import pandas as pd
import seaborn as sns
import matplotlib. pyplot as plt
plt. rcParams[ 'font.sans-serif' ] = [ 'SimHei' ]
plt. rcParams[ 'axes.unicode_minus' ] = False
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
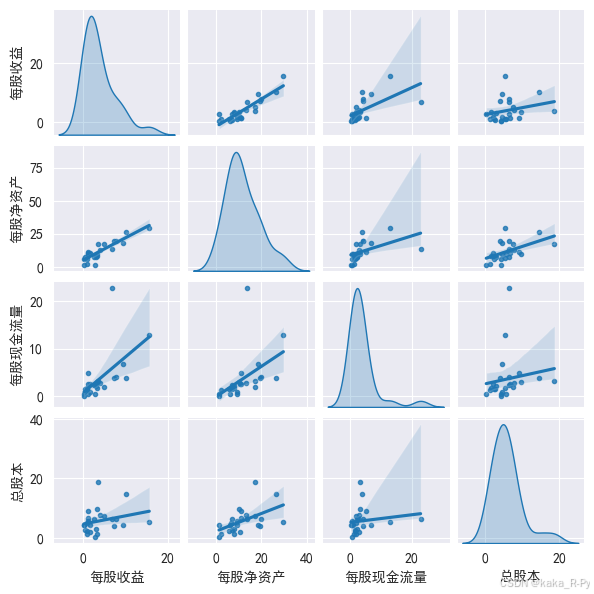
sns. pairplot( df[ [ '每股收益' , '每股净资产' , '每股现金流量' , '总股本' ] ] ,
height= 1.5 , diag_kind= 'kde' , markers= '.' , kind= 'reg' )
<seaborn.axisgrid.PairGrid at 0x1a3192da490>
import pandas as pd
from scipy. stats import pearsonr
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
corr = df. iloc[ : , 1 : ] . corr( )
corr
每股收益 每股净资产 每股现金流量 总股本 每股收益 1.000000 0.886292 0.598971 0.254539 每股净资产 0.886292 1.000000 0.482134 0.521195 每股现金流量 0.598971 0.482134 1.000000 0.147115 总股本 0.254539 0.521195 0.147115 1.000000
import pandas as pd
from scipy. stats import pearsonr
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
col = [ '每股收益' , '每股净资产' , '每股现金流量' , '总股本' ]
df_pvalue = pd. DataFrame( index= col, columns= col)
for i in range ( 1 , 5 ) :
for j in range ( 1 , 5 ) :
cor, p_value = pearsonr( df. iloc[ : , i] , df. iloc[ : , j] )
df_pvalue. iloc[ i- 1 , j- 1 ] = p_value
df_pvalue
每股收益 每股净资产 每股现金流量 总股本 每股收益 0.0 0.0 0.001558 0.21949 每股净资产 0.0 0.0 0.01466 0.007548 每股现金流量 0.001558 0.01466 0.0 0.482835 总股本 0.21949 0.007548 0.482835 0.0
import pandas as pd
from statsmodels. formula. api import ols
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
model1 = ols( "每股收益~每股净资产" , data= df) . fit( )
print ( model1. summary( ) )
OLS Regression Results
==============================================================================
Dep. Variable: 每股收益 R-squared: 0.786
Model: OLS Adj. R-squared: 0.776
Method: Least Squares F-statistic: 84.23
Date: Thu, 14 Nov 2024 Prob (F-statistic): 3.76e-09
Time: 16:26:22 Log-Likelihood: -49.130
No. Observations: 25 AIC: 102.3
Df Residuals: 23 BIC: 104.7
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -1.6700 0.698 -2.392 0.025 -3.115 -0.225
每股净资产 0.4675 0.051 9.178 0.000 0.362 0.573
==============================================================================
Omnibus: 1.134 Durbin-Watson: 1.993
Prob(Omnibus): 0.567 Jarque-Bera (JB): 1.082
Skew: 0.419 Prob(JB): 0.582
Kurtosis: 2.420 Cond. No. 26.7
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
from statsmodels. stats. anova import anova_lm
anova_lm( model1, typ= 1 )
df sum_sq mean_sq F PR(>F) 每股净资产 1.0 272.995423 272.995423 84.233159 3.760409e-09 Residual 23.0 74.541841 3.240950 NaN NaN
pow ( 3.240950 , 1 / 2 )
1.800263869548017
import pandas as pd
from statsmodels. formula. api import ols
from statsmodels. stats. outliers_influence import summary_table
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
model1 = ols( "每股收益~每股净资产" , data= df) . fit( )
conf_level = 0.95
st, _, _ = summary_table( model1, alpha= 1 - conf_level)
columns = [ x + ' ' + y for ( x, y) in zip ( st. data[ 0 ] , st. data[ 1 ] ) ]
df_res = pd. DataFrame( )
for i in range ( len ( st. data) - 2 ) :
df_res = pd. concat( [ df_res, pd. DataFrame( st. data[ i+ 2 ] , index= columns) . T] , ignore_index= True )
df_res. reset_index( drop= True , inplace= True )
round ( df_res, 2 ) . head( )
Obs Dep Var Population Predicted Value Std Error Mean Predict Mean ci 95% low Mean ci 95% upp Predict ci 95% low Predict ci 95% upp Residual Std Error Residual Student Residual Cook's D 0 1.0 0.88 1.07 0.47 0.10 2.04 -2.78 4.92 -0.19 1.74 -0.11 0.00 1 2.0 1.14 3.53 0.36 2.79 4.28 -0.27 7.33 -2.39 1.76 -1.36 0.04 2 3.0 4.88 6.42 0.46 5.47 7.36 2.57 10.26 -1.54 1.74 -0.88 0.03 3 4.0 3.23 2.11 0.41 1.27 2.95 -1.71 5.92 1.12 1.75 0.64 0.01 4 5.0 7.83 7.67 0.55 6.52 8.81 3.77 11.56 0.16 1.71 0.10 0.00
注:Python没有计算样本外点的置信区间和预测区间的函数,只能根据样本内的点绘制置信区间和预测区间图。
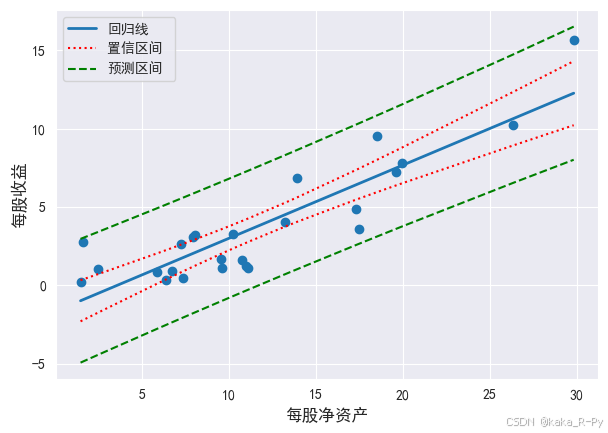
import matplotlib. pyplot as plt
plt. rcParams[ 'font.sans-serif' ] = [ 'SimHei' ]
df_res[ '每股净资产' ] = df[ '每股净资产' ]
df_plot = df_res. sort_values( by= '每股净资产' )
df_plot. reset_index( drop= True , inplace= True )
plt. figure( figsize= ( 7 , 4.8 ) )
plt. scatter( df_plot[ '每股净资产' ] , df_plot[ 'Dep Var Population' ] )
p1, = plt. plot( df_plot[ '每股净资产' ] , df_plot[ 'Predicted Value' ] , linewidth= 2 )
p2, = plt. plot( df_plot[ '每股净资产' ] , df_plot[ 'Mean ci 95% low' ] , 'r:' )
p3, = plt. plot( df_plot[ '每股净资产' ] , df_plot[ 'Mean ci 95% upp' ] , 'r:' )
p4, = plt. plot( df_plot[ '每股净资产' ] , df_plot[ 'Predict ci 95% low' ] , 'g--' )
p5, = plt. plot( df_plot[ '每股净资产' ] , df_plot[ 'Predict ci 95% upp' ] , 'g--' )
plt. xlabel( '每股净资产' , size= 12 )
plt. ylabel( '每股收益' , size= 12 )
plt. legend( [ p1, p3, p5] , [ '回归线' , '置信区间 ' , '预测区间' ] )
<matplotlib.legend.Legend at 0x1a319956810>
model1. predict( exog= dict ( 每股净资产= 10 ) )
0 3.004632
dtype: float64
import pandas as pd
import numpy as np
from statsmodels. formula. api import ols
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
model1 = ols( "每股收益~每股净资产" , data= df) . fit( )
df= pd. DataFrame( { "样本编号" : df[ '样本编号' ] , "每股收益" : df[ '每股收益' ] ,
"点预测值" : model1. fittedvalues, "残差" : model1. resid,
"标准化残差" : np. array( model1. resid_pearson) } )
round ( df, 4 ) . head( )
样本编号 每股收益 点预测值 残差 标准化残差 0 1 0.88 1.0693 -0.1893 -0.1052 1 2 1.14 3.5329 -2.3929 -1.3292 2 3 4.88 6.4171 -1.5371 -0.8538 3 4 3.23 2.1071 1.1229 0.6237 4 5 7.83 7.6653 0.1647 0.0915
import pandas as pd
import numpy as np
from statsmodels. formula. api import ols
import statsmodels. api as sm
import matplotlib. pyplot as plt
plt. rcParams[ 'font.sans-serif' ] = [ 'SimHei' ]
plt. rcParams[ 'axes.unicode_minus' ] = False
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
model1 = ols( "每股收益~每股净资产" , data= df) . fit( )
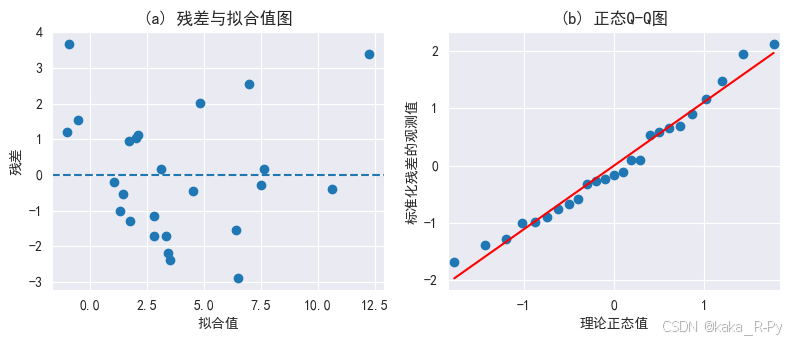
plt. subplots( 1 , 2 , figsize= ( 8 , 3.5 ) )
plt. subplot( 121 )
plt. scatter( model1. fittedvalues, model1. resid)
plt. xlabel( '拟合值' )
plt. ylabel( '残差' )
plt. title( '(a) 残差与拟合值图' , fontsize= 12 )
plt. axhline( 0 , ls= '--' )
ax2 = plt. subplot( 122 )
pplot = sm. ProbPlot( model1. resid, fit= True )
pplot. qqplot( line= 'r' , ax= ax2, xlabel= '理论正态值' , ylabel= '标准化残差的观测值' )
ax2. set_title( '(b) 正态Q-Q图' , fontsize= 12 )
plt. tight_layout( )
plt. show( )
from statsmodels. formula. api import ols
import pandas as pd
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
model_m = ols( "每股收益~每股净资产+每股现金流量+总股本" , data= df) . fit( )
print ( model_m. summary( ) )
OLS Regression Results
==============================================================================
Dep. Variable: 每股收益 R-squared: 0.871
Model: OLS Adj. R-squared: 0.853
Method: Least Squares F-statistic: 47.41
Date: Thu, 14 Nov 2024 Prob (F-statistic): 1.58e-09
Time: 16:26:24 Log-Likelihood: -42.740
No. Observations: 25 AIC: 93.48
Df Residuals: 21 BIC: 98.35
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -1.1167 0.597 -1.870 0.076 -2.359 0.125
每股净资产 0.4903 0.055 8.891 0.000 0.376 0.605
每股现金流量 0.1505 0.072 2.091 0.049 0.001 0.300
总股本 -0.2381 0.086 -2.783 0.011 -0.416 -0.060
==============================================================================
Omnibus: 0.628 Durbin-Watson: 1.992
Prob(Omnibus): 0.730 Jarque-Bera (JB): 0.697
Skew: 0.213 Prob(JB): 0.706
Kurtosis: 2.301 Cond. No. 32.1
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
from statsmodels. stats. anova import anova_lm
anova_lm( model_m, typ= 1 )
df sum_sq mean_sq F PR(>F) 每股净资产 1.0 272.995423 272.995423 128.229092 2.105681e-10 每股现金流量 1.0 13.342307 13.342307 6.267035 2.062595e-02 总股本 1.0 16.491240 16.491240 7.746125 1.114149e-02 Residual 21.0 44.708294 2.128966 NaN NaN
pow ( 2.128966 , 1 / 2 )
1.459097666367814
import pandas as pd
from statsmodels. formula. api import ols
from scipy import stats
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
df. drop( [ '样本编号' ] , axis= 1 , inplace= True )
z = stats. zscore( df, ddof= 1 )
df. columns = [ 'z每股收益' , 'z每股净资产' , 'z每股现金流量' , 'z总股本' ]
print ( df. head( ) )
model_m = ols( "z每股收益~z每股净资产+z每股现金流量+z总股本" , data= df) . fit( )
print ( '====================================================================' )
print ( model_m. summary( ) )
z每股收益 z每股净资产 z每股现金流量 z总股本
0 0.88 5.86 1.50 2.28
1 1.14 11.13 4.95 9.09
2 4.88 17.30 1.93 7.37
3 3.23 8.08 1.80 1.45
4 7.83 19.97 4.13 6.32
====================================================================
OLS Regression Results
==============================================================================
Dep. Variable: z每股收益 R-squared: 0.871
Model: OLS Adj. R-squared: 0.853
Method: Least Squares F-statistic: 47.41
Date: Thu, 14 Nov 2024 Prob (F-statistic): 1.58e-09
Time: 16:42:30 Log-Likelihood: -42.740
No. Observations: 25 AIC: 93.48
Df Residuals: 21 BIC: 98.35
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -1.1167 0.597 -1.870 0.076 -2.359 0.125
z每股净资产 0.4903 0.055 8.891 0.000 0.376 0.605
z每股现金流量 0.1505 0.072 2.091 0.049 0.001 0.300
z总股本 -0.2381 0.086 -2.783 0.011 -0.416 -0.060
==============================================================================
Omnibus: 0.628 Durbin-Watson: 1.992
Prob(Omnibus): 0.730 Jarque-Bera (JB): 0.697
Skew: 0.213 Prob(JB): 0.706
Kurtosis: 2.301 Cond. No. 32.1
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
import pandas as pd
from statsmodels. formula. api import ols
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
model_m = ols( "每股收益~每股净资产+每股现金流量+总股本" , data= df) . fit( )
def vif ( df_exog, exog_name) :
exog_use = list ( df_exog. columns)
exog_use. remove( exog_name)
model_m = ols( f" { exog_name} ~ { '+' . join( list ( exog_use) ) } " , data= df_exog) . fit( )
rsq = model_m. rsquared
return 1 . / ( 1 . - rsq)
df_vif = pd. DataFrame( )
for x in [ '每股净资产' , '每股现金流量' , '总股本' ] :
vif_i = vif( df. iloc[ : , 2 : ] , x)
df_vif. loc[ 'VIF' , x] = vif_i
df_vif. loc[ "tolerance" ] = 1 / df_vif. loc[ 'VIF' ]
df_vif
每股净资产 每股现金流量 总股本 VIF 1.784684 1.328641 1.400132 tolerance 0.560323 0.752649 0.714218
import pandas as pd
from statsmodels. formula. api import ols
from statsmodels. stats. outliers_influence import summary_table
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
model_m = ols( "每股收益~每股净资产+每股现金流量+总股本" , data= df) . fit( )
conf_level = 0.95
st, _, _ = summary_table( model_m, alpha= 1 - conf_level)
columns = [ x + ' ' + y for ( x, y) in zip ( st. data[ 0 ] , st. data[ 1 ] ) ]
df_res = pd. DataFrame( )
for i in range ( len ( st. data) - 2 ) :
df_res = pd. concat( [ df_res, pd. DataFrame( st. data[ i+ 2 ] , index= columns) . T] , ignore_index= True )
df_res. reset_index( drop= True , inplace= True )
df_res. drop( columns= [ 'Std Error Mean Predict' ,
'Student Residual' , 'Std Error Residual' ] , inplace= True )
round ( df_res, 2 ) . head( )
Obs Dep Var Population Predicted Value Mean ci 95% low Mean ci 95% upp Predict ci 95% low Predict ci 95% upp Residual Cook's D 0 1.0 0.88 1.44 0.59 2.29 -1.71 4.59 -0.56 0.00 1 2.0 1.14 2.92 1.99 3.85 -0.25 6.09 -1.78 0.04 2 3.0 4.88 5.90 4.97 6.83 2.73 9.08 -1.02 0.01 3 4.0 3.23 2.77 1.87 3.67 -0.40 5.94 0.46 0.00 4 5.0 7.83 7.79 6.74 8.84 4.58 11.00 0.04 0.00
model_m. predict( exog= dict ( 每股净资产= 5 , 每股现金流量= 5 , 总股本= 5 ) )
0 0.896996
dtype: float64
import pandas as pd
import numpy as np
from statsmodels. formula. api import ols
import statsmodels. api as sm
import matplotlib. pyplot as plt
plt. rcParams[ 'font.sans-serif' ] = [ 'SimHei' ]
plt. rcParams[ 'axes.unicode_minus' ] = False
df = pd. read_csv( './pydata/example/chap10/example10_1.csv' )
model_m = ols( "每股收益~每股净资产+每股现金流量+总股本" , data= df) . fit( )
x = model_m. fittedvalues; y = model_m. resid
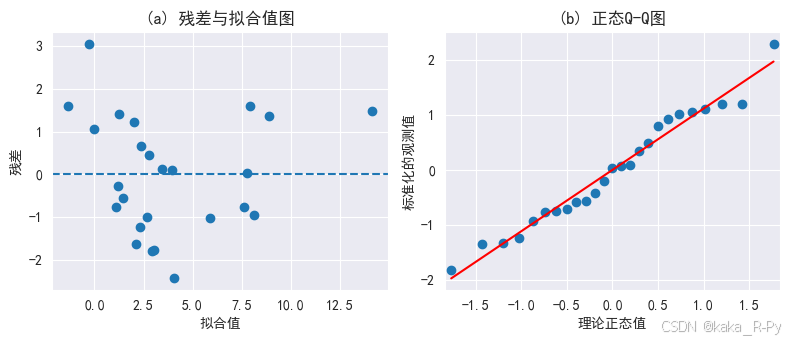
plt. subplots( 1 , 2 , figsize= ( 8 , 3.5 ) )
plt. subplot( 121 )
plt. scatter( model_m. fittedvalues, model_m. resid)
plt. xlabel( '拟合值' )
plt. ylabel( '残差' )
plt. title( '(a) 残差与拟合值图' , fontsize= 12 )
plt. axhline( 0 , ls= '--' )
ax2 = plt. subplot( 122 )
pplot = sm. ProbPlot( model_m. resid, fit= True )
pplot. qqplot( line= 'r' , ax= ax2, xlabel= '理论正态值' , ylabel= '标准化的观测值' )
ax2. set_title( '(b) 正态Q-Q图' , fontsize= 12 )
plt. tight_layout( )
plt. show( )

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











