



一.Map和Set
TreeMap 和 TreeSet 即 java 中利用搜索树实现的 Map 和 Set。
HashMap 和 HashSet 即 java 中利用哈希表实现的 Map 和 Set
Map和Set是 一种适合动态查找的集合容器。
1.根据姓名查询考试成绩 2. 通讯录,即根据姓名查询联系方式 3. 不重复集合,即需要先搜索关键字是否已经在集合中 可能在查找时进行一些插入和删除的操作,即动态查找
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value)
Map中存储的就是key-value的键值对,Set中只存储了Key
二、Map的使用
1.Map是一个接口类,该类没有继承自Collection,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap,该类中存储的是结构的键值对,并且K一定是唯一的,不能重复,value是可以重复的。
2.在TreeMap中插入键值对时,key不能为空,否则就会抛NullPointerException异常,value可以为空。但 是HashMap的key和value都可以为空。
3. Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
4. Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
5. Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行重新插入。
2)map种常用的方法
方法 解释
V get(Object key) 返回 key 对应的 value
V getOrDefault(Object key, V defaultValue) 返回 key 对应的 value,key 不存在,返回默认值
V put(K key, V value) 设置 key 对应的 value
V remove(Object key) 删除 key 对应的映射关系
Set keySet() 返回所有 key 的不重复集合
Collection values() 返回所有 value 的可重复集合
<Set> entrySet() 返回所有的 key-value 映射关系
boolean containsKey(Object key) 判断是否包含 key
boolean containsValue(Object value) 判断是否包含 value
Map.Entry 是Map内部实现的用来存放键值对映射关系的内部类,该内部类中主要提供了 <key,value>的获取,value的设置以及Key的比较方式。
K getKey() 返回 entry 中的 key
V getValue() 返回 entry 中的 value
V setValue(V value) 将键值对中的value替换为指定value
代码:
for(String s : m.keySet()){
System.out.print(s + " ");
}
System.out.println();
// 打印所有的value
// values()是将map中的value放在collect的一个集合中返回的
for(String s : m.values()){
System.out.print(s + " ");
}
System.out.println();
// 打印所有的键值对
// entrySet(): 将Map中的键值对放在Set中返回了
for(Map.Entry<String, String> entry : m.entrySet()){
System.out.println(entry.getKey() + "--->" + entry.getValue());
}
System.out.println();
}
3)代码实现例题
例题:
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param numbers int整型一维数组
* @param target int整型
* @return int整型一维数组
*/
public int[] twoSum (int[] numbers, int target) {
Map<Integer,Integer> map=new HashMap<Integer,Integer>();
for(int i=0;i<numbers.length;i++){
if(map.containsKey(target-numbers[i])){
//返回的下标按升序排列
//return new int[]{i+1,map.get(target-numbers[i])+1};
//因为先判断是否包含map.containsKey(target-numbers[i]),包含的话就是先存储的,所以下表更小
return new int[]{map.get(target - numbers[i])+1, i+1};
}else{
map.put(numbers[i],i);
}
}
return new int[]{-1,-1};
}
}


import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param numbers int整型一维数组
* @return int整型
*/
public int MoreThanHalfNum_Solution (int[] numbers) {
int n=numbers.length;
Map<Integer,Integer> map=new HashMap<Integer,Integer>();
for(int i=0;i<n;i++){
if(!map.containsKey(numbers[i])){
map.put(numbers[i],1);
}else{
map.put(numbers[i],map.get(numbers[i])+1);
}
if(map.get(numbers[i])>n/2){
return numbers[i];
}
}
return 0;
}
}
三、Set的使用
Set是继承自Collection的接口类,Set中只存储了Key,并且要求key一定要唯一。
TreeSet的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的
4. Set最大的功能就是对集合中的元素进行去重
5. 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础 上维护了一个双向链表来记录元素的插入次序。
6. Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入
7. TreeSet中不能插入null的key,HashSet可以。
代码解释:
public static void TestSet(){
Set<String> s = new TreeSet<>();
// add(key): 如果key不存在,则插入,返回ture
// 如果key存在,返回false
boolean isIn = s.add("apple");
s.add("orange");
s.add("peach");
s.add("banana");
System.out.println(s.size());
System.out.println(s);//直接打印s
//使用迭代器遍历,输出每个元素 + 空格
Iterator<String> it = s.iterator();
while(it.hasNext()){
System.out.print(it.next() + " ");
}
TreeSet 默认有序输出[apple, banana, orange, peach]
2)常用方法
方法 解释
boolean add(E e) 添加元素,但重复元素不会被添加成功
void clear() 清空集合
boolean contains(Object o) 判断 o 是否在集合中
Iterator iterator() 返回迭代器
boolean remove(Object o) 删除集合中的 o
int size() 返回set中元素的个数
boolean isEmpty() 检测set是否为空,空返回true,否则返回false
Object[] toArray() 将set中的元素转换为数组返回
boolean containsAll(Collection c) 集合c中的元素是否在set中全部存在,是返回true,否则返回 false
boolean addAll(Collection c) 将集合c中的元素添加到set中,可以达到去重的效果
四、哈希表
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
插入元素 根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素 对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若 关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)

插入44有冲突
冲突-解决-闭散列 闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以 把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢? 1. 线性探测 比如上面的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,下标为4,因此44理论上应该插在该 位置,但是该位置已经放了值为4的元素,即发生哈希冲突。 线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。 插入 通过哈希函数获取待插入元素在哈希表中的位置 如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到 下一个空位置,插入新元素
冲突-解决-开散列/哈希桶
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子 集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
五、HashMap底层原理和扩容机制
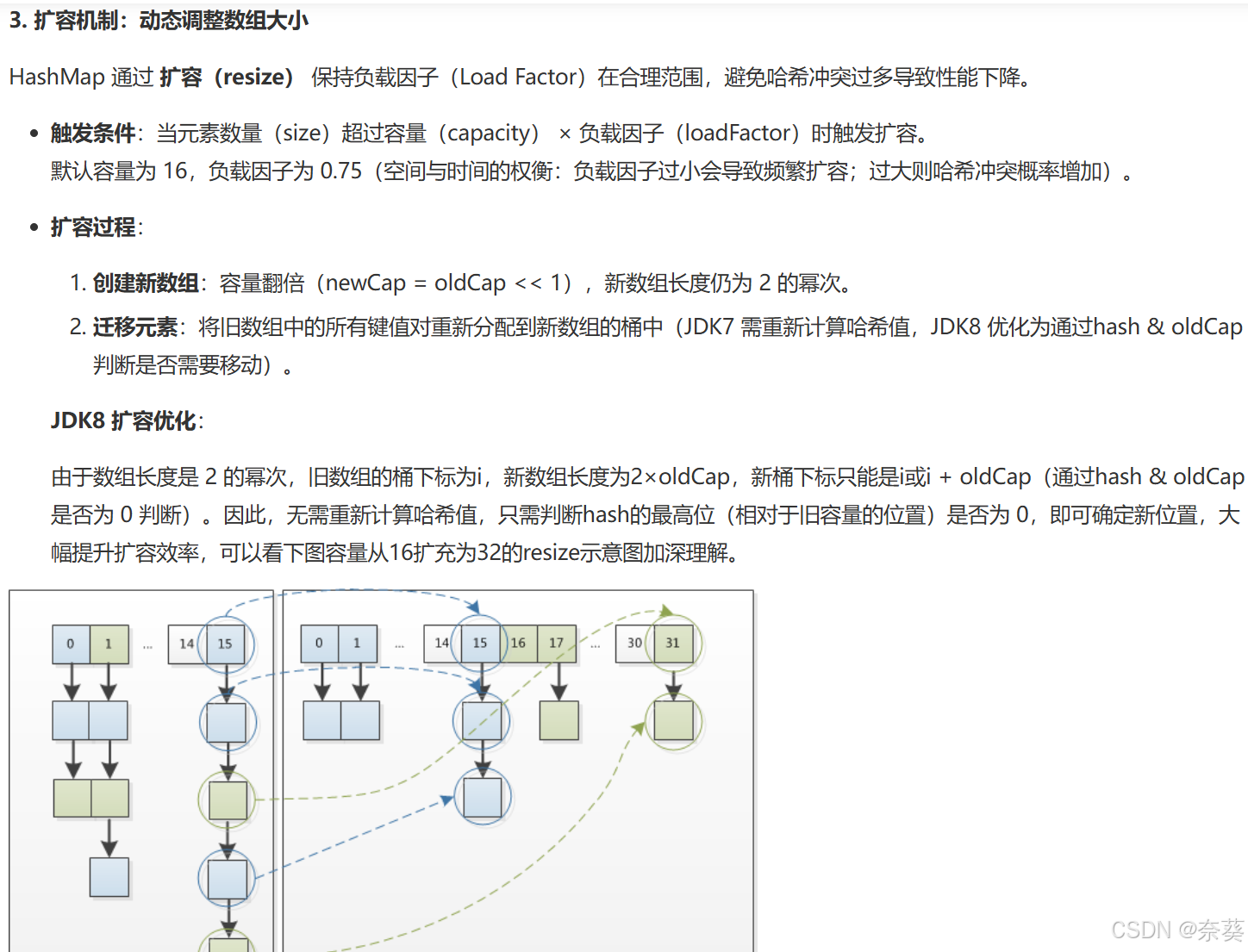
HashMap底层采用数组+链表/红黑树结构,通过哈希算法确定元素存储位置。默认初始容量16,负载因子0.75,当元素数量超过(容量×负载因子)时触发扩容。扩容时创建双倍容量新数组,通过高位运算重新计算节点位置(JDK8优化为无需重新hash),原数据通过尾插法迁移到新数组。链表长度超过8且数组长度≥64时会转为红黑树,提升查询效率。
HashMap 的底层是一个 哈希表(Hash Table),本质是一个动态扩容的数组(称为table),数组的每个元素是一个 链表(或 红黑树,JDK8 及以后),用于存储哈希冲突的键值对。
- 桶(Bucket):数组的每个槽位(table[i])称为一个桶,用于存放哈希值相同的键值对。
- 哈希冲突(Hash Collision):不同键通过哈希函数计算出相同的桶下标,导致多个键值对需要存放在同一个桶中。
- 链表(Entry 或 Node 节点):JDK7 中桶内元素以链表形式存储(节点类型为Entry<K,V>);JDK8 中改为Node<K,V>,当链表长度超过阈值时转换为红黑树。
- 红黑树(TreeNode):JDK8 引入,当链表长度 ≥8 且数组长度 ≥64 时,链表转换为红黑树(节点类型为TreeNode<K,V>),以将查找时间复杂度从 O(n) 优化到 O(logn)。
键的哈希值通过key.hashCode()方法获取,但 HashMap 会对其进行二次哈希(hash()方法),目的是 减少哈希冲突
当不同键的哈希值映射到同一个桶时,HashMap 使用 链地址法 解决冲突:将冲突的键值对以链表形式挂在同一个桶下。
HashMap 通过 扩容(resize) 保持负载因子(Load Factor)在合理范围,避免哈希冲突过多导致性能下降。
触发条件:当元素数量(size)超过容量(capacity) × 负载因子(loadFactor)时触发扩容。
默认容量为 16,负载因子为 0.75

六、总结
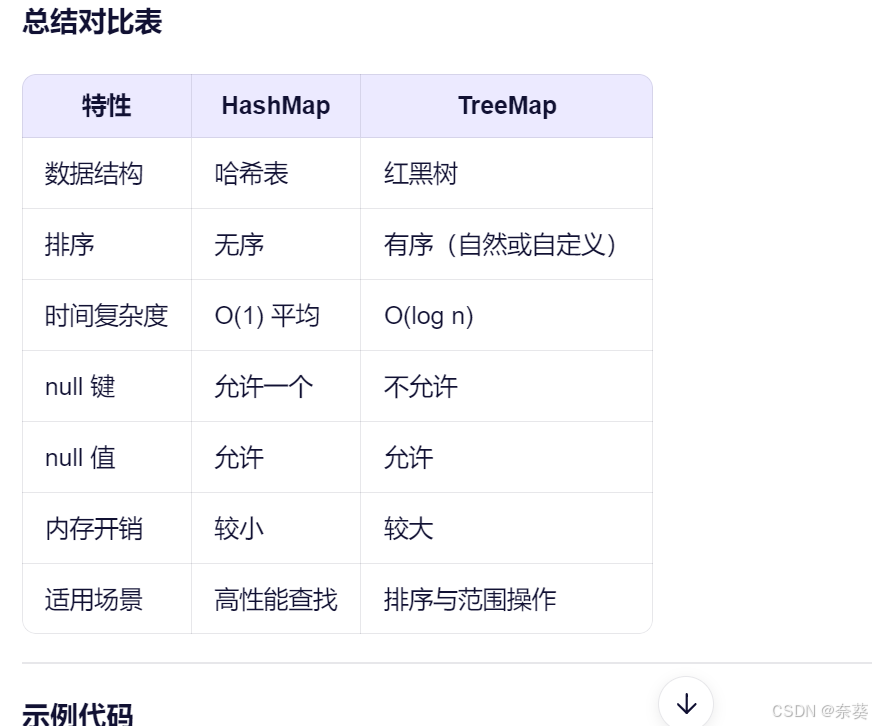
TreeMap 和 HashMap
是 Java 集合框架中两种常用的 Map 接口实现,它们都用于存储键值对(key-value pairs),但在内部实现、性能特征和使用场景上存在显著差异。以下是它们之间主要的不同点:
1. 底层数据结构
-
HashMap:
- 基于 哈希表(Hash Table) 实现。
- 使用数组 + 链表(或红黑树,当链表长度超过阈值时)来存储数据。
- 通过
hashCode()和equals()方法来确定键的存储位置和进行查找。
-
TreeMap:
- 基于 红黑树(Red-Black Tree) 实现。
- 是一种自平衡的二叉搜索树,保证了树的高度接近对数级别,从而保证操作效率。
- 键按照自然顺序(natural ordering)或自定义的
Comparator进行排序。
2. 元素排序
-
HashMap:
- 不保证任何顺序。元素的排列顺序可能随着扩容而改变。
- 如果需要有序,可以使用
LinkedHashMap(按插入顺序)。
-
TreeMap:
- 键是有序的。默认按照键的自然顺序排序(如字母顺序、数值大小)。
- 也可以通过构造函数传入
Comparator来自定义排序规则。 - 这使得
TreeMap非常适合需要范围查询(如查找某个范围内的键)的场景。
3. 时间复杂度
| 操作 | HashMap | TreeMap |
|---|---|---|
| 查找(get) | O(1) 平均情况,最坏 O(n) | O(log n) |
| 插入(put) | O(1) 平均情况,最坏 O(n) | O(log n) |
| 删除(remove) | O(1) 平均情况,最坏 O(n) | O(log n) |
HashMap在理想情况下(哈希函数良好,冲突少)性能非常高效。TreeMap的性能更稳定,但平均来说比HashMap慢。
4. 键的约束
-
HashMap:
- 允许一个
null键和多个null值。 - 对键没有可比性要求。
- 允许一个
-
TreeMap:
- 不允许
null键(会抛出NullPointerException),因为排序时无法比较null。 - 允许
null值。 - 键必须实现
Comparable接口,或通过Comparator提供比较逻辑。
- 不允许
5. 内存占用
-
HashMap:
- 通常内存开销较小,但需要预留一定的容量以减少哈希冲突。
-
TreeMap:
- 每个节点需要存储左右子节点、父节点和颜色信息,因此内存开销更大。
6. 适用场景
| 场景 | 推荐使用 |
|---|---|
| 快速查找、插入、删除,不关心顺序 | ✅ HashMap |
需要键有序,或进行范围查询(如 subMap, headMap, tailMap) | ✅ TreeMap |
| 需要统计排名、区间数据(如分数段统计) | ✅ TreeMap |
键可能为 null | ✅ HashMap |
| 高并发读写(非线程安全) | 可考虑 ConcurrentHashMap |
7. 线程安全性
- 两者都不是线程安全的。
- 在多线程环境下,需要外部同步或使用
Collections.synchronizedMap()包装,或使用并发容器(如ConcurrentHashMap)。
TreeSet 和 HashSet
是 Java 集合框架中两种常用的 Set 接口实现,它们都用于存储不重复的元素,但在底层数据结构、排序特性、性能和使用场景上有显著区别。以下是它们之间的详细对比:
1. 底层数据结构
-
HashSet:
- 基于 HashMap 实现。
- 内部使用一个
HashMap来存储元素,元素作为HashMap的 键,值是一个固定的Object(PRESENT)。 - 依赖 哈希表(Hash Table),通过
hashCode()和equals()方法来判断元素是否重复。
-
TreeSet:
- 基于 TreeMap 实现。
- 内部使用一个
TreeMap来存储元素,元素作为TreeMap的 键,值是固定的Boolean.TRUE。 - 底层是 红黑树(Red-Black Tree),一种自平衡的二叉搜索树。
2. 元素排序
-
HashSet:
- 不保证任何顺序。
- 元素的存储顺序是无序的,且可能随着扩容而改变。
- 如果需要保持插入顺序,可以使用
LinkedHashSet。
-
TreeSet:
- 元素是有序的。
- 默认按照元素的 自然顺序(natural ordering) 排序(如字符串按字母顺序,数字按大小)。
- 也可以通过构造函数传入
Comparator来自定义排序规则。
3. 时间复杂度
| 操作 | HashSet | TreeSet |
|---|---|---|
| 添加(add) | O(1) 平均情况 | O(log n) |
| 删除(remove) | O(1) 平均情况 | O(log n) |
| 查找(contains) | O(1) 平均情况 | O(log n) |
HashSet在哈希函数良好、冲突少的情况下性能非常高效。TreeSet的性能更稳定,但平均比HashSet慢。
4. 元素要求
-
HashSet:
- 元素类必须正确重写
hashCode()和equals()方法,否则可能导致重复元素或查找失败。 - 允许一个
null元素。
- 元素类必须正确重写
-
TreeSet:
- 元素必须实现
Comparable接口,或通过Comparator提供比较逻辑。 - 不允许
null元素(会抛出NullPointerException),因为排序时无法比较null。
- 元素必须实现
5. 内存占用
-
HashSet:
- 内存开销相对较小,但需要预留容量以减少哈希冲突。
-
TreeSet:
- 每个节点需要存储父节点、左右子节点和颜色信息(红黑树特性),因此内存开销更大。
6. 适用场景
| 场景 | 推荐使用 |
|---|---|
| 快速添加、删除、查找,不关心顺序 | ✅ HashSet |
| 需要元素有序(如排行榜、字典序) | ✅ TreeSet |
| 需要范围查询(如“找出大于100的所有数”) | ✅ TreeSet(支持 subSet, headSet, tailSet) |
元素可能为 null | ✅ HashSet |
| 需要统计排名、区间数据 | ✅ TreeSet |
7. 线程安全性
- 两者都不是线程安全的。
- 在多线程环境下,需要外部同步或使用
Collections.synchronizedSet()包装。
总结对比表
| 特性 | HashSet | TreeSet |
|---|---|---|
| 数据结构 | 哈希表(基于 HashMap) | 红黑树(基于 TreeMap) |
| 排序 | 无序 | 有序(自然或自定义) |
| 时间复杂度(平均) | O(1) | O(log n) |
| null 元素 | 允许一个 | 不允许 |
| 元素要求 | 重写 hashCode() 和 equals() | 实现 Comparable 或提供 Comparator |
| 内存开销 | 较小 | 较大 |
| 支持范围操作 | ❌ | ✅(如 subSet, headSet) |
- 使用
HashSet:当你追求高性能,且不需要排序时。 - 使用
TreeSet:当你需要元素有序或进行范围查询、排名统计等操作时

















 2109
2109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









