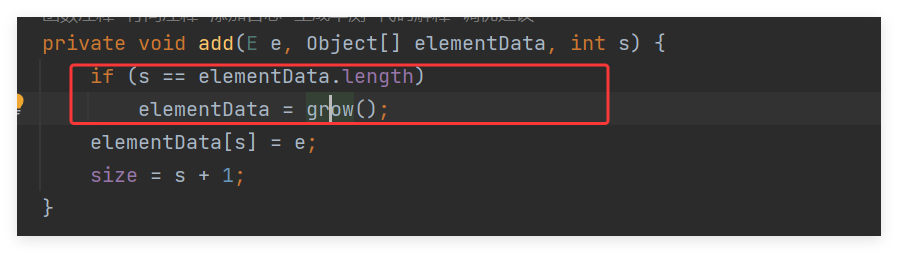
然后调用grow()方法:
minCapacity是所需的最小容量,用于确保扩容后数组至少能容纳这个数量的元素(一般为传入的size(当前数组的元素个数) + 1数)
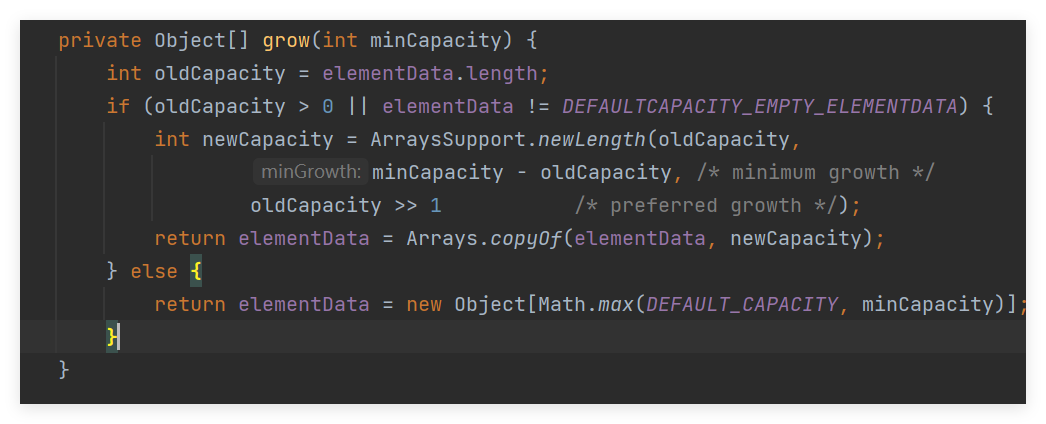
然后会调用ArraysSupport里的newLength(ldCapacity,minCapacity - oldCapacity,oldCapacity >> 1)方法,这个1方法会通过判断返回一个具体的扩容后的新的数组的容量大小: 三个参数分别代表的:
ldCapacity: 当前底层数组的总容量。
minCapacity - oldCapacity, :最少需要扩容的大小
oldCapacity >> 1 :偏好扩容大小(通常是当前数组长度的一半,即oldCapacity >> 1)
然后 具体看
int prefLength = oldLength + Math.max(minGrowth, prefGrowth);
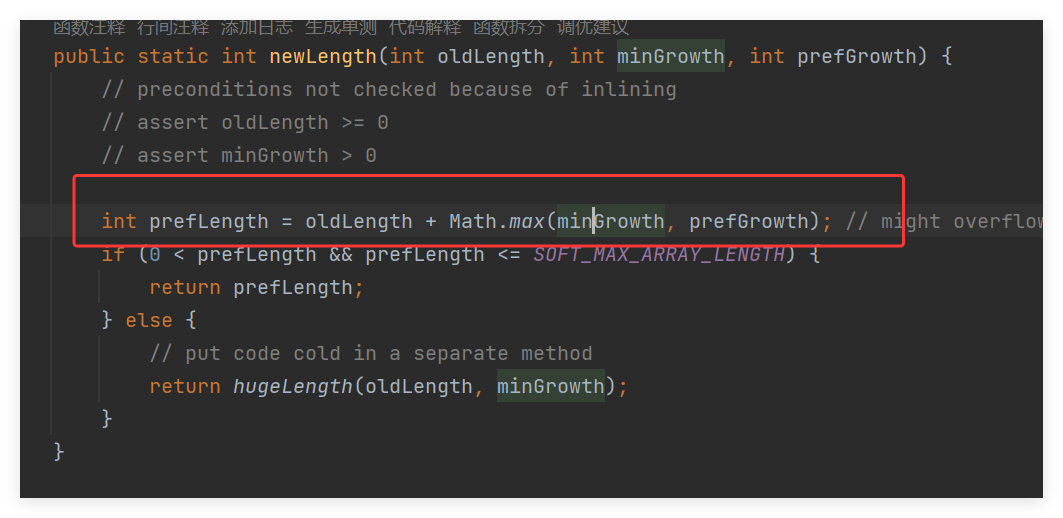
Math.max(minGrowth, prefGrowth); 如果当前我最少需要的扩容大小小于你 通过扩容的老数组的一半大小,那么我就选择prefGrowth,这样可以减少频繁扩容的次数,提高性能。
如果minGrowth >prefGrowth,这种情况就是另一种方法才会设计到的!因为add方法都是一个一个添加的,每次都是加1,当触发扩容的时候,minGrowth只是比当前数组大小大1,是不可能大于数组的一半大小,而且初始容量最小都是10,一半也才5对吧!!!所以出现当前这种情况只能是调用 addAll(Collection) 方法时,如果要添加的集合大小 n 超过了 prefGrowth(即 n > oldCapacity >> 1),那么 当前新数组的大小就是原来数组元素个数加新增加的元素大小
addAll(Collection<? extends E> c)源码:
如果新增元素数量大于当前列表剩余的空间容量,则扩容
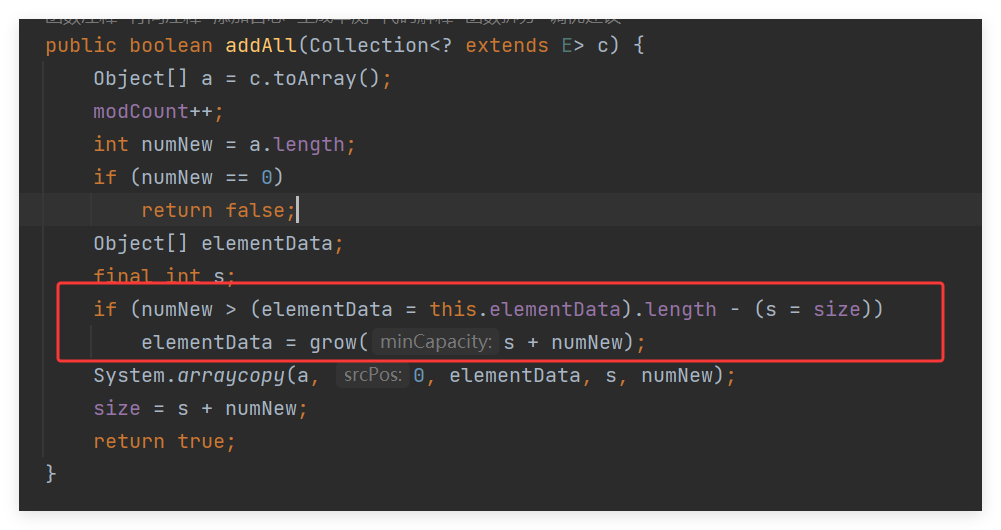
grow(s + numNew)的含义:
s(即size)是当前ArrayList的元素个数。
numNew是要添加的新元素个数。
s + numNew表示扩容后的最小容量需求(即当前元素个数 + 新元素个数)。
grow(s + numNew)会确保底层数组至少能容纳s + numNew个元素。
grow(s + numNew) 会确保底层数组至少能容纳 s + numNew 个元素。
此时这里和上面就差不多了,因为这里 grow 携带的参数才可能会最终在
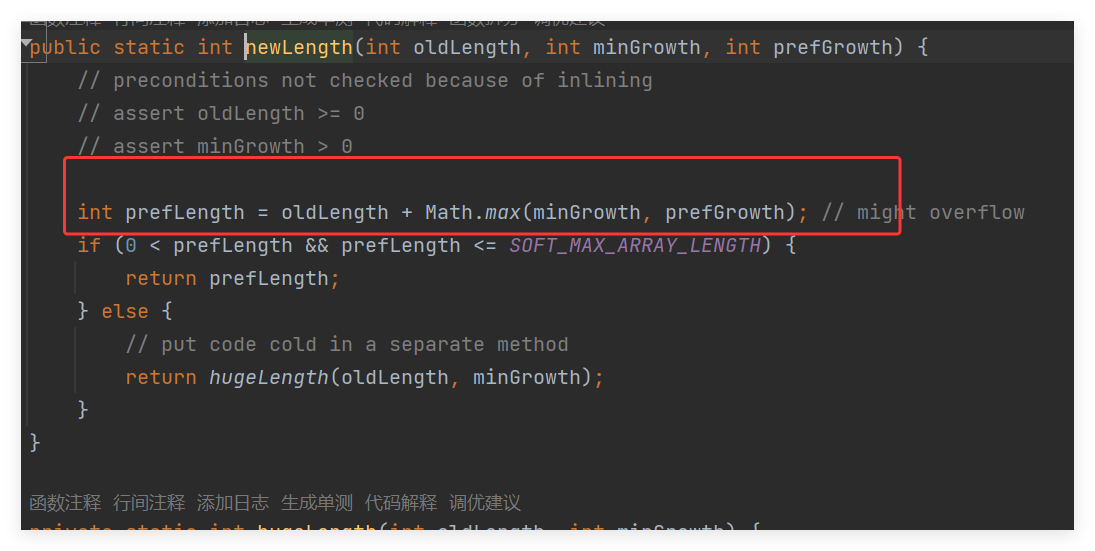
minGrowth >prefGrowth 的,所以并不是每次扩容都是原来的一半的,也得分情况得 !!!
反正最终得效果都是:保扩容后的数组能容纳所有新增元素。然后就是数组的拷贝将老的数组拷贝到新的数组 !!!

Over!就到这里吧,后续在慢慢补充 !!!祝大家顺顺利利 !!!节假快乐 !!! 也祝自己心想事成 ,活成自己想要的样子 !!!!


















 6806
6806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











