







文章目录
背景
之前的一个项目, 涉及到前端解析docx文件流为html来做编辑,但是,说实话,前端常用的mammoth库除了文字和图片能提取, 很多样式都会丢,效果看着非常不理想。
最终docx相关功能:通过转pdf进行预览,然后编辑直接不做。
于是,兴趣使然,我尝试使用go语言读取docx文件,使用encoding/xml模块解析docx中的文字和图片,最终输出为html。
仓库介绍
我将此库命名为 docx-to-html-wasm ,当然,只支持简单的段落文字、表格文字以及图片解析。
获取代码
- npm仓库地址:
https://www.npmjs.com/package/docx-to-html-wasm?activeTab=code - 执行
npm view docx-to-html-wasm@1.1.0 dist.tarball可获取
本地体验
## 新建目录 test ,进入
yarn add docx-to-html-wasm@latest
serve -s node_modules/docx-to-html-wasm
## 访问浏览器 127.0.0.1:3000
因为wasm文件的加载是通过fetch请求,所以你需要通过serve启动一个简单的静态网站服务,然后访问127.0.0.1:3000. 如图中的红框所示
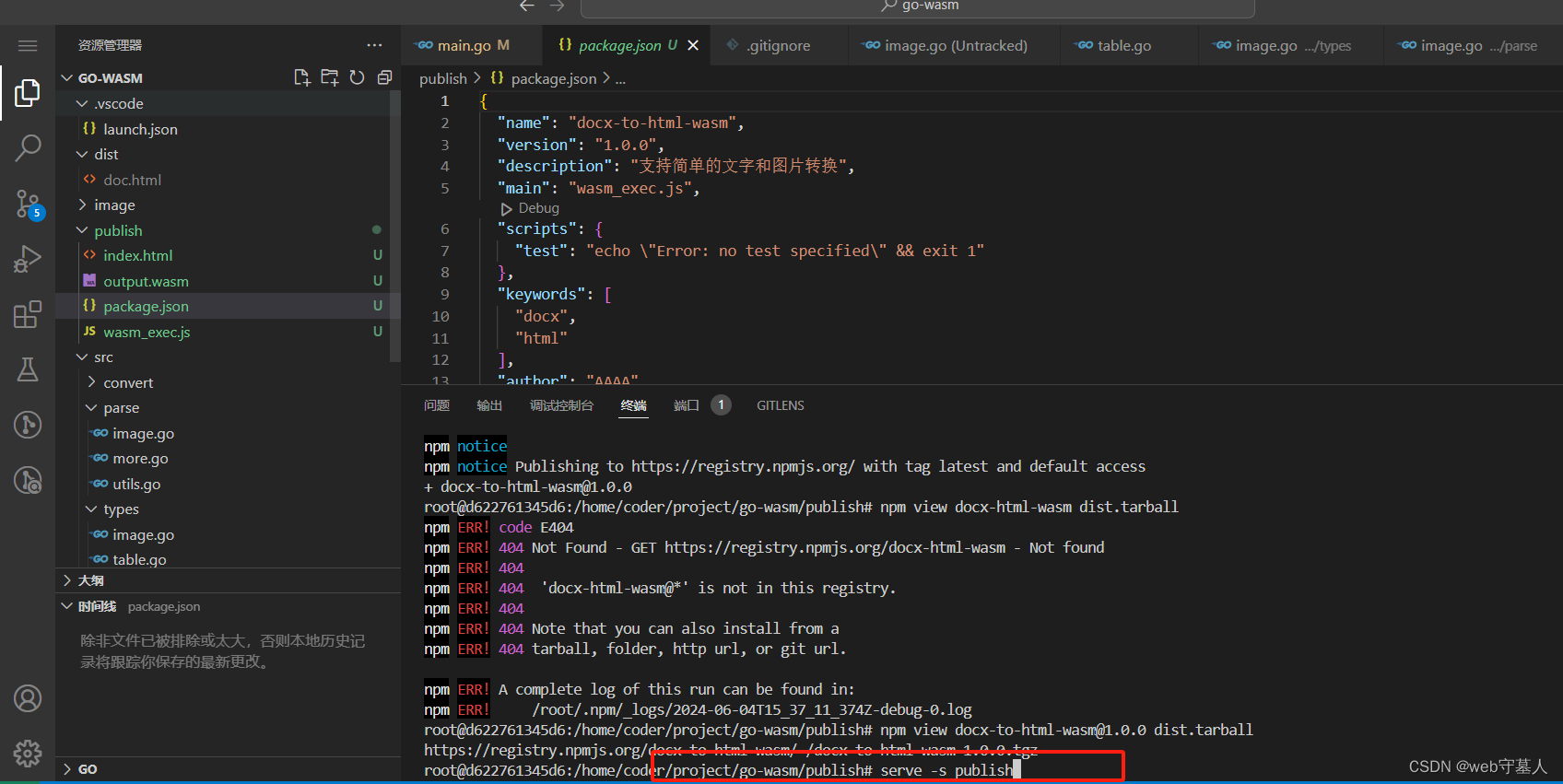
项目效果展示
本地test.docx
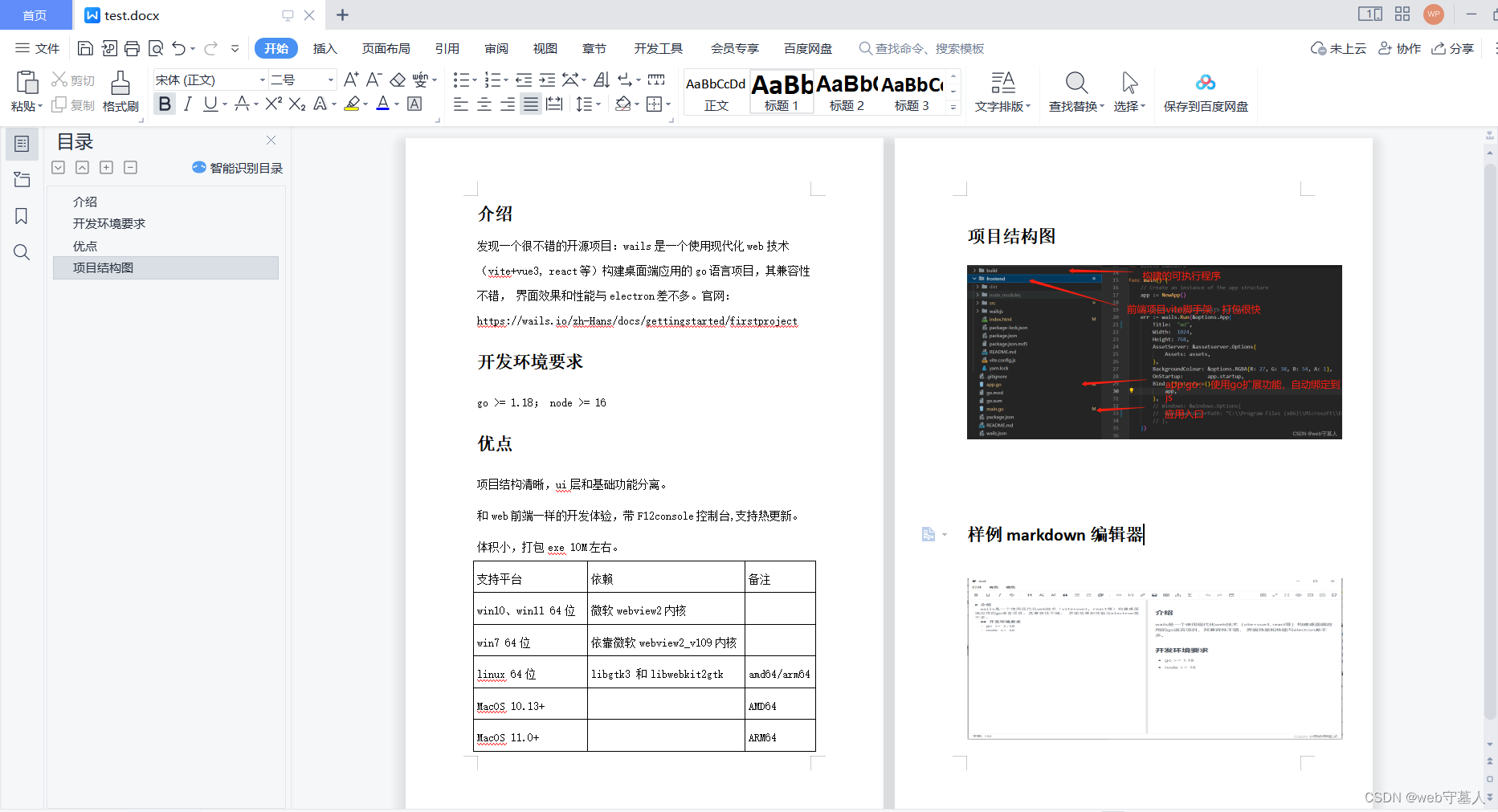
线上解析效果
线上体验
复制访问: https://hilarious-druid-ae567c.netlify.app/
codesandbox
在inscode中体验(1.1.0版本正在审核)
go代码主逻辑展示
go代码写的太烂,只展示main函数。转化逻辑让chatgpt帮你写就行。
- !wasm时,读取docx并转换为html到本地进行预览。
- wasm时,接收前端input传来的文件流(base64编码二进制流,防止文件损坏),解析为html并返回。
//go:build !wasm
// +build !wasm
package main
import (
"encoding/base64"
"fmt"
"go-wasm/src/parse"
"go-wasm/src/utils"
"io/ioutil"
)
func main() {
// 读取docx文件的内容
content, err := ioutil.ReadFile("example.docx")
if err != nil {
fmt.Println("Error reading docx file:", err)
return
}
// 将内容转换为UTF-8编码
utf8Content := string(content)
// 将UTF-8编码的内容进行base64编码
base64Content := base64.StdEncoding.EncodeToString([]byte(utf8Content))
// fmt.Print(base64Content)
// 解码
zipReader := utils.ConvertBase64ToZipReader(base64Content)
html 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









