






一、简介
在人工智能技术领域,大型语言模型(LLM)的认知偏差问题一直是研究热点。这类模型在展现强大生成能力的同时,也常因信息处理机制的局限性产生虚构事实现象。从信息论视角分析,该问题本质上是香农熵理论的现实映射 —— 当系统缺乏足够约束信息时,其输出结果的不确定性将显著增加。
针对这一技术瓶颈,目前行业主要存在两种解决路径:
- 模型优化路径:通过专业领域知识再训练或参数微调提升模型准确性。但该方案存在显著实施门槛,不仅需要海量标注数据支撑,更依赖高昂的算力资源,对于个人开发者而言可操作性较低。
- 知识增强路径:通过构建外部知识库实现信息增益。这种方案的核心在于将检索技术与生成模型深度耦合,形成检索增强生成(RAG)框架。该框架通过以下机制提升输出质量:
二、RAG 技术实现原理
RAG 系统的工作流程可解构为两个关键阶段:
- 智能检索阶段:当用户输入查询时,系统首先将问题转化为向量表示,通过余弦相似度等算法在预先构建的向量数据库中进行语义匹配,筛选出与查询内容高度相关的文档片段。该过程通常借助 BM25、FAISS 等成熟检索技术实现。
- 融合生成阶段:将检索到的知识片段与原始问题进行上下文拼接,形成增强型输入提示。生成模型在该复合输入指导下,通过注意力机制整合结构化知识与语义信息,最终输出包含可靠事实依据的响应内容。
这种技术架构的优势在于:既保留了大模型的语言理解能力,又通过外部知识库弥补了其知识截止、事实性不足等固有缺陷。值得注意的是,向量数据库的构建质量直接影响系统性能,通常需要经过文档解析、向量化处理、索引构建等数据工程环节。
当前,RAG 技术已在智能客服、法律文书生成、医疗辅助诊断等领域得到广泛应用,为实现可靠人工智能提供了重要技术范式。
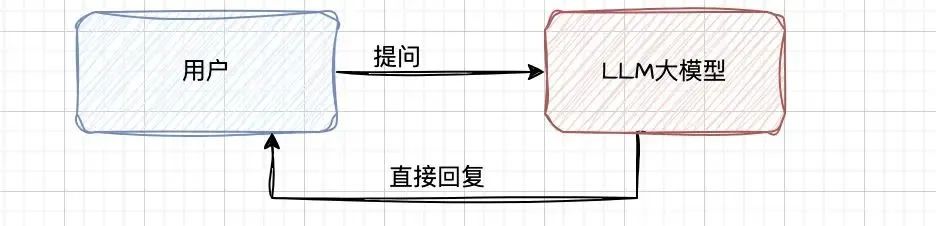
我们日常简单通过chat交互方式使用大模型如下图:
我们搭建了RAG后,整体架构如下图:
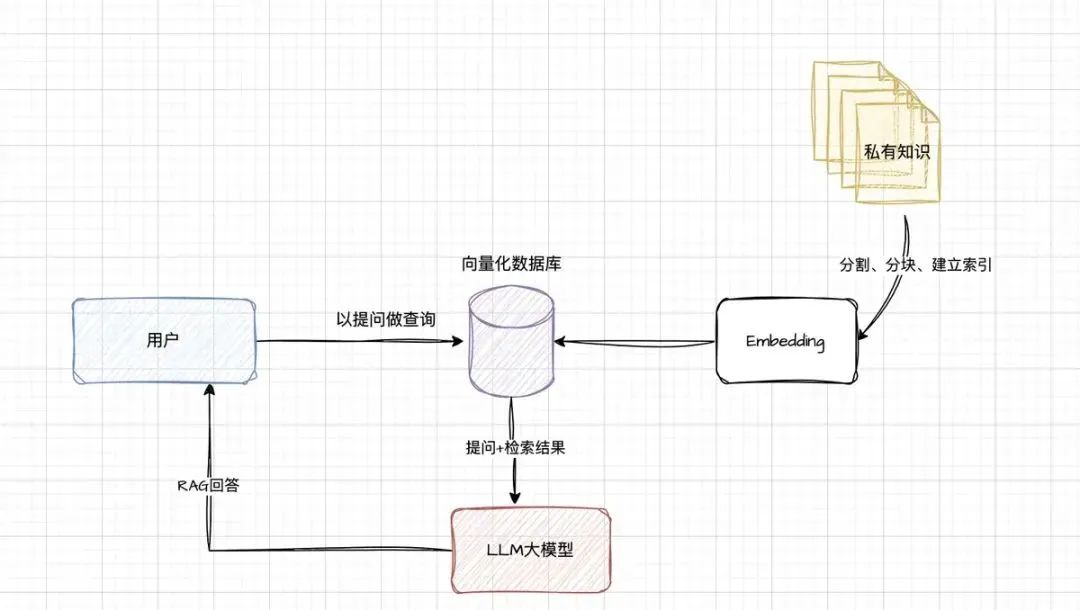
说明
1.建立索引:将日常业务知识以文件形式分割为较短的块(chunk),运用 nomic - embed - text - v1 模型对这些块进行编码与向量化处理,随后存入向量化数据库。此过程通过精细的知识拆解与数字化转换,为后续高效检索奠定基础。
2.检索向量库:当用户提出问题时,系统依据问题特征在向量库中执行向量匹配操作,精准检索出与之相似的 chunk,这些被检索出的内容将作为提问的上下文信息。该步骤如同在庞大知识地图中快速定位关键区域,确保为后续问题解答提供相关知识支撑。
3.生成回复:把用户提问内容与检索出的 chunk 整合后发送至大模型。大模型基于这两部分信息进行综合分析,从而生成问题回复。这种模式充分发挥大模型的语言处理能力,同时借助外部知识提升回复质量。
优势分析
1.信息安全保障:由于日常业务知识存储于本地,极大减少了信息泄露风险,有效保护企业敏感信息。
2.提升回复准确性:提问融入业务知识,显著降低模型幻觉,避免模型胡言乱语,使回复更符合实际业务场景。
3.增强实时性:模型回复结合业务知识与实时知识,确保回复内容不仅专业,还能紧跟当下实际情况。
4.成本效益显著:无需重新训练或微调模型,降低了因模型优化产生的高昂成本,提升资源利用效率。
三、操作
为构建本地知识库,需安装以下工具:
1.Ollama:用于下载和管理模型。
2.DeepSeek - R1:本次将使用的 LLM 模型。
3.Nomic - Embed - Text 向量模型:可对文本库进行切分、编码,并转换存入向量库。
4.AnythingLLM:这是一个开源 AI 私有化应用构建平台,能够将多个模型组合,共同搭建私有化应用。借助其强大的内置工具与功能,可轻松快速运行本地 LLM,无需复杂设置。
鉴于 Ollama 和 DeepSeek - R1 模型此前已完成安装,此处不再重复说明,接下来重点介绍另外两个工具的安装。
3.1 Nomic - Embed - Text 模型安装
Nomic - Embed - Text 模型是一款功能强大的嵌入式文本处理工具,它能够将我们的业务知识(专业术语称为语料库)转化为高维向量空间中的点,为后续开展相似度计算、分类、聚类、检索等操作奠定基础。听起来该模型颇为高级,但其底层原理其实并不复杂。以文本相似度判断为例,可通过计算两个高维向量的余弦值来实现。一般来说,余弦值越大,表明两个高维向量距离越近,相关性也就越大;反之,余弦值越小,相关性越小。当然,在实际应用中也会采用更为复杂的算法。
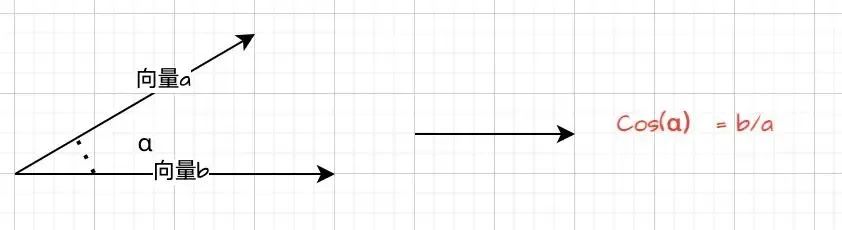
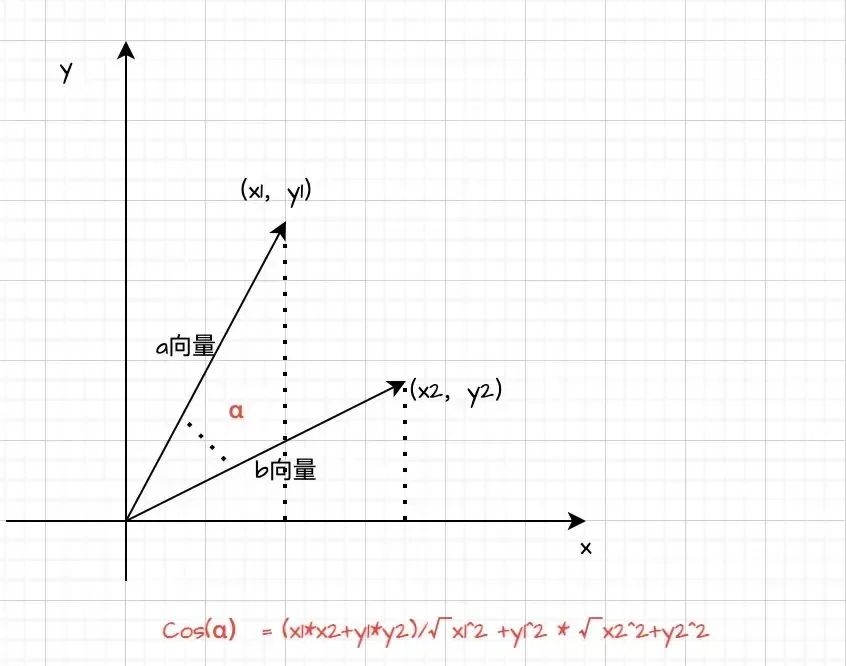
余弦值计算
通过pull命令直接安装,大小为274MB,还是比较小的:
ollama pull nomic-embed-text
然后通过ollama list查询:
mac@MacdeMacBook-Pro models % ollama list
NAME ID SIZE MODIFIED
nomic-embed-text:latest 0a109f422b47 274 MB 17 minutes ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 4 days ago
网上找一个使用的例子,大家可以直观的体会下:
from transformers import AutoTokenizer, AutoModel
import torch
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained("nomic-embed-text-v1")
model = AutoModel.from_pretrained("nomic-embed-text-v1")
# 输入文本
text1 = "今天天气好!"
text2 = "今天的天气真是好啊!"
# 将文本转换为模型输入格式
encoding = tokenizer(text1, text2, return_tensors="pt")
# 获取文本嵌入
with torch.no_grad():
outputs = model(**encoding)
# 计算文本嵌入的余弦相似度
cosine_similarity = torch.nn.functional.cosine_similarity(outputs.last_hidden_state[0], outputs.last_hidden_state[1])
print("文本相似度:", cosine_similarity.item())
3.2 AnythingLLM安装
如它官网图https://anythingllm.com/desktop所示,是一个强大的灵活的平台,通过它可以连接多个LLM模型,构建本地私有的LLM应用,配置界面简单直观。
很遗憾,由于我使用的 macOS 系统版本较低,在运行 Anything LLM 时出现报错。尽管尝试了多种解决办法,包括更新相关依赖、调整环境配置等,但问题依旧未能解决。无奈之下,决定在 Windows 虚拟机中进行安装。以下是其运行界面的相关情况。
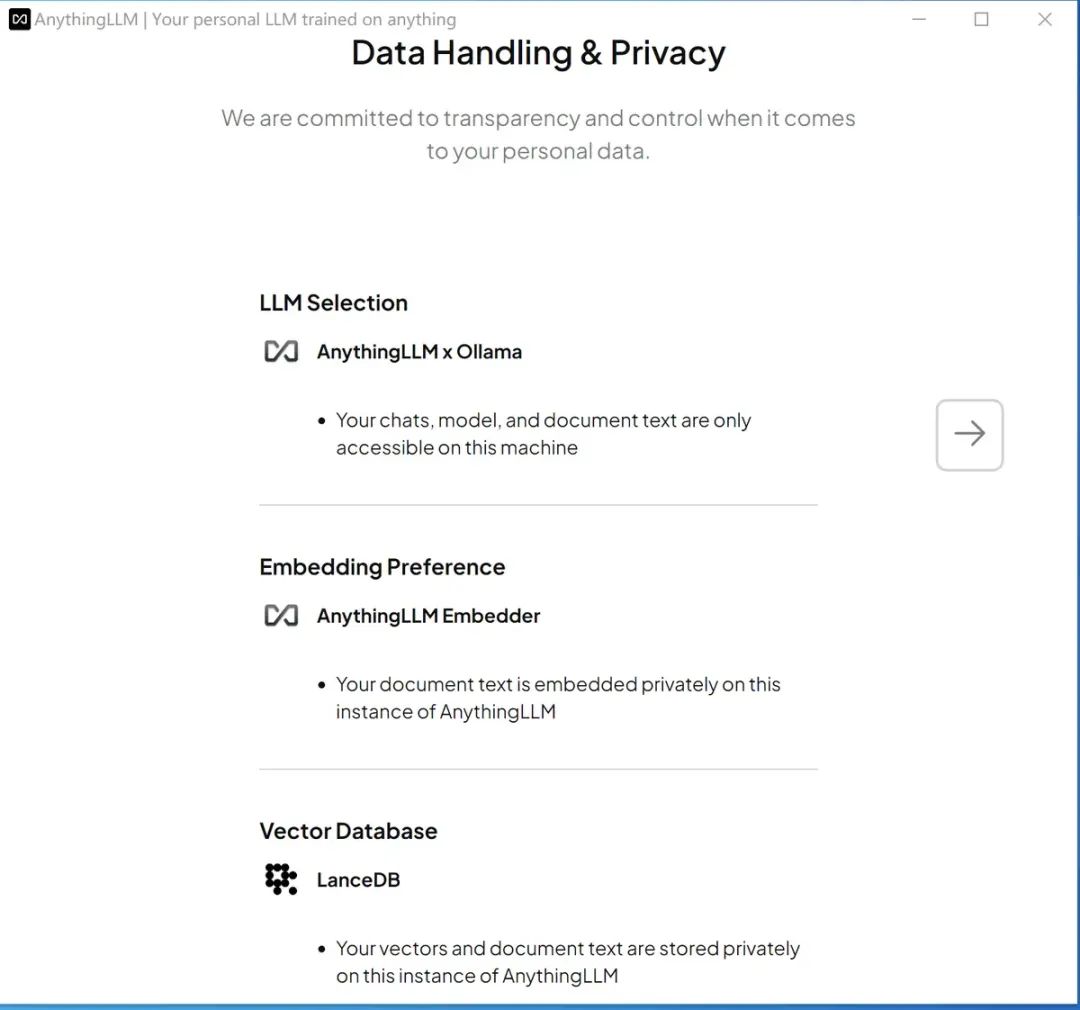 如上图可以看到,这个架构默认需要一个chat模型,需要embedder模型和一个向量数据库:LanceDB,用来保存私有化的数据;
如上图可以看到,这个架构默认需要一个chat模型,需要embedder模型和一个向量数据库:LanceDB,用来保存私有化的数据;
按右边的向右箭头,新建个工作区:
接着进行模型配置:
选择LLM模型提供商,配置下url,如下图: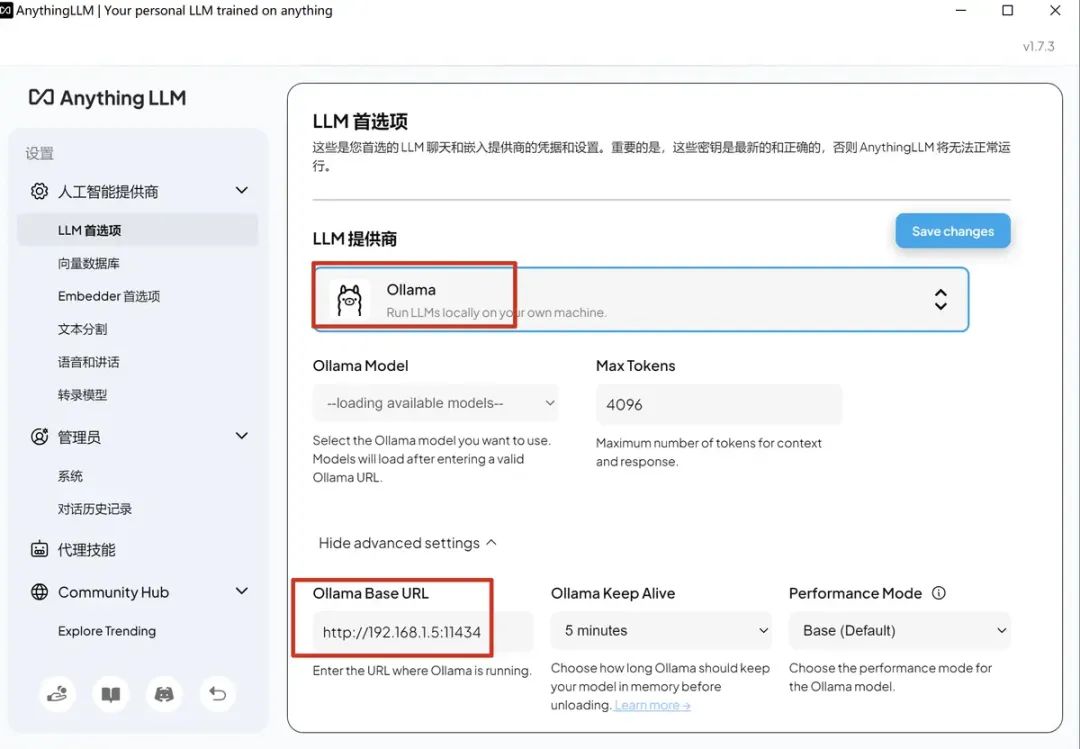 点击右上角的 Save changes。
点击右上角的 Save changes。
向量数据库无需配置,默认:
embedder模型,可以用默认的,或通过ollama供应商提供的,我先用ollama试试效果: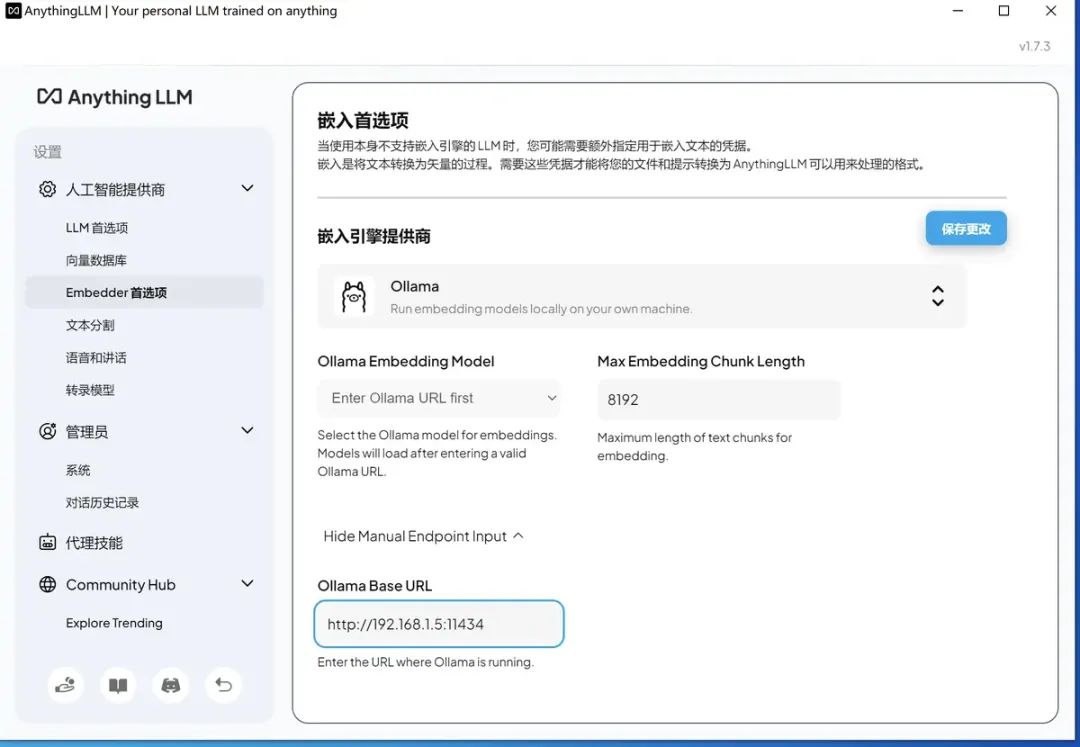
别忘记点击修改。 这里面有个坑,虽然11434端口开了,但是默认只能用127.0.0.1访问,如果绑定所有ip,则在mac下需要配置:
mac@MacdeMacBook-Pro Homebrew % sudo sh -c 'echo "export OLLAMA_HOST=0.0.0.0:11434">>/etc/profile'launchctl setenv OLLAMA_HOST "0.0.0.0:11434"
返回刚才新建的工作区,点击后进入聊天界面就可以上传语料进行交互问答了。 至此个人知识库终于创建完毕了。
至此个人知识库终于创建完毕了。
 个人知识库的问答
个人知识库的问答
四、总结
通过搭建本地模型,并结合 Embedder 和向量数据库,我们成功构建了一个隐私性更好、实时性更高的个人知识库 DAG。这一成果极大提升了知识管理的安全性与时效性,确保敏感信息的妥善保管,同时能依据最新数据快速响应知识需求。
在实际工作场景中,单纯的知识库不足以满足日益增长的业务需求,业务流程自动化(BPA)显得尤为重要。借助强大的 LLM 模型,我们能够将重复性、规律性的业务流程自动化,大幅提高工作效率与准确性。这种将知识库与 BPA 系统相结合的模式,能为企业提供更全面、更高效的解决方案,极大提升整体竞争力。
我的DeepSeek部署资料已打包好(自取↓)
https://pan.quark.cn/s/7e0fa45596e4
但如果你想知道这个工具为什么能“听懂人话”、写出代码 甚至预测市场趋势——答案就藏在大模型技术里!
❗️为什么你必须了解大模型?
1️⃣ 薪资爆炸:应届大模型工程师年薪40万起步,懂“Prompt调教”的带货主播收入翻3倍
2️⃣ 行业重构:金融、医疗、教育正在被AI重塑,不用大模型的公司3年内必淘汰
3️⃣ 零门槛上车:90%的进阶技巧不需写代码!会说话就能指挥AI
(附深度求索BOSS招聘信息)

⚠️警惕:当同事用DeepSeek 3小时干完你3天的工作时,淘汰倒计时就开始了。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?老师啊,我自学没有方向怎么办?老师,这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!当然这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









