






准备工作:首先确保虚拟机都完成了网卡、主机名、hosts文件等配置
确保安装了jdk和hadoop并且配置了环境变量,最好都是同样的路径
确保虚拟机之间都能互相ping通以及两两之间能够ssh免密登陆
我这里创建了三台虚拟机,配置信息如下
| ip地址 | 主机名 | 节名 |
| 192.168.19.129 | hadoop01 | 主节点 |
| 192.168.19.131 | hadoop02 | 子节点 |
| 192.168.19. | hadoop03 | 子节点 |
1.配置开始
下面的操作都在主节点操作(配置完可以通过scp拷贝给子节点,省时间)
接下来我们就开始最后的hadoop配置,打开hadoop安装目录
cd /opt/ruanjian
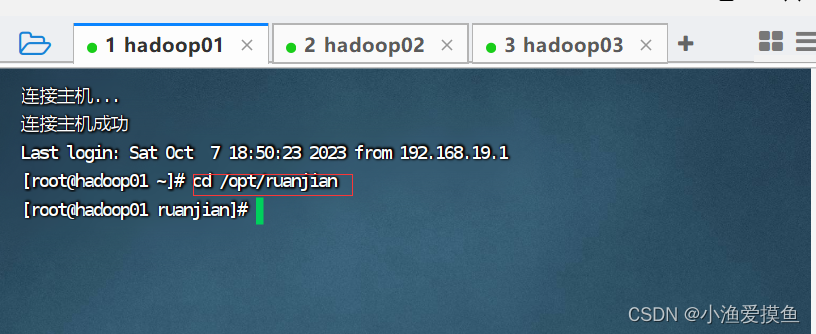 然后进入 etc/hadoop目录下
然后进入 etc/hadoop目录下
cd hadoop-3.3.6/
cd etc
cd hadoop
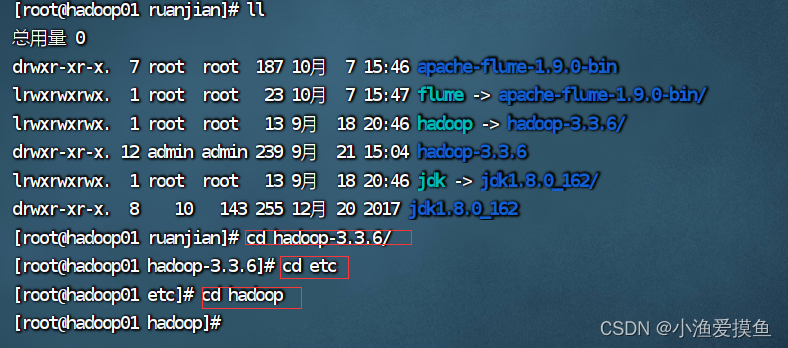
查看hadoop的配置文件
ls (1)修改 hadoop-env.sh 文件
(1)修改 hadoop-env.sh 文件
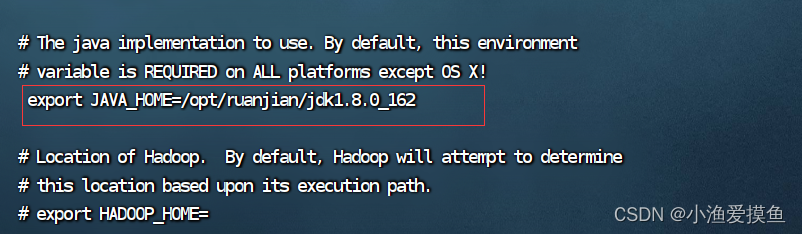
先进入文件再进行修改
vi hadoop-env.sh找到下图位置,将注释去掉,路径改成自己的jdk安装路径
(2)修改 yarn-env.sh 文件
先进入yarn-env.sh文件
vi yarn-env.sh找到如图位置,去掉注释,将路径改成自己的jdk安装路径
(3)修改 core-site.xml 文件
进入配置文件
vi core-site.xml

在配置文件中添加如下信息

(4)修改 hdfs-site.xml 文件
先进入配置文件
vi hdfs-site.xml
在配置文件中添加如下信息

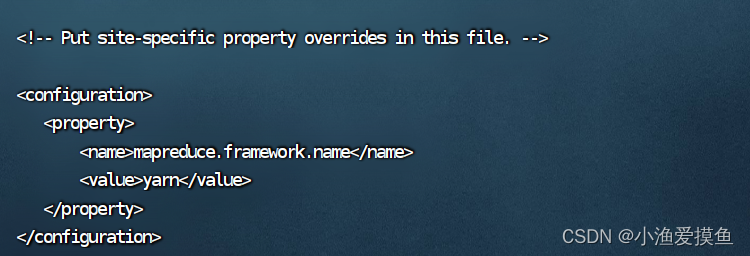
(5)修改 mapred-site.xml 文件
该文件时默认不存在的,需要指令 cp mapred-site.xml.template mapred-site.xm 复制一份出来
cp mapred-site.xml.template mapred-site.xml然后添加如下信息(hadoop01是主节点的主机名)
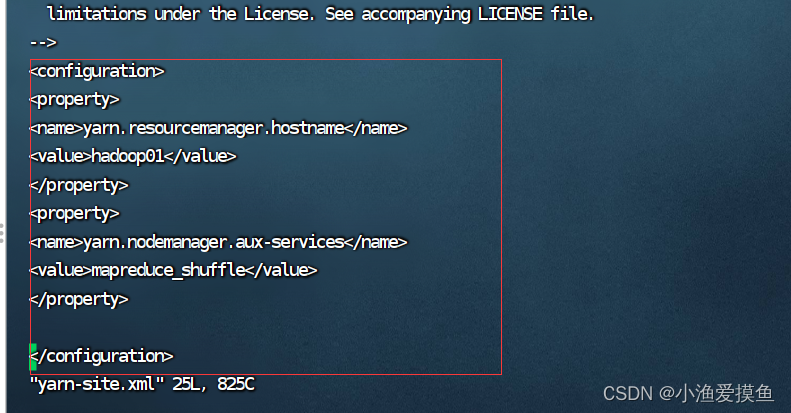
(6)修改 yarn-site.xml 文件
hadoop01是主节点的主机名
(7)修改 workers文件
这个文件没有的,需要创建编写,指令 vi workers
写主节点的IP地址或者主机名都可以
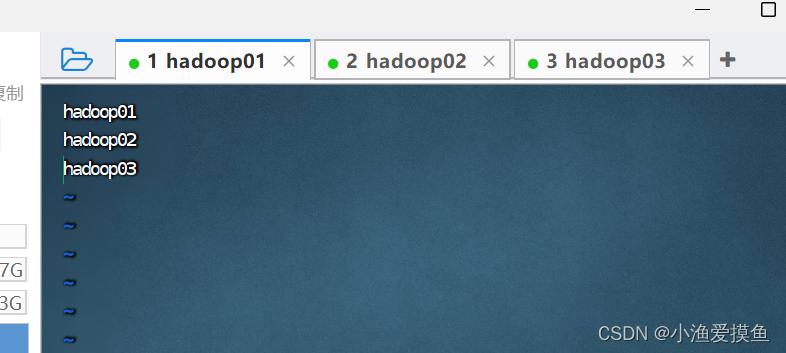
(8)修改 workers 文件
这里写子节点的配置信息,IP地址或者主机名都可以,最好跟(7)一致
(9)拷贝给子节点
将配置好的配置文件的文件夹发给其他节点
[root@hadoop01 hadoop]# scp -r hadoop hadoop02:/opt/ruanjian/hadoop-3.3.6/etc/
[root@hadoop01 hadoop]# scp -r hadoop hadoop03:/opt/ruanjian/hadoop-3.3.6/etc/

(10)创建目录(主节点操作)
[root@hadoop01 hadoop]# mkdir /usr/hadoop/tmp -p
[root@hadoop01 hadoop]# mkdir /usr/hadoop/dfs/name -p
[root@hadoop01 hadoop]# mkdir /usr/hadoop/dfs/data -p(11)赋予权限
//添加用户组
[root@hadoop01 hadoop]# groupadd hadoop
[root@hadoop01 hadoop]# useradd -g hadoop hadoop -s /bin/false
//赋予权限
[root@hadoop01 hadoop]# chown -R hadoop:hadoop /usr/hadoop/(12)将/usr/hadoop拷贝给子节点
[root@hadoop01 hadoop]# scp -r /usr/hadoop/ hadoop02:/usr/
[root@hadoop01 hadoop]# scp -r /usr/hadoop/ hadoop03:/usr/(13)配置变量(全部子节点,主节点不用)
修改/etc/profile配置文件,在文件尾部添加如下信息,指令 vi /etc/profile
#set hadoop environment
export HADOOP_HOME=/usr/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH添加完之后,输入指令使配置文件生效(全部都要)
[root@hadoop01 hadoop]# source /etc/profile
(14)权限
全部子节点按 (11) 操作赋予权限
(15)格式化(主节点上)
[root@hadoop01 hadoop]# hadoop namenode -format

出现 successfully 就说明成功了,否则的会提示报错
(16)启动集群(主节点上)
start-all.sh是一键启动的指令(必须要求互相之间能够免密登陆)
[root@hadoop01 hadoop]# start-all.sh
17)查看节点状态
可以输入 jps 查看虚拟机的状态(只能看自己的)
输入 hdfs dfsadmin -report 可以查看所有节点的信息
同时我们还可以在windows浏览器上查看界面
首先在主节点上关闭防火墙
[root@hadoop01 hadoop]# systemctl stop firewalld.service
然后修改windows的hosts的文件(C:\Windows\System32\drivers\etc),在顶部加入如下信息
最后打开浏览器输入地址 hadoop01:50070
192.168.19.129 Hadoop01
192.168.19.131 hadoop02
192.168.19.130 hadoop03(HDFS文件系统)
输入地址 hadoop01:8088

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









