







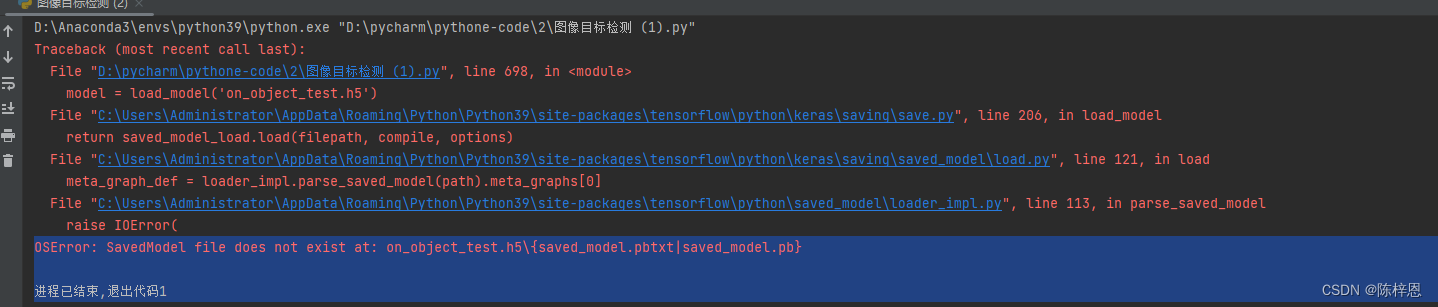
 博主在尝试运行使用CNN的模型时遇到OSError,问题指向SavedModel文件不存在。博客中提供了源代码,并提到数据集为Pascal VOC Dataset Mirror,期待读者提供解决方案。
博主在尝试运行使用CNN的模型时遇到OSError,问题指向SavedModel文件不存在。博客中提供了源代码,并提到数据集为Pascal VOC Dataset Mirror,期待读者提供解决方案。
请大佬看看是什么问题,太头疼了,源代码如下
源代码如下数据集:Pascal VOC Dataset Mirror
import os
import sys
import xml.etree.ElementTree as ET
import cv2
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 不显示等级2以下的提示信息
import tensorflow as tf
from tensorflow.python.keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense, Reshape, Concatenate, \
concatenate, ZeroPadding2D, Convolution2D,BatchNormalization, Activation, AveragePooling2D, Add
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.losses import categorical_crossentropy,binary_crossentropy
import numpy as np
from tensorflow.python.keras.saving.save import load_model
from tensorflow.python.ops.init_ops_v2 import glorot_uniform
from tensorflow.python.ops.losses.losses_impl import mean_squared_error
batch_size=32
input_size=224
# https://juejin.cn/post/6844903908570054670
xmls_path='E:\\VOCdevkit\\VOC2007\\Annotations'
imgs_path='E:\\VOCdevkit\\VOC2007\\JPEGImages'
catalogs=['aeroplane','bicycle','bird','boat','bottle','bus','car','cat','chair','cow','diningtable','dog','horse','motorbike','person','pottedplant','sheep','sofa','train','tvmonitor']
# region 对图片和标签进行预处理,使用迭代器处理整个过程
def generator_data():
global batch_size
annotations = os.listdir(xmls_path)
# 随机打乱
np.random.shuffle(annotations)
images=[]
classes=[]
labels=[]
while True:
for anno in annotations:
anno_path = os.path.join(xmls_path,anno)
tree = ET.parse(anno_path)
root = tree.getroot()
# 图片名称
img_name = root.find('filename').text
width = int(root.find('size/width').text)
height = int(root.find('size/height').text)
obj_name = root.find('object/name').text
xmin = int(root.find('object/bndbox/xmin').text)
ymin = int(root.find('object/bndbox/ymin').text)
xmax = int(root.find('object/bndbox/xmax').text)
ymax = int(root.find('object/bndbox/ymax').text)
label = [xmin,ymin,xmax,ymax]
# size=[width,height]
# x1, y1, x2, y2 = label
# if y1 >= y2:
# print(anno_path, label)
# break
img_path = os.path.join(imgs_path, img_name)
if os.path.exists(img_path):
image = cv2.imread(img_path)
image , label = image_plus(image,label)
# 设置image 的resize 为input_size
image = cv2.resize(image,(input_size,input_size))
label = fix_label_scale(label,[height,width])
label = convert_to_mse(label)
obj_catalog=np.zeros(dtype=float,shape=len(catalogs))
obj_catalog_idx=catalogs.index(obj_name)
obj_catalog[obj_catalog_idx]=1
classes.append(obj_catalog)
images.append(image)
labels.append(label)
if(len(images)>=batch_size):
yield (np.array(images),{'class_head':np.array(classes), 'reg_head':np.array(labels)})
images= []
labels=[]
classes=[]
def generator_vaild_data():
global batch_size
annotations = os.listdir(xmls_path)
# 随机打乱
np.random.shuffle(annotations)
images=[]
classes=[]
labels=[]
while True:
for anno in annotations:
anno_path = os.path.join(xmls_path,anno)
tree = ET.parse(anno_path)
root = tree.getroot()
# 图片名称
img_name = root.find('filename').text
width = int(root.find('size/width').text)
height = int(root.find('size/height').text)
obj_name = root.find('object/name').text
xmin = int(root.find('object/bndbox/xmin').text)
ymin = int(root.find('object/bndbox/ymin').text)
xmax = int(root.find('object/bndbox/xmax').text)
ymax = int(root.find('object/bndbox/ymax').text)
label = [xmin,ymin,xmax,ymax]
# size=[width,height]
img_path = os.path.join(imgs_path, img_name)
if os.path.exists(img_path):
image = cv2.imread(img_path)
image , label = image_plus(image,label)
# 设置image 的resize 为input_size
image = cv2.resize(image,(input_size,input_size))
label = fix_label_scale(label,[height,width])
# if label[0]>=label[2]:
# print('error:',label)
# break
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









