






requests模块巩固
我们接下来通过案例进行巩固。
案例1:
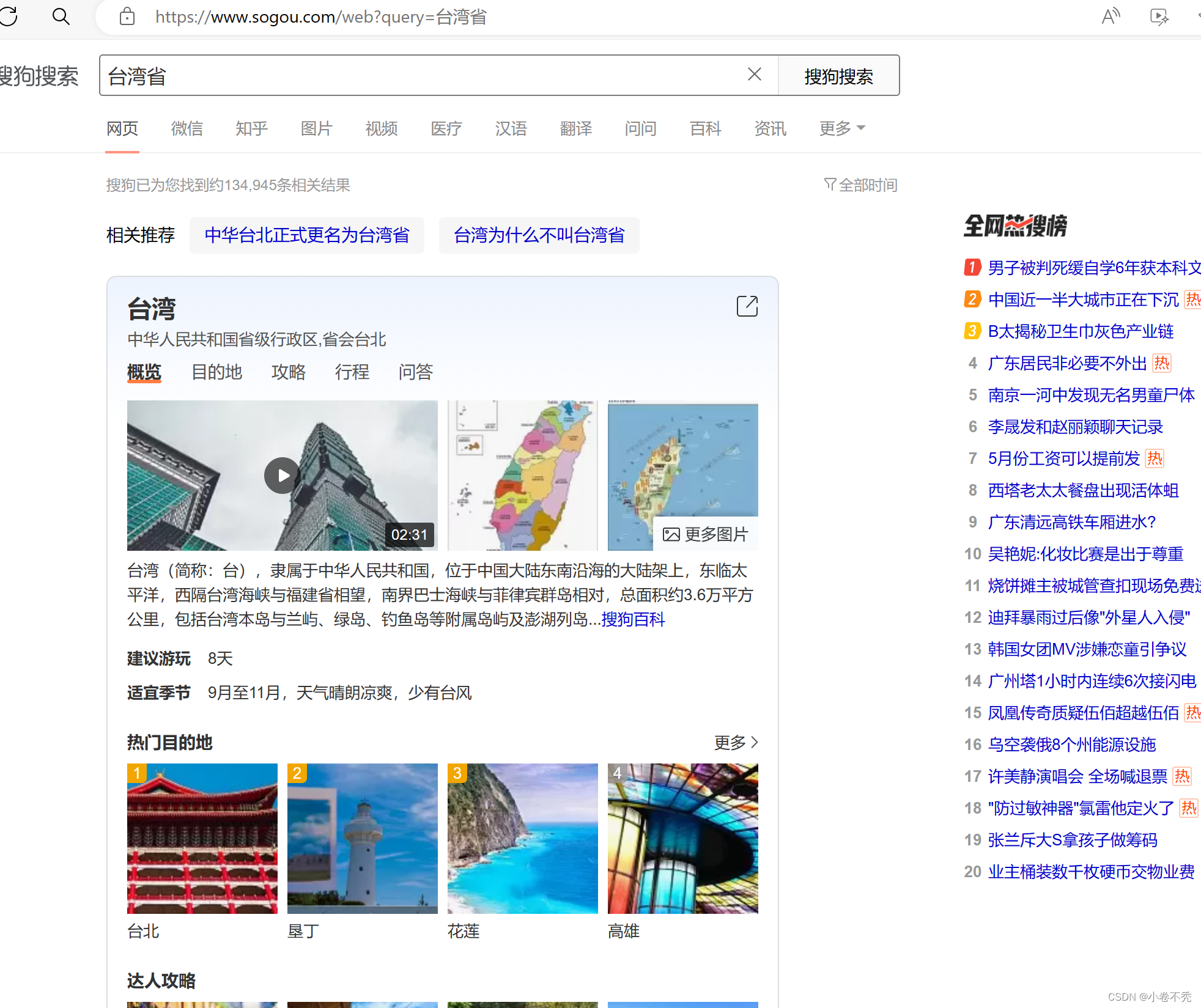
需求:爬取搜狗指定词条对应的搜索结果界面(简易网页采集器)
在这里我们以爬取搜狗输入法搜索台湾省的数据为例。其网址如下,至于台湾省后面的可以去掉,是无用的代码,一般是广告之类的。
解决代码如下:
在这里我采用的是动态输入,你也可以进行直接对 url 进行编写指定的代码。这里还涉及了一个编码的问题,这里不做过多的赘述。
#案例1:需求:爬取搜狗指定词条对应的搜索结果界面(简易网页采集器)
import requests
# 复制后,在这里你会发现变成了,乱码。 这是由于编码的特性,在这里用中文也是可以的。
#所以我改成了中文
url = 'https://www.sogou.com/web?query=台湾省'
# 有的时候 url携带多个参数,且不是固定的。所以 将url携带的参数封装到字典中。这里就是动态的了。
kw = input("enter a word:")
data = {
'query': kw
}
#所以对url进行修改,这里 ? 可以保留,也可以不保留,需要搜索的词条给了 data
url = 'https://www.sogou.com/web?'
#对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数。即动态拼接
response = requests.get(url=url,params=data)
#获取数据
page_text = response.text
#对数据进行存储
#文件命名
filename = kw+'.html'
with open(filename,'w',encoding='utf-8') as fp:
fp.write(page_text)
print(filename,'保存成功!')在这里,运行之后,网页的代码数据你会发现是可以保存下来的,但是保存的html文件却无法进行打开网页源码,这里是涉及了一个反爬机制。也就是门户网页的服务器回对请求的载体进行一个身份认证。所以我们需要进行伪装。
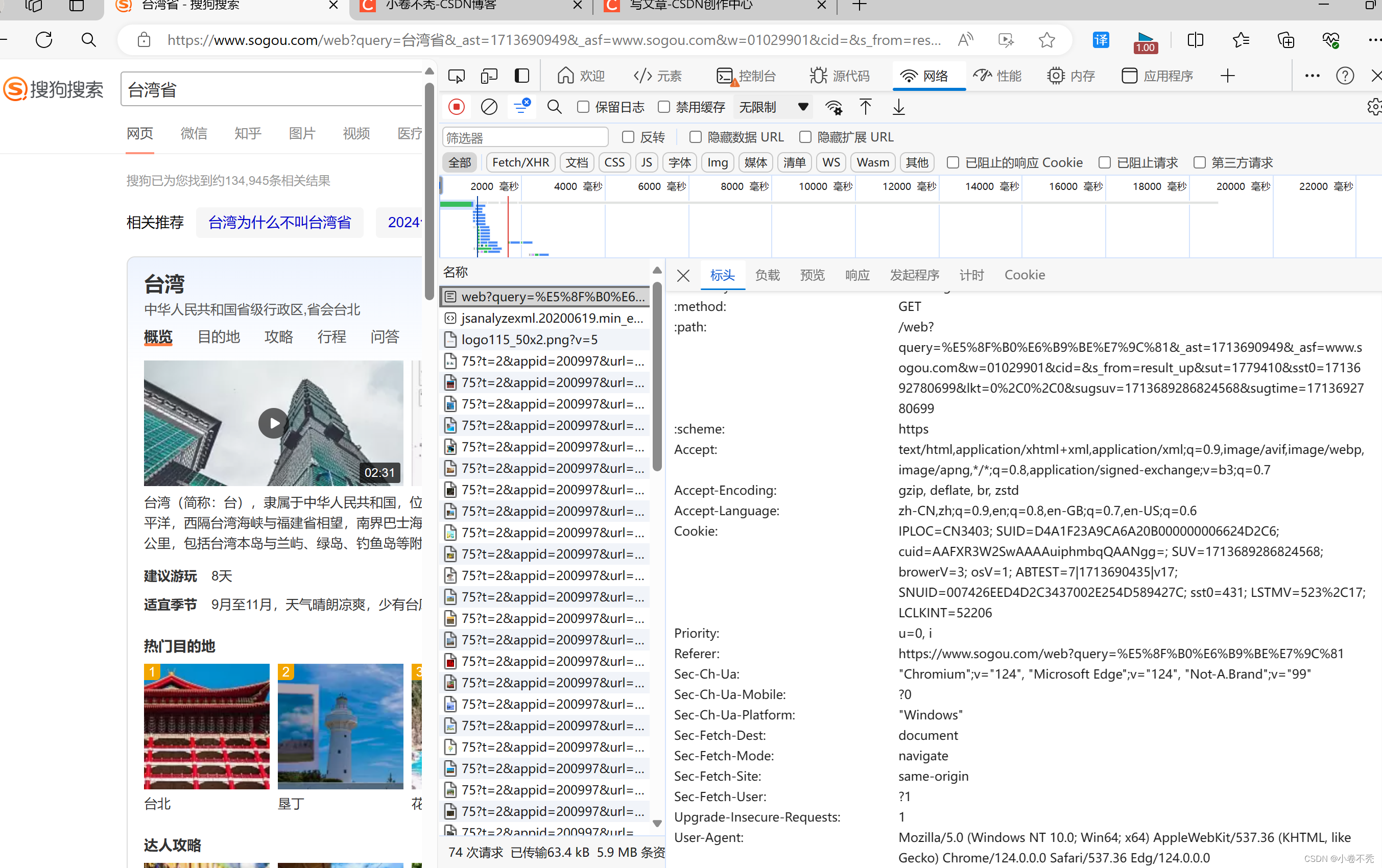
我们打开浏览器,右击鼠标,打开最下面的检查。然后在浏览器里搜索。我们再点击网络(network),可以随便找一个,点击进去,在标头里最下面有一个User-Agent,我们复制下来,这个就是身份标识。为了请求成功,我们需要使用这个,进行UA伪装。下面是进行伪装的代码,这里没有使用动态的输入,而是直接的使用,搜索的词条改为了中国台湾省:
import requests
# User-Agent (请求载体的身份标识)
# UA检测:门户网站的服务器会检测 对应请求的载体身份 标识, 如果检测到 请求的载体身份标识为某一款浏览器,
#说明请求是正常的,是用户使用浏览器发起的请求,则允许。若载体标识不是某一款浏览器,则表示是不正常的 ,是一个爬虫载体。
#服务器会拒绝请求。
#UA伪装 : 让爬虫对应的请求载体身份标识伪装 成某一款浏览器
#1、指定 url
url = 'https://www.sogou.com/web?中国'
#词条
data = {
'kw':"台湾省"
}
#将对应的 User-Agent 封装到一个字典中
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'
}
#2、模拟浏览器发送请求
response = requests.get(url=url,params=data,headers=headers)
#获取响应数据
page_text = response.text
#持久化保存数据
FileName = "中国台湾省.html"
with open(FileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print("爬取数据结束!")代码运行后,打开html,选择使用浏览器打开,结果如下:
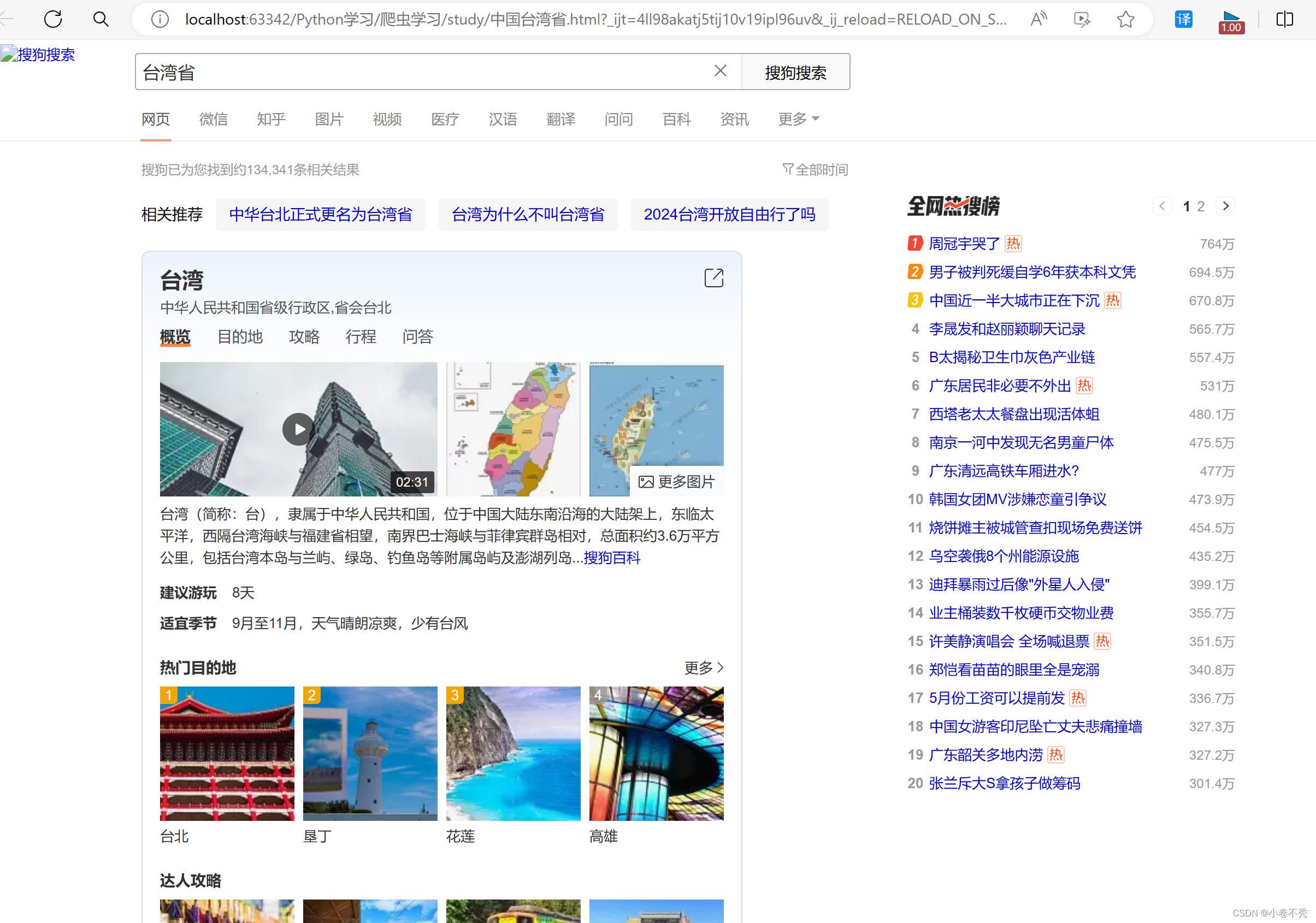
这两个一个是动态,一个是固定的,区别不大,主要的区别在于使用了UA伪装。感兴趣的可以将两个结合一下,然后动态搜索其他词条感兴趣的内容,进行爬取。
案例2:
需求:破解百度翻译
这里的 url 是在百度翻译的网站的 sug 中拿到的。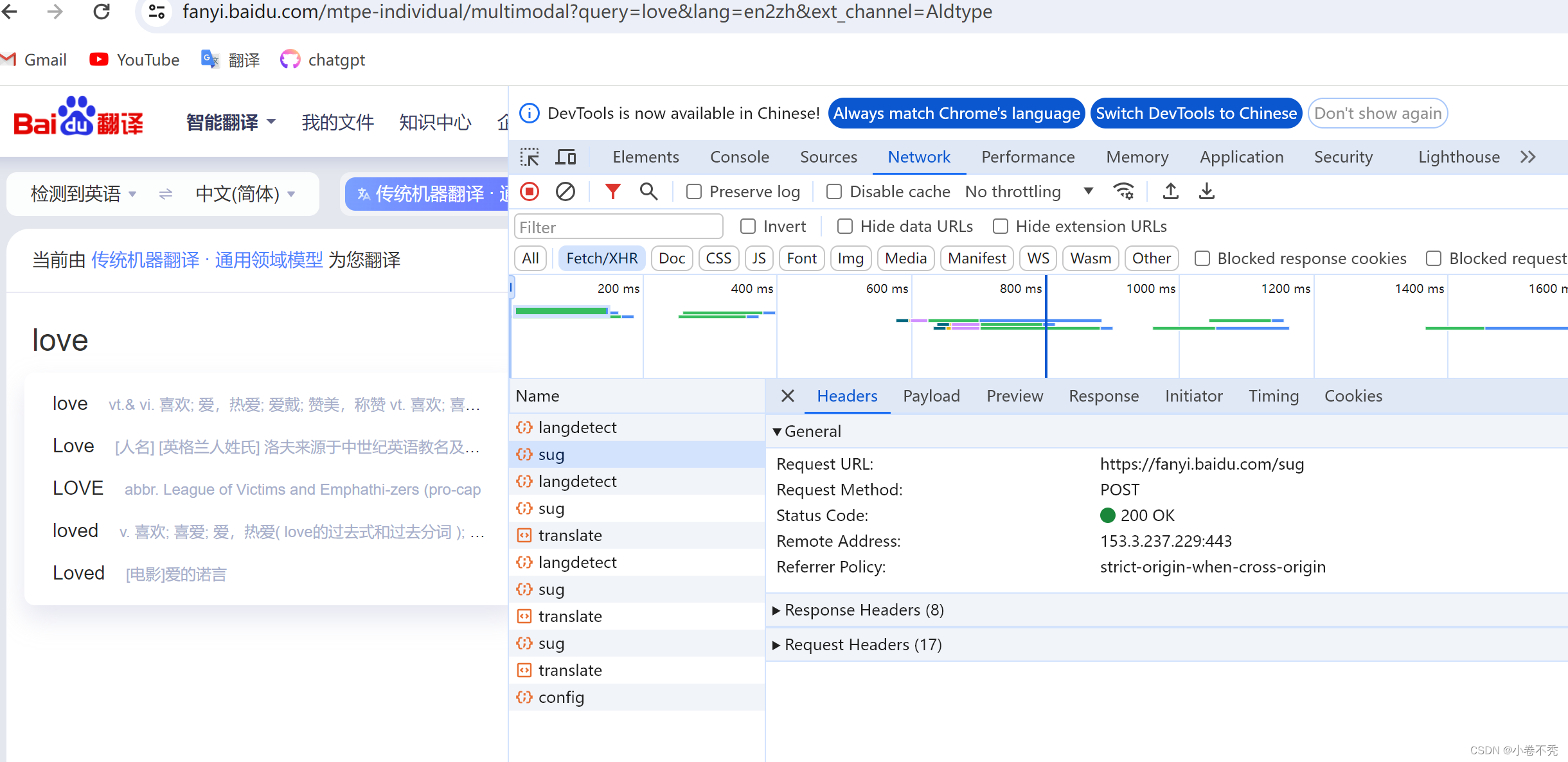
每一个sug 代表着我输入的一个字母。我是一个一个输入的,所以这里会有四个sug。其分别内容为:l 、lo 、lov 、 love
#破解百度翻译 即获取翻译结果
#post 请求(携带参数)
#响应数据是一组json数据
# 1.指定 url
import requests
import json
post_url = 'https://fanyi.baidu.com/sug'
# 这里的 post 与 get 有所区别,data 相当于 params
#post请求参数的处理(同get一致)
kw = input("请输入你要翻译的内容:")
data = { #翻译的内容
'kw':kw
}
#2.应对反爬 UA伪装
#将对应的 User-Agent 封装到一个字典中
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'
}
# 3.post参数处理
response = requests.post(url=post_url,data=data,headers=headers)
# 4. 获取响应数据: json方法返回的是 obj (字典)对象
dic_obj = response.json()
# 查看是否成功
print(dic_obj)
# 进行存储 保存在json
fp = open('fanyi.json','w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False) # 因为拿到的数据是翻译中文的,保存时,不要进行ascii编码
print("结束!")这里,采用的是动态的翻译,在命令窗口可以进行输入,然后进行翻译,将你需要的内容进行打印和保存。解释基本在代码块里都有,就不做过多的赘述,如有疑问,可以私信我。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









