







在科技发达、智能时代中,深度学习、机器学习以及人工智能成为了高频词。它们看似深不可测,但是又离不开我们的生活。深度学习和机器学习是一种技术、而人工智能一种是一种体现。使用深度学习和机器技术,使机器拥有人的某种大脑结构从而来实现人的某种行为,它不仅解决了很多即无聊又繁琐的工作,从而解放了很多工人每天反复并且厌倦的动作节,节省了大量的时间;而且它在每件工作当中,能够做到比人更加精确,并且不会像人类一样受感情甚至环境的影响导致工作的效率以及成品的达标率降低。正因为人工智能给人们带来了出乎意料的惊喜以及数不胜数的方便,并且人工智能能够满足人类的懒惰性,所以人类对深度学习、机器学习以及人工智能的需求也越来越多。在这种人工智能急剧膨胀的形势下,深度学习与机器学习成了垃圾分类的主要推力。众所周知,垃圾是人类既厌恶又无法摆脱的物体,而垃圾则是铺天盖地层出叠见地出现在我们地视野中,解决垃圾问题给全球带了巨大的挑战。想要有效处理垃圾,垃圾分类是必然的结果,然而垃圾分类过程又是一件既繁琐又耗时的事,而且使用人工进行垃圾分类它不仅需要耗费大量的人工而且它还会大大降低准确率。这时人工智能、深度学习就起了重要的作用。
本文正是研究深度学习算法的垃圾分类图像识别。论述多种深度学习算法及网络结构的图像识别处理原理,分析深度学习在图像识别中的突出优势,并且提出垃圾分类在现实社会中面临的问题与挑战。在综合了解研究后,深入探讨使用深度学习算法的卷积神经网络,在大量的有效图像数据集的训练过程中是如何增加一种全新的隐藏层,并且使用这种增加卷积层的方法来得出更高层次的特征提取从而让机器自动提取特征来实现图像的识别。
一、国内研究现状
在2000年,在我国各大发展城市成为垃圾分类的集试点,但垃圾分类在当时似乎只是一个口号,城市的设施、宣传、监管都缺少全程布局。虽然实施了垃圾分类,但是没有得到真正的落实。城市的各类垃圾桶没有俱全、人们并没有按照要求进行垃圾投放、垃圾处理工厂不够完善最终还是被运输到同一个地方处理等等,这些问题都只是口头的垃圾分类,而最终垃圾还是按照混合性来处理,所以当时进行的垃圾分类并没有效的效果,垃圾的污染还是在继续日益恶化,因此国家更加注重垃圾分类快速并要按照严格要求来实施。在2019年,《生活垃圾分类制度实施方案》正式颁布。
为了垃圾分类得到大众的高度重视,在2019年7月,上海正式落实生活垃圾分类制度方案,称为历史上最严格的垃圾分类措施,对混合投放行为给予惨痛的惩罚,个人和单位最高罚款分别高达200元与5万元人民币。这令人抓狂并窒息的条例让上海居民犯了愁。一杯泡面吃完了也不敢扔,因为泡面杯、泡面叉、还有吃泡面剩下的泡面水这都怎么分?怎么放才正确?这些都成了大家的灵魂拷问,所以每天扔垃圾都要三思而后行。但是这些这么细致的事情用人力来监管,这诚然每个人都会存在有非标准答案的情况,因此,此时人工智能技术,智能垃圾分类就大有作为。“小黄狗”、“别扔了”等这些都是大数据技术的智能垃圾回收箱,根据扫码投放以及公众号预约回收大件物品,云计算还可以根据个人垃圾的投放做出每个人的数据分析,可得出日常人们的生活习惯以及购买的数量最多的商品是什么,这同时还可以促进商店的经济发展。在捡练工厂,我国引进了芬兰的ZenRobotics垃圾分类系统,它比人的大脑更快更准确,通过传感器与扫描仪,准确的识别并抓取所需垃圾并投放到正确的地方,每天的工作量达到人的40倍以上,是垃圾分类捡练工厂的一大活宝。
二、开发工具
Microsoft VS Code,通常被简称为VS Code或VSC。它是一个非常强大的工具并且可跨三大平台运行,Window、Linux和Mac。VS Code可以满足用户根据各自喜好编辑出心目中最完美的专属编译器。不仅JavaScript,TypeScript,Node.js都是VS Code所支持的,而且在各大语言里提供富裕的运行时与扩展库,如Python,C++,C#,PHP等语言。对于一个程序员来说,VS Code能达到他们心目中的免费,高效,开源,轻便,这是完全取胜于atom,webstorm和MyEclipse等开发工具。在2019年Jupyter增加在VS Code的功能里,再也不需要用插件而且可以直接运行调试,比PyCharm更简便,更轻捷,所以对于Python学者来说VS Code又比PyCharm更胜一筹。
三、变分自动编码器
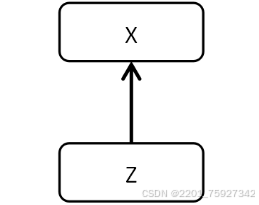
如何重构原始输入的数据是变分自动编码器研究所在。我们从3.1.1节得知在自动编码器中间层的隐含特征数据可以重构原始数据,在此我们定义隐含特征数据为Z,因此我们可以在隐含特征Z中加入满足某种分布的随机因素就可以重构出想要的数据,如下图3.2变分自动编码器模型所示,这种模型简称VAE。
这种模型一般作用于数据的自动生成。在自动编码器模型的训练结束后,我们可分别在经验分布和解码器中可得出潜在变量与新的样本数据。变分自动编码器的X由潜在并不可观测的隐含变量Z生成,若生成的数据X是图像,那么Z则是用于生成X图像的潜在属性。所以数据生成过程由Z的构成和Z变换成X的过程两大步骤组成。将给定的数据X传给编码器网络,就可以得到给定X情况下Z的分布,然后根据Z的分布进行采样得出演变量样本Z,然后将Z传递给解码器网络,通过解码器网络可以获得在给定Z的条件下X分布的两个参数,这样我们就可以从中采样得出最终的数据X。训练完毕变分自动编码器后我们只需要解码器进行生成数据。在生成数据中先对Z在标准正态分布进行采样来生成新的数据。这种变分自动编码器一般用于图像生成,可以使用训练数据通过变分自动编码器得出新的的数据而且比训练数据效果更为好看的图片。
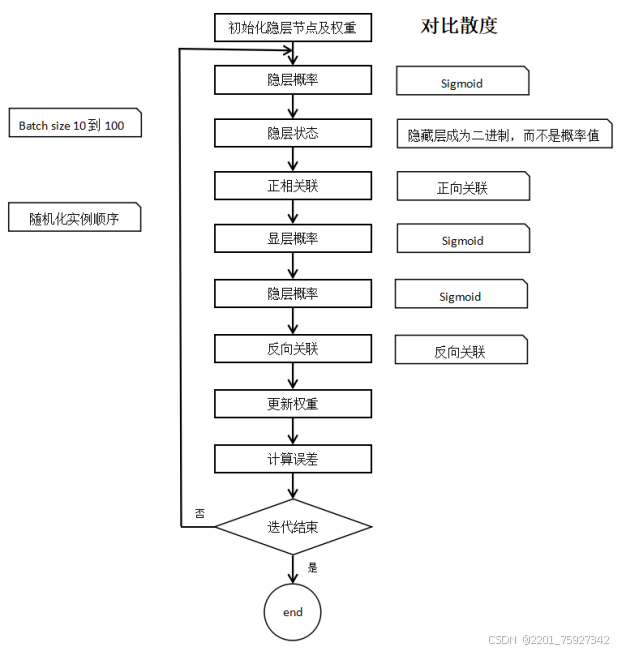
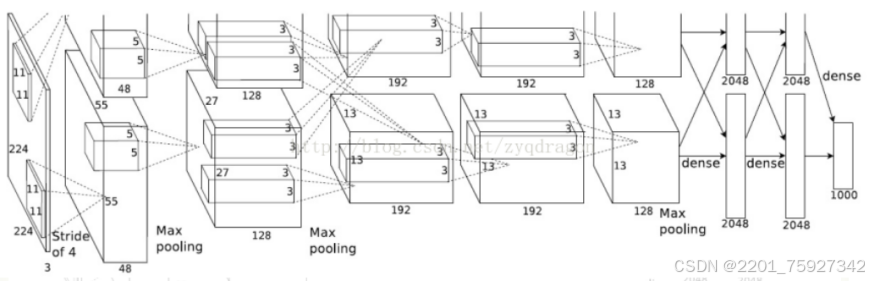
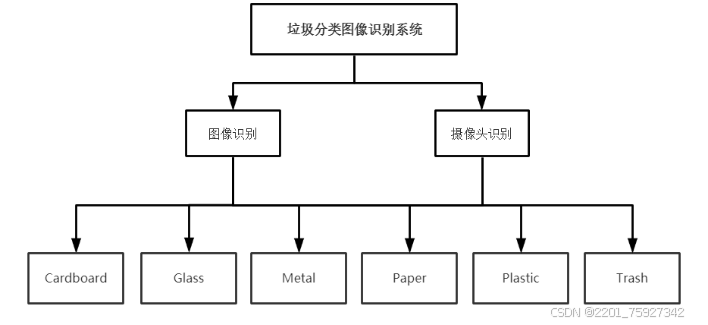

四、项目结果研究与分析
项目的实现最终是作用于垃圾分类,本系统只可识别垃圾的六种类型,分别为Cardboard、Glass、Metal、Paper、Plastic和Trash。因为数据的有限性与局限性所以没能与社会上的垃圾分类达到统一的分类类型标准。但项目的实现最终的思想概念是能用于提高人们进行垃圾投放分类的准确率,以及可提供一个方便的平台给人们进行认识并且学习垃圾分类的所属类型。当系统用户需要对垃圾进行投放但对垃圾投放分类类型有疑惑时,此系统就起到了很重要的作用,用户可以对将要投放的垃圾进行拍照,把所拍的图片传进系统中,那么就可以得到此垃圾的所属类型,并把他准确的放入正确类型的垃圾桶里。除了传送图片以外,用户还可以直接打开摄像头,把将要投放的垃圾放进摄像头区域,同样可以得出结果。这样投放垃圾者每天就再也不用被垃圾弄得焦头烂额,并且再也不会因为垃圾投放错误导致被罚款了。而对于系统还未完善达到与社会垃圾分类类型的标准,这在于数据难于收集,所以该系统在数据的收集方面往后得有待改善,让系统早一步与社会的垃圾分类标准达成统一。
整个系统设计从数据收集、数据预处理、卷积神经网络的搭建、模型的训练、模型的测试、到界面的设计就完成了一个简单的垃圾分类图像识别的系统。其系统中的垃圾分类识别结果如下列图所示:
Carboard垃圾类型主要是相对比较厚硬的纸皮箱类型垃圾,此类垃圾可以回收加工再循环使用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









