







模型的评估与选择——交叉验证
1. 交叉验证-模拟1
交叉验证是一种用于估计机器学习模型性能的统计方法。它涉及将数据划分为子集,在一些子集上训练模型,并在剩余的子集上验证模型。这个过程会重复多次,以确保模型的性能是一致的,并且不依赖于特定的数据子集。
以下是最常见的交叉验证技术的简要概述:
-
K折交叉验证:将数据分成
k个大小相等的折叠。模型在k-1个折叠上训练,并在剩余的一个折叠上验证。这个过程重复k次,每个折叠恰好用一次作为验证数据。 -
留一法交叉验证(LOOCV):k折交叉验证的一种特殊情况,其中
k等于数据点的数量。每个数据点恰好用一次作为验证集,模型在剩余的数据上训练。 -
分层K折交叉验证:类似于k折交叉验证,但折叠的创建方式使得每个折叠中的类别比例与原始数据集中的比例相同。这对于不平衡数据集特别有用。
-
时间序列交叉验证:用于时间序列数据,其中数据点的顺序很重要。数据被分成训练和验证集,方式是尊重时间顺序。
以下是使用scikit-learn在Python中进行k折交叉验证的示例:
import numpy as np
from sklearn.model_selection import KFold
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 样本数据
X = np.random.rand(100, 5)
y = np.random.rand(100)
# K折交叉验证
kf = KFold(n_splits=5)
model = LinearRegression()
mse_scores = []
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse_scores.append(mean_squared_error(y_test, y_pred))
print("每个折叠的均方误差:", mse_scores)
print("平均均方误差:", np.mean(mse_scores))
这段代码演示了如何执行k折交叉验证来评估线性回归模型的性能。
#生成数据
# 模拟1
import random
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
nq=5000
Q=np.empty((50,nq))
for i in range(50):
for j in range(nq):
Q[i,j]=random.gauss(0,1)
N1=np.zeros(25)
N2=np.ones(25)
N=np.hstack((N1,N2))
random.shuffle(N) #打乱成数组或列表
# 交叉验证
b=np.empty(nq)
nc=100
for i in range(nq):
b[i]=np.corrcoef(N,Q[:,i])[0,1]
Index=np.argsort(-b)[:nc] #-b表示降序排列
vnames=['V'+str(i) for i in np.arange(2,102)]
nnames=['N']+vnames
mydata=np.hstack((np.array([N]).T,Q[:,Index]))
N=mydata[:,0]
tt=np.arange(50).reshape((5,10))
cv_error=np.zeros(50)
cv_true=np.zeros(5)
final_cv=np.zeros(50)
final_corr=np.zeros((nc,5,50))
rowIndex=np.arange(len(mydata))
for t in range(50):
random.shuffle(rowIndex)
mydata=mydata[rowIndex,:]
for j in range(5):
test_row=np.zeros(len(mydata),dtype=bool)
test_row[tt[j,:]]=1
train=mydata[~test_row,1:]
test=mydata[test_row,1:]
testN=mydata[test_row,0]
knn=KNeighborsClassifier(n_neighbors=1)
knn.fit(train,mydata[~test_row,0])
knn_pred=knn.predict(test)
cv_true[j]=np.mean(knn_pred==testN)
for k in range(nc):
final_corr[k,j,t]=np.corrcoef(testN,test[:,k])[0,1]
final_cv[t]=np.mean(cv_true)
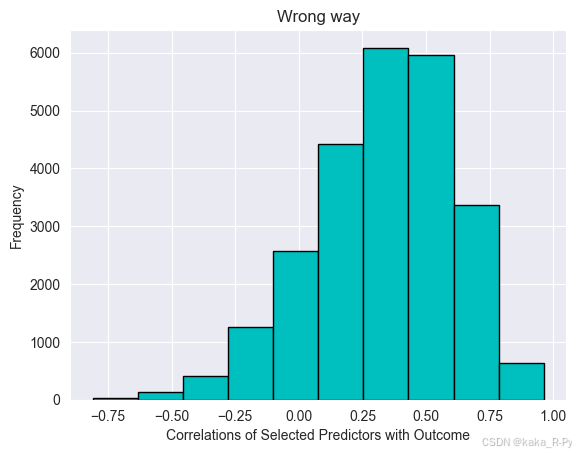
1-np.mean(final_cv) #0.028000000000000025
np.mean(final_corr) #0.33660313986593321
a,b,c=final_corr.shape
ax=plt.figure()
plt.hist(final_corr.reshape((a*b*c)),color='c',edgecolor='k')
plt.ylabel('Frequency')
plt.xlabel('Correlations of Selected Predictors with Outcome')
plt.title('Wrong way')
plt.show()
提升CV交叉验证性能
# Cross-validation
b = np.empty(nq)
nc = 100
for i in range(nq):
b[i] = np.corrcoef(N, Q[:, i])[0, 1]
Index = np.argsort(-b)[:nc] # -b indicates descending order
vnames = ['V' + str(i) for i in np.arange(2, 102)]
nnames = ['N'] + vnames
mydata = np.hstack((np.array([N]).T, Q[:, Index]))
N = mydata[:, 0]
tt = np.arange(50).reshape((5, 10))
cv_error = np.zeros(50)
cv_true = np.zeros(5)
final_cv = np.zeros(50)
final_corr = np.zeros((nc, 5, 50))
rowIndex = np.arange(len(mydata))
for t in range(50):
random.shuffle(rowIndex)
mydata = mydata[rowIndex, :]
for j in range(5):
test_row = np.zeros(len(mydata), dtype=bool)
test_row[tt[j, :]] = True
train = mydata[~test_row, 1:]
test = mydata[test_row, 1:]
testN = mydata[test_row, 0]
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(train, mydata[~test_row, 0])
knn_pred = knn.predict(test)
cv_true[j] = np.mean(knn_pred == testN)
for k in range(nc):
corr = np.corrcoef(testN, test[:, k])[0, 1]
if np.isnan(corr):
corr = 0 # Handle NaN values
final_corr[k, j, t] = corr
final_cv[t] = np.mean(cv_true)
print('1 - np.mean(final_cv):',1 - np.mean(final_cv)) # 0.028000000000000025
print('mean(final_corr):',np.mean(final_corr)) # 0.33660313986593321
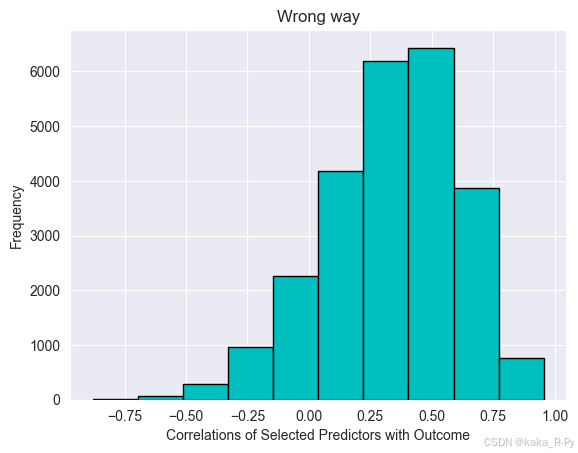
a, b, c = final_corr.shape
ax = plt.figure()
plt.hist(final_corr.reshape((a * b * c)), color='c', edgecolor='k')
plt.ylabel('Frequency')
plt.xlabel('Correlations of Selected Predictors with Outcome')
plt.title('Wrong way')
plt.show()
1 - np.mean(final_cv): 0.029200000000000004
mean(final_corr): 0.3382989939109606
2. 交叉验证-模拟2
# 模拟2
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
nq=500
Q=np.empty((20,nq))
for i in range(20):
for j in range(nq):
Q[i,j]=random.gauss(0,1)
N1=['No']*10
N2=['Yes']*10
N=N1+N2
random.shuffle(N) #打乱数组或列表
cv_scores=[]
for i in range(nq):
clf=DecisionTreeClassifier(random_state=14)
clf.fit(Q[:,i].reshape(20,1),N)
cv_scores.append(np.mean(
cross_val_score(clf,Q[:,i].reshape(20,1),
N,scoring='accuracy',cv=5)))
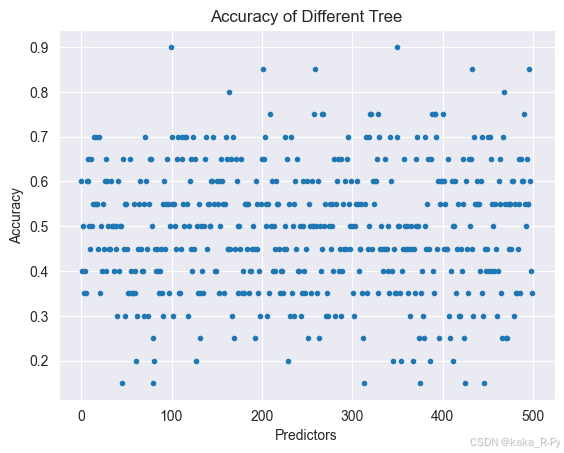
plt.plot(cv_scores,'.')
plt.xlabel('Predictors')
plt.ylabel('Accuracy')
plt.title('Accuracy of Different Tree')
plt.show()
loc=np.where(cv_scores==np.max(cv_scores))[0][0]
err_test=[]
for i in range(50):
random.shuffle(N)
clf=DecisionTreeClassifier(random_state=14)
err_test.append(1-np.mean(
cross_val_score(clf,Q[:,loc].reshape(20,1),
N,scoring='accuracy',cv=5)))
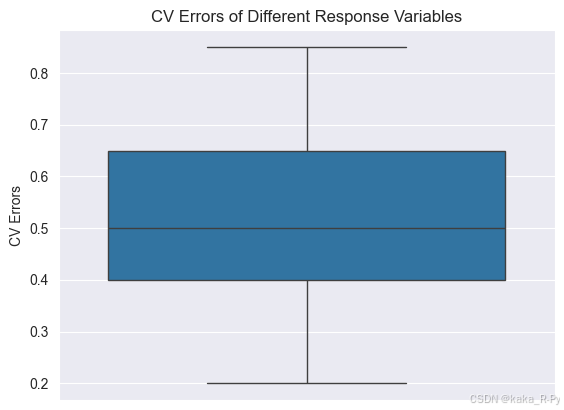
import seaborn as sns
sns.boxplot(err_test,orient='v')
plt.ylabel('CV Errors')
plt.title('CV Errors of Different Response Variables')
plt.show()




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











