







 这篇博客详细介绍了C语言的基础知识,包括hello world程序、gcc编译器、编译方式、计算机中数据的处理(涉及各种进制转换)以及词法符号,适合C语言初学者入门学习。
这篇博客详细介绍了C语言的基础知识,包括hello world程序、gcc编译器、编译方式、计算机中数据的处理(涉及各种进制转换)以及词法符号,适合C语言初学者入门学习。
欢迎小白,大神来参观。。
如果对你有所帮助,可以点个赞,关注一下,后续将持续更新
-----------------目录---------------------
1. hello world 程序说明
2.gcc编译器讲解
3.编译方式....
4.计算机中数据的处理
5.词法符号
下面进入正题:
一、hello world程序说明
#include <stdio.h>
//#开头的行 称为预处理行
//include 是包含头文件的关键字
//<> 里面是头文件的名字
// stdio.h 是标准输入输出的头文件 我们使用 printf就在这个头文件里
// ()圆括号 []方括号 {}花括号 <>尖括号
// int 是函数的返回值类型 ----先不用管
// main 主函数 是程序的入口 每个程序必须有 且只能有1个
// () 里面是main函数的参数----先不用管
// main函数的()里面可以空着不写,但是()必须写
// {}里面是函数体 也就是我们要执行的代码
int main(int argc, const char *argv[]){
//printf是系统给我们提供的输出的函数
//功能是将后面 "" 里面的内容打印到终端
// \n 是换行符 也就是回车的意思
printf("hello world\n"); //C语言的每条指令结尾要有 分号 ;
//函数的返回值 ---先不用管
return 0;
}
// 单行注释
/*
多行
注释
*/
#if 0
多行
注释
#endif二、gcc编译器
编程语言分为 编译型语言 和 解释型语言。
编译型语言:
在执行之前必须要专门有一个编译的过程,编译就是将我们人类能识别的高级语言翻译为机器可以识别的低级语言的过程。编译器就是专门做这个工作的软件。
优点:由于已经提前专门翻译过了,在执行的过程中无需重新翻译,执行的效率相比较高
缺点:依赖于编译器,跨平台性相对性较差
解释型语言:
执行之前无需单独编译,而是在执行的过程中,由解释器逐行的翻译给计算机看的。
也叫脚本语言。
优点:跨平台性相对较好
缺点:每次执行都需要重新翻译,执行效率相对较低
例如:shell python
linux系统中 C语言的编译器是 gcc 编译器
三、编译方式
3.1 简单明了
gcc xxx.c xxx.c是你自己的.c文件名
这种编译方式默认会在当前的路径下生成一个名叫a.out的可执行文件
使用./a.out 就可以执行了
3.2 自定义可执行文件名
gcc xxx.c -o diy_name xxx.c是你自己的.c文件名 diy_name是你定义的可执行文件名
这种编译方式可以生成自定义名字的可执行文件
./自定义的名字 就可以执行了
3.3 按照编译流程分步编译
预处理-->编译-->汇编-->链接
预处理:展开头文件 替换宏定义 删除注释
gcc -E xxx.c -o xxx.i
编译:词法分析、语法分析 说白了就是查错的
如果无误 会生成对应的汇编文件
gcc -S xxx.i -o xxx.s
汇编:将汇编文件生成对应的二进制文件(目标文件)
gcc -c xxx.s -o xxx.o
链接:多个目标文件链接 链接库文件 生成对应的可执行文件
gcc xxx.o -o a.out
四、计算机中数据的处理
计算机能处理的数据分为两大类:数值型数据 非数值型数据
4.1 数值型数据的表示方式
4.1.1 十进制
方便人类识别和处理的
特点:逢10进1 每一位上的数字范围 [0-9]
前导符:没有前导符
例如:100 1234
4.1.2 二进制
方便计算机识别和处理的
特点:逢2进1 每一位上的数字只能是 0 或者 1
前导符:0b
例如:0b1010001 0b1011
二进制转十进制:
0b11101-->从右向左1*2^0+0*2^1+1*2^2 + 1*2^3 + 1*2^4
== 1 + 0 + 4 + 8 + 16
== 29
其他任何进制转10进制都可以使用这种方式,
只不过将底数的2 换成对应进制的数字即可
如果熟练 可以使用 8421转换 ,8421指的是每一位上1的权重
0001 -->1
0010 -->2
0100 -->4
1000 -->8
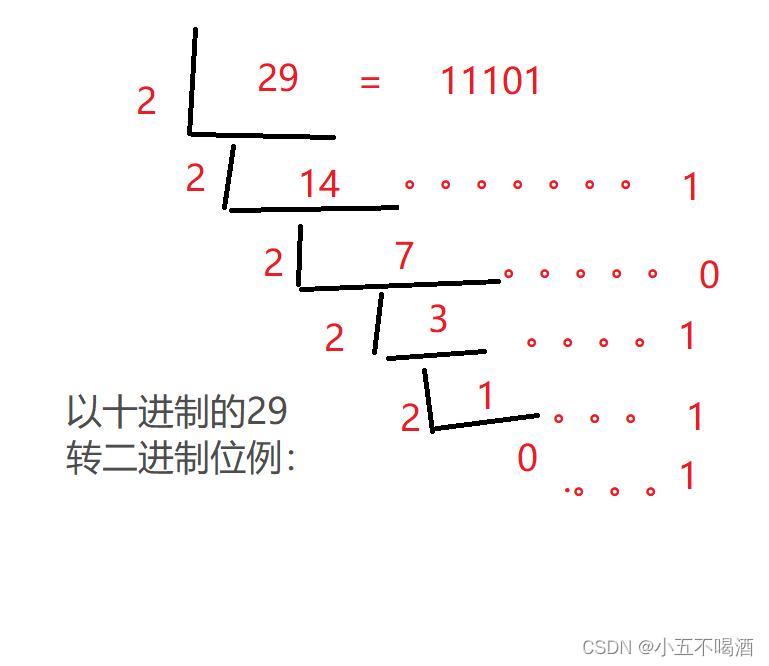
十进制转二进制:
使用辗转相除法(除2取余法)
使用十进制的数据除以2,保留商和余数,然后用商继续除以2,
在保留商和余数,以此类推,直到商为0时结束。
将得到的余数反向取出,就是对应的二进制数了。
4.1.3 八进制
特点:逢8进1 每一位上的数字范围 [0, 7]
前导符:0
例如:0345 0556
八进制转二进制:
方式1:八转十 然后 十转二
方式2:1位八进制对应3位二进制
0357 ---> 0b011101111
二进制转八进制:
从右向左 每3位二进制对应1位八进制,高位不够 补0
0b011010101 ---> 0325
4.1.4 十六进制
特点:逢16进1 每一位上的数字范围 [0, 9] a:10 b:11 c:12 d:13 e:14 f:15
前导符:0x
例如:0xAB12 0x78EF
十六进制转二进制:
方式1:十六转十 然后 十转二
方式2:1位十六进制对应4位二进制
0x78EF ---> 0b0111100011101111
二进制转十六进制:
从右向左 每4位二进制对应1位十六进制,高位不够 补0
0b0001110101010011 ---> 0x1D53
注意:不管几进制的数据,在计算机中都会转换成二进制处理。
例:
#include<stdio.h>
int main(){
// int 是数据类型 是用来定义变量的
// a 是变量名 是自己起的名字
int a = 100; //用十进制的100 给变量a赋值
printf("a = %d\n", a); //%d是十进制的占位符 表示将后面的数据按十进制输出
printf("a = %#o\n", a); //%o是八进制的占位符 # 表示输出前导符
printf("a = %#x\n", a); //%x是十六进制的占位符 # 表示输出前导符
//printf 函数没有输出 二进制的能力
int b = 0b1010110; //用二进制的数据给变量赋值
printf("b = %d b = %#o b = %#x\n", b, b, b);
int c = 0567; //用八进制的数据给变量赋值
printf("c = %d c = %#o c = %#x\n", c, c, c);
int d = 0xAB12; //用十六进制的数据给变量赋值
printf("d = %d d = %#o d = %#x\n", d, d, d);
return 0;
}执行结果:

4.2 非数值型数据的表示形式
计算机中只能处理二进制的数值型数据,但是实际编程的过程中,
也经常会遇到跟多非数值型数据,如人名、企业名、网址 等
"www.baidu.com" "zhangsan" "4399" 'M'
(非数值型数据都是用 单引号或者双引号引起来的)
计算机也需要处理这些非数值型数据,科学家们就发明了一种叫做 ascii 码的东西
使用 man ascii 就可以查看ascii码表 按 q 退出
ascii其实就是规定了 字符 和 整数对应的关系
每个字符都有一个对应的整数,叫做该字符的ascii码
实际使用字符的时候,本质上使用的都是该字符对应的ascii码
常见字符对应的ascii码
'A' ~ 'Z' : 65~90
'a' ~ 'z' : 97~122
'0' ~ '9' : 48~57
'\0' : 0
'\n' : 10
转义字符:
所有字符都可以使用 '\+数字(八进制)' 来表示
除此之外,C语言中还定义一些 '\+字母' 来表示那些无法显示的字符
如 '\n' '\0' '\a' ..
这些就叫做转义字符,因为这些符号已经不是字母本身的含义了。
五、词法符号
5.1 关键字
所谓的关键字就是编译器中已经规定好的一些有特殊含义的单词,直接使用即可。
C语言是严格区分大小写的,关键字都是小写的。
比如下面这些:
char short int long float double signed unsigned struct union enum void
const static extern register volatile auto
typedef
sizeof
if else switch case break default do while goto for continue return 5.2 标识符
所谓的标识符就是我们自己起的名字,变量名、函数名、结构体名、共用体名。。
命名时要符合标识符的命名规范:
1.只能由数字、字母、下划线组成
2.不能以数字开头
3.不能和关键字冲突
尽量做到"望文知意"。
如果你是Linux系统c基础的小白,可以点个关注,c基础完毕还有更进阶的教程
欢迎订阅收藏@

















 2214
2214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









