






 本文详细指导如何在VMwareWorkstationPro中配置CentOS7,安装JDK1.8.0_111和Hadoop2.7.6,包括本地运行模式和完全分布式环境的设置,涉及主机名配置、防火墙管理、密钥对生成、环境变量配置及Hadoop核心组件的安装与调优。
本文详细指导如何在VMwareWorkstationPro中配置CentOS7,安装JDK1.8.0_111和Hadoop2.7.6,包括本地运行模式和完全分布式环境的设置,涉及主机名配置、防火墙管理、密钥对生成、环境变量配置及Hadoop核心组件的安装与调优。
文章目录
- 一、hadoop是什么?
- 二、打开VMware Workstation Pro虚拟机,centos7。
- 三.虚拟机基本配置
- 四、安装jdk1.8.0_111.tar.gz
- 五、安装 Hadoop。
- 六、 本地运行模式。
- 七、完全分布式。
- 1.每台机器分别修改 /etc/hosts 文件,将每个机器的 hostname 和 ip 对应
- 2. xsync 集群分发脚本
- 3.配置Hadoop核心文件 core-site.xml。(在etc的文件下)
- 4.HDFS 配置文件hadoop-env.sh。(在etc的文件下)
- 5. 配置 hdfs-site.xml。(在etc的文件下)
- 6.YARN 配置文件配置 yarn-env.sh。修改 JAVA_HOME 路径:(在etc的文件下)
- 7. 配置 yarn-site.xml。(在etc的文件下)
- 7.MapReduce 配置 mapred-env.sh。(在etc文件下)
- 8.配置 mapred-site.xml.template 。(在etc文件下)
- 9.在集群上分发配置好的 Hadoop 目录
- 10.启动集群
- 总结
一、hadoop是什么?
Hadoop是一个开源的分布式系统基础架构,用于处理和分析大数据。
Hadoop由Apache基金会开发,它使得用户可以在不需要深入了解分布式底层细节的情况下开发分布式程序。Hadoop的核心包括两个主要组件:
HDFS(Hadoop Distributed File System):这是一个分布式文件系统,具有高容错性,设计用来部署在成本较低的硬件上。HDFS提供高吞吐量的数据访问,适合那些需要处理超大数据集的应用程序。
MapReduce:这是一个编程模型,用于处理和生成大数据集。它将计算任务分解成多个小任务,这些小任务可以在Hadoop集群中的多台计算机上并行处理。
Hadoop的优势在于其可伸缩性、高可用性、成本效益以及能够支持多种类型数据的能力。它广泛应用于批处理分析、数据仓库、海量存储、文本挖掘和机器学习等场景。
总的来说,Hadoop是大数据技术中的一个重要组成部分,它的设计理念和实现方式使其成为处理大规模数据集的理想选择。
二、打开VMware Workstation Pro虚拟机,centos7。
1.给虚拟机配置IP。
| 主机名 | IP地址 |
|---|---|
| node1 | 192.168.20.20 |
| node2 | 192.168.20.30 |
| node3 | 192.168.20.40 |
2.打开xshell,并和虚拟机联系。
三.虚拟机基本配置
1.给虚拟机改名。
hostnamectl set-hostname node1 //永久改主机名
2.关闭防火墙
systemctl stop firewalld.service //关闭防火墙
systemctl disable firewalld.service //开机自动关闭防火墙
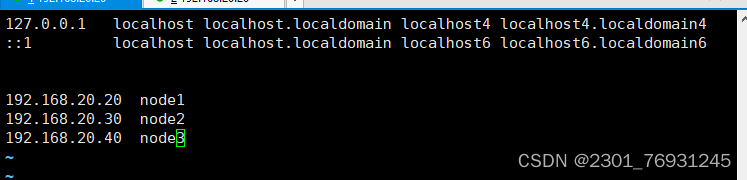
4.每台机器分别修改 /etc/hosts 文件,将每个机器的 hostname 和 ip 对应。
vim /etc/hosts //给三台虚拟机都配置
4.关闭 Selinux。
vim /etc/sysconfig/selinux //把SELINUX=enforcing改成SELINUX=disabled
5. 完成三台虚拟机的ssh的免密登录
- 在node1上生成密钥对
ssh-keygen
Generating public/private rsa key pair. //回车
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase): //回车
Enter same passphrase again: //回车
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is: //回车
SHA256:bmN2uMdGLp0JfxqXyuLTPUnBwggwYnXi2ml7Md/yUbU root@node1
The key's randomart image is:
+---[RSA 2048]----+
| o.=.. |
| . o +. |
| . . o . . |
| o . . o o. . |
| . + o S ...E |
| . . =.o.... |
| . . XO==o. |
| . ++B@== |
| .o*=o . |
+----[SHA256]-----+
2.把node1的生成的公钥文件传送服务器。(把公钥传给了node2,能让它们免密登录)
[root@node1 hadoop]# ssh-copy-id root@192.168.20.30
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host '192.168.20.30 (192.168.20.30)' can't be established.
ECDSA key fingerprint is SHA256:nDM2pphsPC16iVIIXPDRJ5BzUBG0TIWemlG6+xzUO9Q.
ECDSA key fingerprint is MD5:01:94:94:38:13:bf:dd:a1:d9:46:0f:27:5a:d7:5a:96.
Are you sure you want to continue connecting (yes/no)? yes //是 否
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@192.168.20.30's password: //密码
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@192.168.20.30'"
and check to make sure that only the key(s) you wanted were added.
- 2.把node1的生成的公钥文件传送服务器。(把公钥传给了node3,能让它们免密登录)
[root@node1 hadoop]# ssh-copy-id root@192.168.20.40
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host '192.168.20.30 (192.168.20.30)' can't be established.
ECDSA key fingerprint is SHA256:nDM2pphsPC16iVIIXPDRJ5BzUBG0TIWemlG6+xzUO9Q.
ECDSA key fingerprint is MD5:01:94:94:38:13:bf:dd:a1:d9:46:0f:27:5a:d7:5a:96.
Are you sure you want to continue connecting (yes/no)? yes //是 否
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@192.168.20.30's password: //密码
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@192.168.20.30'"
and check to make sure that only the key(s) you wanted were added.
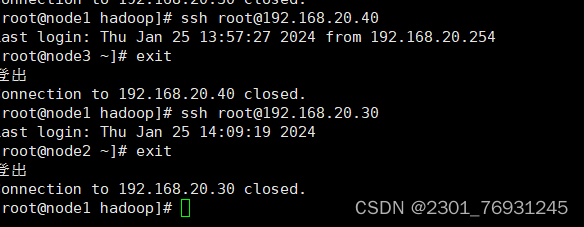
- 测试它们的免密登录
四、安装jdk1.8.0_111.tar.gz
1.用xshell把压缩包上传到centos 7。
- 用rz命令把压缩包上传到根目录。
rz //可以自己设置上传到哪个目录下
2.创建 /usr/local/java 文件夹
mkdir /export/server/ -p //用来存放Java的程序
3.将 jdk 压缩包解压到 /export/server 目录下。
tar -zxvf jdk1.8.0_111.tar.gz -C /export/server/
4.配置jdk的环境变量。
vim /etc/profile
把下面的内容添加到文件的最下面
# JAVA
export JAVA_HOME=//export/server/jdk1.8.0_111
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin
让环境变量的文件生效
source /etc/profile
5.输入 java、javac、java -version 命令,检验 jdk 是否安装成功。(如果我们系统自带了jdk,我们需要卸载)
- 查询已安装的 jdk 有哪些。
rpm -qa | grep jdk
- 删除已经安装的 jdk。
yum remove (上面查询到的名称) -y
- 重新让环境变量的文件生效
source /etc/profile
五、安装 Hadoop。
https://hadoop.apache.org/
1.将 hadoop-2.7.6.tar.gz 安装包通过xshell传到 CentOS 7 上。
2.创建 /export/hadoop 文件夹。
mkdir /export/hadoop //用来存放Hadoop的解压包
3.将 hadoop 压缩包解压到 /haddop 的目录下
tar -zxvf hadoop-2.7.7.tar.gz -C /export/hadoop/ //Hadoop的存放位置
4.配置 hadoop 环境变量
- 进入这个文件。
vim /etc/profile
把下面的内容添加到文件的最下面
#HADOOP
export HADOOP_HOME=/export/hadoop/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.让环境变量的文件生效
source /etc/profile
- 测试是否安装成功。
hadoop version

六、 本地运行模式。
1. 在 hadoop-2.7.6 文件下面创建一个 put 文件夹.。
mkdir put
2. 将 Hadoop 的 xml 配置文件复制到 input。
cp etc/hadoop/*.xml put
3. 在 hadoop-2.7.6 目录下,执行 share 目录下的 MapReduce 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep put/ output 'dfs[a-z.]+'
查看输出结果

4. 在 hadoop-2.7.6 文件下面创建一个 input 文件夹
mkdir input
5.在 input 文件下创建一个 wc.input 文件。
vim wc.input
在文件中输入以下内容:
hadoop yarn
hadoop mapreduce
spark
spark
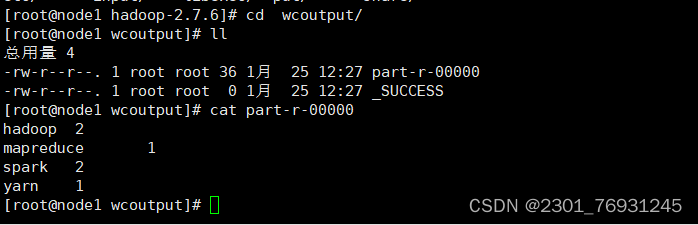
6.在 hadoop-2.7.7 目录下,执行 share 目录下的 MapReduce 程序。
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount input/ wcoutput
查看结果
七、完全分布式。
1.每台机器分别修改 /etc/hosts 文件,将每个机器的 hostname 和 ip 对应
vim /etc/hosts
把下面内容添加文件中
192.168.20.20 node1
192.168.20.30 node2
192.168.20.20 node3
2. xsync 集群分发脚本
1.在 /usr/local/bin 目录下创建 xsync 文件。
vim ccy
在文件中添加以下内容:
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
p1=$1
fname=`basename $p1`
echo fname=$fname
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
user=`whoami`
for i in node1 node2 node3
do
echo "****************** $i *********************"
rsync -rvl $pdir/$fname $user@$i:$pdir
done
- 修改脚本 ccy 具有执行权限
chmod 777 ccy //权限给满
3.配置Hadoop核心文件 core-site.xml。(在etc的文件下)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/hadoop-2.7.6/data/tmp</value>
</property>
</configuration>
4.HDFS 配置文件hadoop-env.sh。(在etc的文件下)
export JAVA_HOME=/export/server/jdk1.8.0_111 //修改JAVA_HOME
5. 配置 hdfs-site.xml。(在etc的文件下)
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node3:50090</value>
</property>
</configuration>
6.YARN 配置文件配置 yarn-env.sh。修改 JAVA_HOME 路径:(在etc的文件下)
export JAVA_HOME=/export/server/jdk1.8.0_111
7. 配置 yarn-site.xml。(在etc的文件下)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node2</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
7.MapReduce 配置 mapred-env.sh。(在etc文件下)
export JAVA_HOME=/export/server/jdk1.8.0_111
8.配置 mapred-site.xml.template 。(在etc文件下)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
9.在集群上分发配置好的 Hadoop 目录
ccy /hadoop/
10.启动集群
1.集群第一次启动的话,需要格式化 NameNode
hadoop namenode -format
2.启动集群
start-dfs.sh
3.jps查看结果
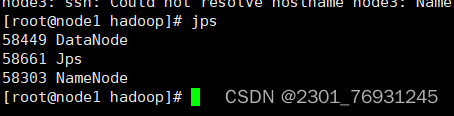
4.配置 slaves(在etc文件下)
vim slaves
下面的内容输入文件
node1 //如果里面有内容就删掉
node2
node3
5. node2,node3同样操作。
- 查看集群
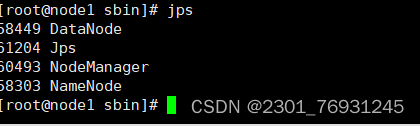
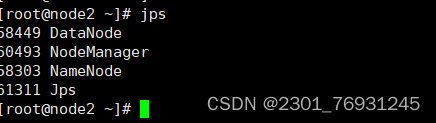
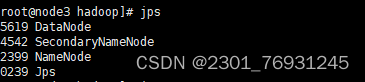
总结
以上就是今天要讲的内容,本文仅仅简单介绍了padoop操作与使用,


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









