







大家好!我是职场程序猿,感谢您阅读本文,欢迎一键三连哦。
精彩专栏推荐👇🏻👇🏻👇🏻
开发环境
开发语言:Python
框架:Flask
Python版本:python3.7
源码下载地址:
https://download.youkuaiyun.com/download/m0_46388260/90207360
论文目录
【如需全文请按文末获取联系】


一、项目简介
- Python网络爬虫进行数据采集:爬取微博评论数据,包括评论内容、转发数、点赞数等信息。
- 数据清洗与预处理:去除重复数据、无效数据和特殊字符,对缺失值进行处理等。
- 中文分词与LDA主题分析:去除停用词,输出每个主题下的关键词以及各个关键词的权重。
- SnowNLP算法进行情感分析:将评论划分为“正面”、“负面”“中性”。
- 数据分析和可视化:Echarts等可视化库绘制相应的图表和图像。
- 分析结果与预测:
二、系统设计
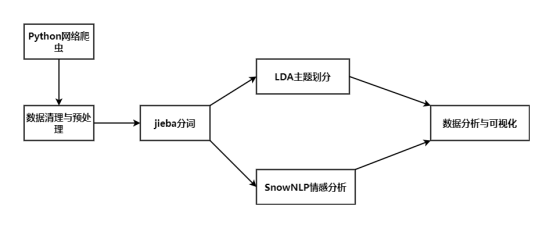
2.1软件功能模块设计
2.2数据库设计
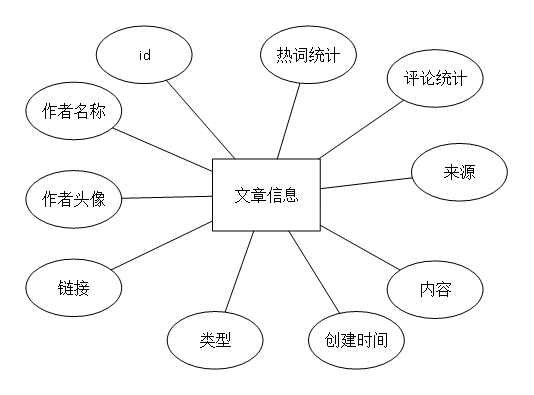
文章信息实体图如图4.4所示。
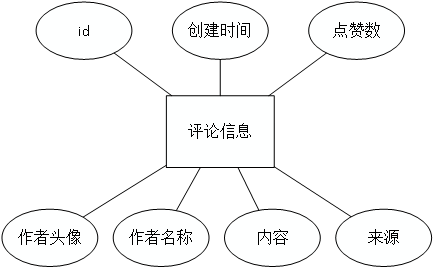
评论信息实体图如图4.5所示。
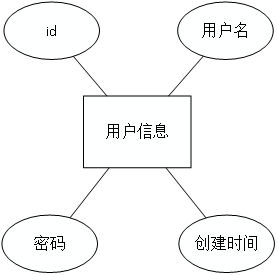
用户信息实体图如图4.6所示。
三、系统项目部分截图
3.1整体界面预览
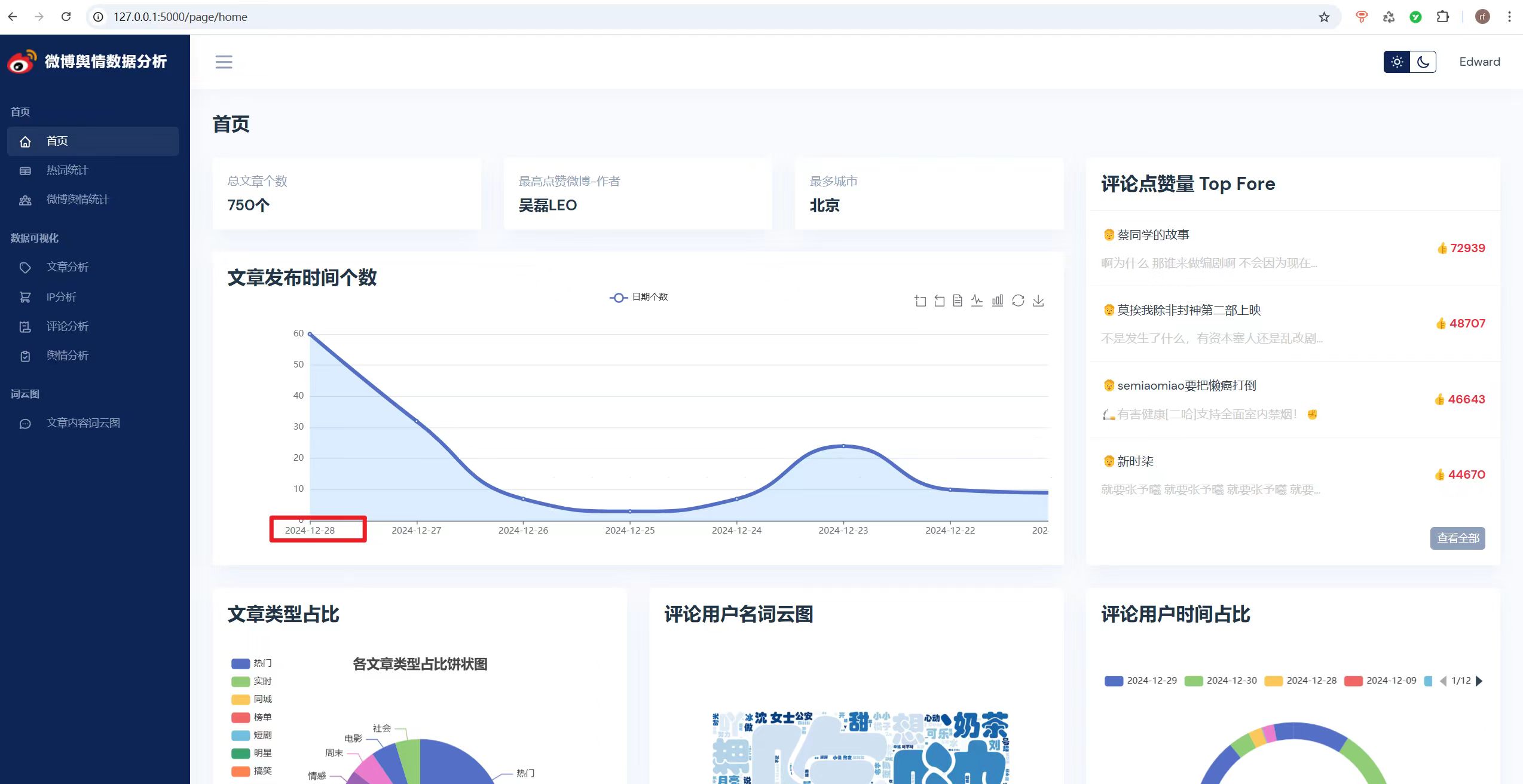
3.2热词统计
热词统计界面为用户展示了当前最热门的关键词,这些热词通过对大量微博内容的分析提取得出,能够直观地反映出社交媒体上的热点话题。该界面采用条形图的形式展示,使得数据可视化直观、易于理解,为用户提供了一个简洁明了的热点追踪工具。
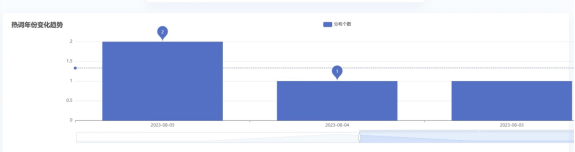
3.3微博舆情统计
微博舆情统计界面通过图4.9展示了微博平台上用户的文章统计,包括文章ID、文章IP、点赞量、转发量、评论量、类型和发布时间。该统计帮助用户得以快速对文章进行分类所示,在感性层面对舆情有一个初步的把握。
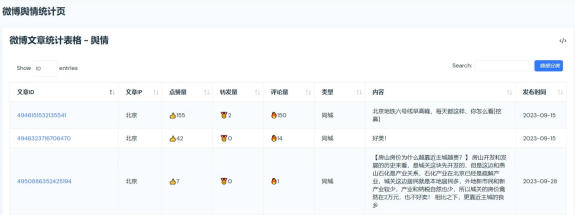
3.4文章分析
文章分析提供了对特定微博文章内容的深入分析,包括点赞量、转发量、评论量等关键指标的统计。这个界面使用户能够评估单个或一组微博文章的影响力和受众反响,通过对文章各项指标的分析,用户可以了解文章的传播效果和公众的参与度。文章分析界面如图4.10至4.12所示。
3.5舆情分析
舆情分析界面综合了上述多维度的数据分析,提供了一个全面的舆情分析报告。通过集成热词、情感倾向、文章内容与评论内容舆情趋势等多方面的信息,该界面为用户呈现了一个全景式的舆情分析视图,帮助用户从宏观上把握舆情走势。
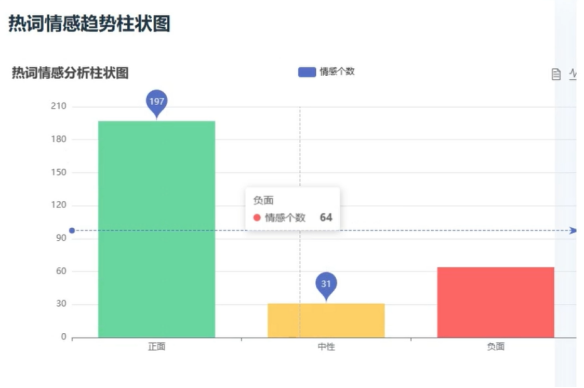
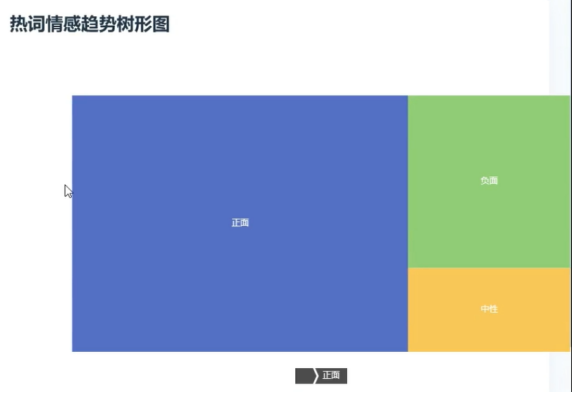
四、部分核心代码
from utils import getPublicData
from datetime import datetime
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw
import numpy as np
import jieba
def getHomeTopLikeCommentsData():
commentsList = getPublicData.getAllCommentsData()
commentsListSorted = list(sorted(commentsList,key=lambda x:int(x[2]),reverse=True))[:4]
return commentsListSorted
def getTagData():
articleData = getPublicData.getAllData()
maxLikeNum = 0
maxLikeAuthorName = ''
cityDic = {}
for article in articleData:
if int(article[1]) > maxLikeNum:
maxLikeNum = int(article[1])
maxLikeAuthorName = article[11]
if article[4] == '无':continue
if cityDic.get(article[4],-1) == -1:
cityDic[article[4]] = 1
else:
cityDic[article[4]] += 1
maxCity = list(sorted(cityDic.items(),key=lambda x:x[1],reverse=True))[0][0]
return len(articleData),maxLikeAuthorName,maxCity
def getCreatedNumEchartsData():
articleData = getPublicData.getAllData()
xData = list(set([x[7] for x in articleData]))
xData = list(sorted(xData,key=lambda x:datetime.strptime(x,'%Y-%m-%d').timestamp(),reverse=True))
yData = [0 for x in range(len(xData))]
for i in articleData:
for index,j in enumerate(xData):
if i[7] == j:
yData[index] += 1
return xData,yData
def getTypeCharData():
allData = getPublicData.getAllData()
typeDic = {}
for i in allData:
if typeDic.get(i[8], -1) == -1:
typeDic[i[8]] = 1
else:
typeDic[i[8]] += 1
resultData = []
for key, value in typeDic.items():
resultData.append({
'name': key,
'value': value,
})
return resultData
def getCommentsUserCratedNumEchartsData():
userData = getPublicData.getAllCommentsData()
createdDic = {}
for i in userData:
if createdDic.get(i[1],-1) == -1:
createdDic[i[1]] =1
else:
createdDic[i[1]] +=1
resultData = []
for key,value in createdDic.items():
resultData.append({
'name':key,
'value':value,
})
return resultData
def stopwordslist():
stopwords = [line.strip() for line in open('./model/stopWords.txt',encoding='UTF-8').readlines()]
return stopwords
def getUserNameWordCloud():
text = ''
stopwords = stopwordslist()
commentsList = getPublicData.getAllCommentsData()
for comment in commentsList:
text += comment[5]
cut = jieba.cut(text)
newCut = []
for word in cut:
if word not in stopwords:newCut.append(word)
string = ' '.join(newCut)
wc = WordCloud(
width=1000, height=600,
background_color='white',
colormap='Blues',
font_path='STHUPO.TTF'
)
wc.generate_from_text(string)
# 绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
# 显示生成的词语图片
# plt.show()
# 输入词语图片到文件
plt.savefig('./static/authorNameCloud.jpg', dpi=500)
获取源码或论文
如需对应的论文或源码,以及其他定制需求,也可以下方微信联系我。


















 1680
1680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









