






文件目录管理(过滤、排序)
一、过滤/查看文件内容 grep
1、命令使用格式
# grep [选项] "pattern" 文件名称
- pattern 条件、模式
- 由普通字符、正则表达式组成 的条件
[root@localhost ~]# grep "root" /etc/passwd
[root@localhost ~]# grep "boot" /etc/fstab
UUID=d672e477-4028-4d42-9917-f6c45c631a46 /boot xfs defaults 0 0
[root@localhost ~]# ifconfig ens33 | grep "netmask" inet 192.168.140.161
netmask 255.255.255.0 broadcast 192.168.140.255
[root@localhost ~]# grep "model name" /proc/cpuinfo
- 默认行为
- 显示整行
2、正则表达式
- 由一类特殊字符(元字符)组成的表达式
- 匹配一类具有相同特征的文本
1) 匹配单个字符
. 任意单个字符
[root@localhost ~]# grep "r..t" /etc/passwd
[root@localhost ~]# grep "F." /etc/passwd
[akt] 任选其中一个,或者
[root@localhost ~]# grep "b[skt]" /etc/passwd
[root@localhost ~]# grep "[kPO]" /etc/passwd
[a-z] 任意单个小写字母
[A-Z] 任意单个大写字母
[a-zA-Z] 任意单个字母
[0-9] 任意单个数字
[a-zA-Z0-9] 任意单个字母、或数字
[root@localhost ~]# grep "[A-Z]" /etc/passwd
[root@localhost ~]# grep "[A-Z][0-9]" /usr/share/dict/words
[^a-z] 取反
[root@localhost ~]# grep "[^a-z]" /etc/fstab
[[:space:]] 任意单个空白字符
[root@localhost ~]# grep "[[:space:]]" /etc/passwd
2) 匹配字符出现的次数
* 匹配前一个字符出现任意次
.*
[root@localhost ~]# grep "a[0-9]*" /opt/file01
\+ 匹配前一个字符至少出现1次
[root@localhost ~]# grep "a[0-9]\+" /opt/file01
\? 匹配前一个字符最多出现1次 可有可无
[root@localhost ~]# grep "a[0-9]\?" /opt/file01
\{3\} 匹配前一个字符精确出现3次 ab{3}
[root@localhost ~]# grep "a[0-9]\{2\}" /opt/file01
- \{2,4\} 至少2次,最多4次
[root@localhost ~]# grep "a[0-9]\{2,5\}" /opt/file01
- \{2, \} 至少2次
[root@localhost ~]# grep "a[0-9]\{2,\}" /opt/file01
3) 分组 \( \)
- 将多个字符作为一个整体来看
[root@localhost ~]# grep "\(ab\)\{2,\}" /usr/share/dict/words
4)匹配字符出现的位置
- ^string
- 以string开头
[root@localhost ~]# grep "^[rmk]" /etc/passwd
[root@localhost ~]# grep "^#" /etc/fstab
- string$
- 以string结尾
[root@localhost ~]# grep "bash$" /etc/passwd
- ^$
- 空行
[root@localhost ~]# grep "^$" /opt/file01 | wc -l
匹配IP:
[root@localhost ~]# grep "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}" /opt/file02
匹配邮箱:
[root@localhost ~]# grep "[a-zA-Z0-9_]\+@[a-z0-9]\+\.[a-z]\+" /opt/file02
匹配MAC地址:
[root@localhost ~]# ifconfig ens33 | grep "[0-9a-f]\{2\}:[0-9a-f]\{2\}:[0-9a-f]\{2\}:[0-9a-f]\{2\}:[0-9a-f]\{2\}:[0-9a-f]\{2\}"
[root@localhost ~]# ifconfig ens33 | grep "\([0-9a-f]\{2\}:\)\{5\}[0-9a-f]\{2\}"
3、常用选项
- -o
- 只显示符合条件的内容
[root@localhost ~]# grep -o "r..t" /etc/passwd
[root@localhost ~]#ifconfig ens33 | grep -o "\([0-9a-f]\{2\}:\)\{5\}[0-9a-f]\{2\}"
- -i 忽略大小写
[root@localhost ~]# grep -i "^a" /opt/file01
- -v 反向过滤 , 取反
[root@localhost ~]# grep -v "^#" /etc/fstab
- -e
- 支持多条件过滤
[root@localhost ~]# grep -e "^#" -e "^UUID" /etc/fstab
- -E
- 支持扩展正则表达式
[root@localhost ~]# grep -E "(ab){2,}" /usr/share/dict/words
二、排序、去重
1、去重
# uniq 文件名称
[root@localhost ~]# uniq /opt/file03
[root@localhost ~]# sort /opt/file03 | uniq
2、排序
[root@localhost ~]# sort -t: -k2 -n -r /opt/file04
- 默认是按照ASCII码表进行排序
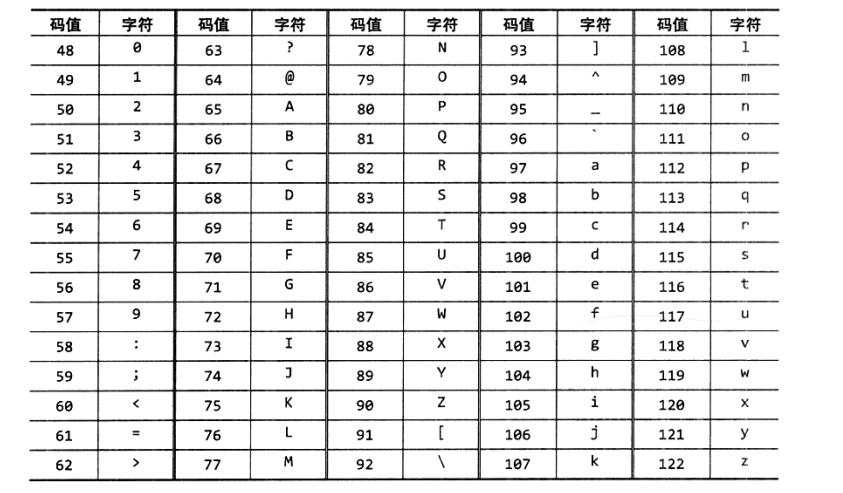
- -r
- 倒序,默认是升序
- -n
- 按生活数字大小排序
- -k
- 按每行的第几列进行排序
- 默认按照空白进行区分列
- -t
- 指定行分割符


















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









