






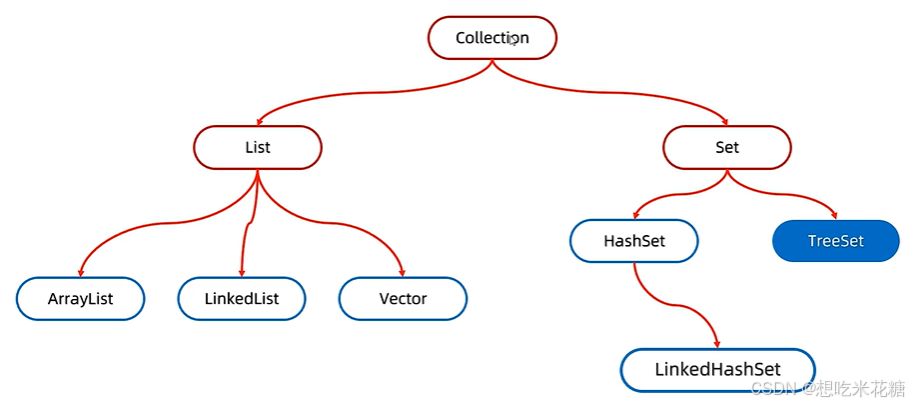

继承于Collection,
add,clear,remove,contains,isEmpty,size
三种遍历
package 集合进阶;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class SetDemo {
public static void main(String[] args) {
Set<String> s = new HashSet<>();
s.add("zhagnsan");
s.add("lisi");
//输出无序的,所以不一定按顺序输出
System.out.println(s);
//1.迭代器
Iterator<String> iterator = s.iterator();
while (iterator.hasNext()){
String s1 = iterator.next();
System.out.println(s1);
}
//2.增强for循环
for (String s1 : s) {
System.out.println(s1);
}
//3.lambda表达式
s.forEach(s1 -> System.out.println(s1));
}
}

HashSet(底层采用哈希表)
哈希表

ptg插件一键生成标准JavaBean
重写hashCode,相同对象输出相同的哈希值
哈希碰撞:不同属性的值查找的哈希值一样
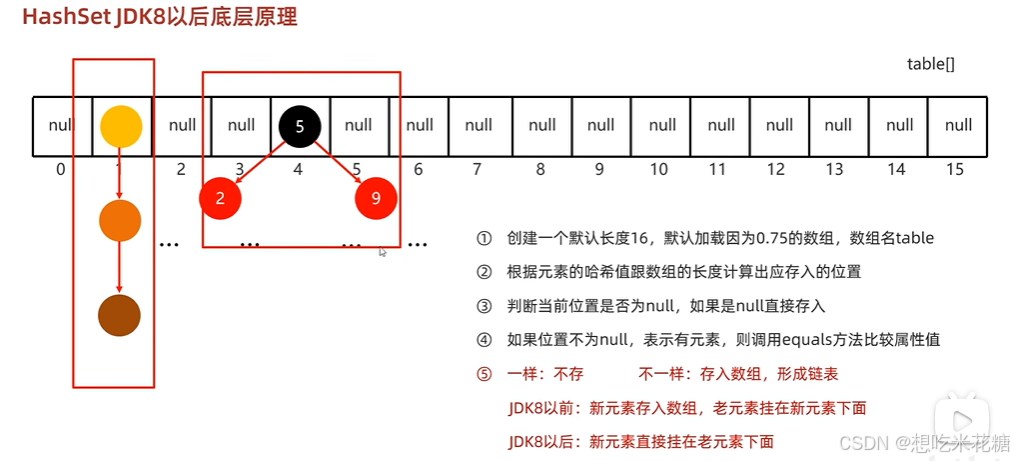
底层原理:链表长度超过8,数组长度大于64,自动转换为红黑树

hashCode,equals底层都是比较的地址值,我们需要的是属性值
重写hashCode的目的:
底层用地址值进行比较,利用属性值计算哈希值
重写equals的目的:比较对象的属性值而不是地址值
1.为什么hashSet存取顺序不一样?
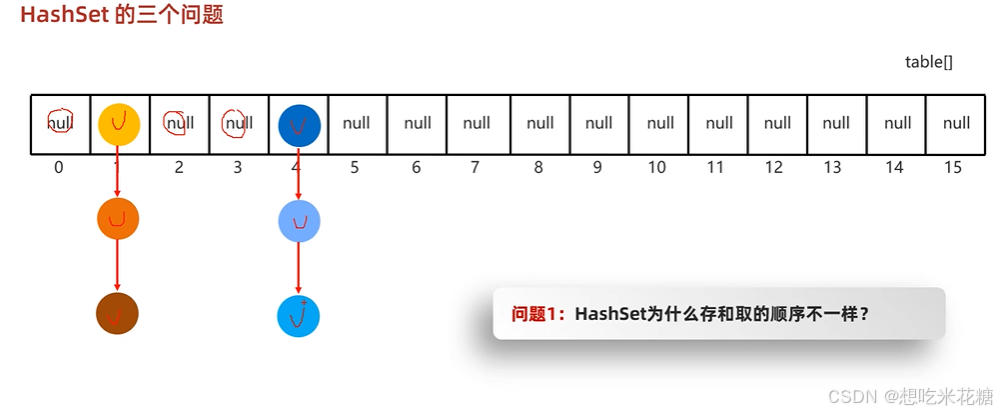
按键填入,但是输出遍历是从头开始
2.hashSet为什么没有索引?
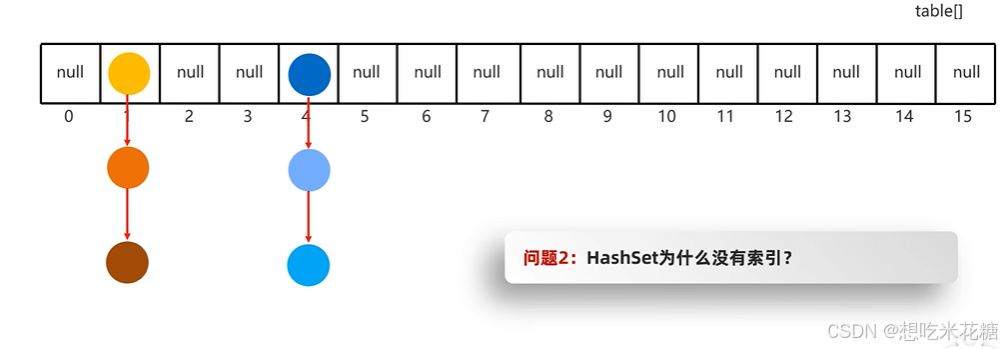
一个位置挂几个,不好区分
3.hashSet利用什么机制保证数据去重?

HashSet首先获取哈希值,然后用equals获取内部属性值
案例:
利用HashSet去除内部重复值
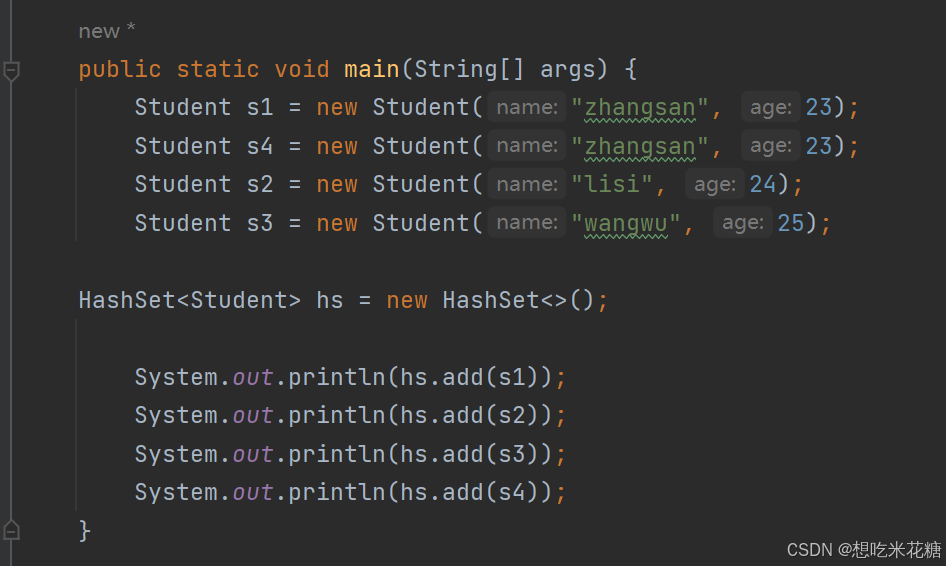
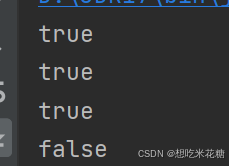
返回false,
HashSet里面如果是自定义对象,要重写hashcode,equals方法来去重
如果是系统定好的结构,不用手动重写
LinkHashSet(相对于hashset有序)
底层原理热盎然是哈希表,但是每个元素额外多了一个双链表机制来记录存储的顺序

保证输入和输出顺序一样
但是使用时候仍然默认用HashSet
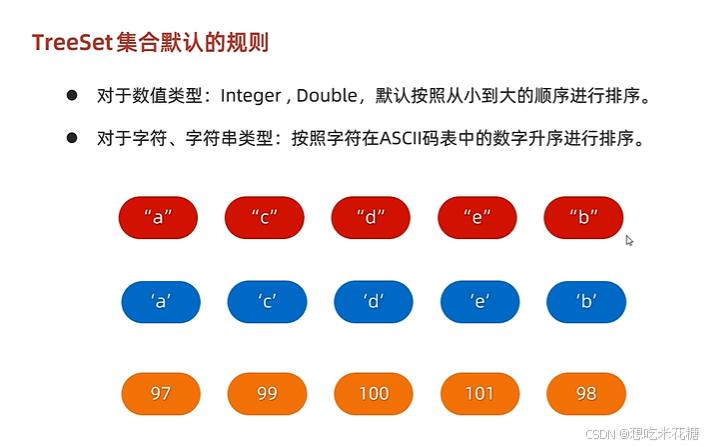
TreeSet
会自动排序从小到大


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









