






 本文详细解析了Transformer模型,一种仅依赖注意力机制的序列转录方法,在机器翻译任务中的应用。介绍了其核心组件,包括多头注意力机制、位置编码、残差连接等,并探讨了训练过程中的正则化技巧。
本文详细解析了Transformer模型,一种仅依赖注意力机制的序列转录方法,在机器翻译任务中的应用。介绍了其核心组件,包括多头注意力机制、位置编码、残差连接等,并探讨了训练过程中的正则化技巧。
一、这篇论文解决什么问题
序列转录:具体到论文中,就是机器翻译任务
之前一般如何解决:Encoder-Decoder + CNN/RNN + Attention
本文:只用Attention
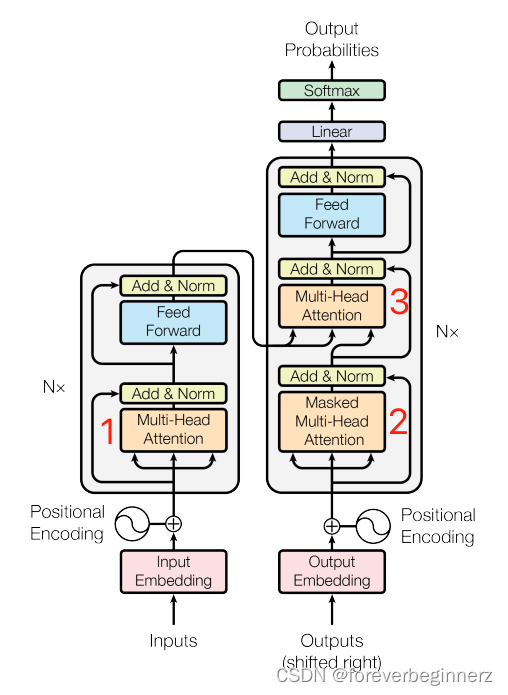
二、模型架构
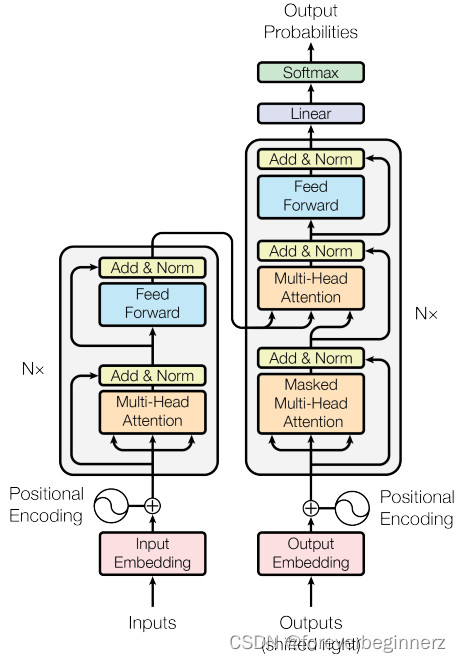
基础架构:Encoder-Decoder
- Encoder和Decoder其实都是一些相同层的堆叠
- Encoder中,
一次性生成
- Decoder中,
依次生成:
,
,
Embedding和Softmax
- 在Encoder输入、Decoder的输入以及Decoder的Linear需要Embedding
- 这些Embedding共享权重
- 权重需要乘以
:训练的过程中,
会变小,通过这样的方式可以扩大权重,这样和Positional Encoding的权重就在同一个规模上
Positional Encoding
Positional Encoding的功能是在输入时添加时序信息:attention虽然能够提取序列的信息,但是不会提取时序信息(假设词的顺序打乱,顺序会变,但attention提取的信息不受影响)
本质上是用长度为的向量表示一个词的位置
Attention
一般的Attention(query、key、value)
- 输出是value的加权和
- value的权重:根据query和key的相似度得到的(相似度的计算可以有多种方式)
Transformer中的Attention特殊在哪里
Scaled Dot-Product Attention
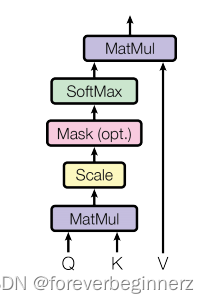
- 相似度使用点积
- 为什么要除以
:当
比较大的时候,点积的结果可能会很大,梯度会变得比较小,所以要缩小点积的结果
- 如何做mask:在计算权重即计算softmax值的时候,希望部分权重为0,具体操作是在做softmax之前将需要mask的位置设置成很大的负数
Multi-Head Attention
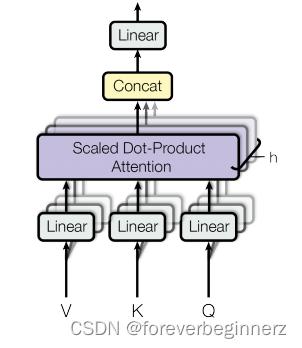
,
其中,
,
,
本文的base模型:
执行过程:
- 通过一个线性层,将原始的query、key、value投影到较低的维度
- 然后做h次scaled Dot-Product Attention
- 将上述结果进行拼接
- 再通过一个线性层,将拼接向量再次投影到原来的维度
可以看出,如果不做MultiHead,直接做Dot-Product Attention,其实没什么可以学习的参数,而在MultiHead的操作中,两次线性层的投影是可以学习到一些参数的
Transformer中的Attention如何应用
1. Multi-Head Self Attention
这个Attention在Encoder中,其实是同一个东西,维度为
,经过投影后,
的维度均为
,
的维度为
,得到的每一个head的输出维度为
,拼接之后的维度为
,经过再次投影输出维度为
2. Masked Multi-Head Self Attention
这个Attention在Decoder中,与Encoder中的Multi-Head Self Attention不同的是:增加了mask操作;的维度均为
,m不一定等于n
3. Multi-Head Attention
这个Attention在Decoder中,不是Self Attention,其中是同一个东西,都来自于Encoder的输出,维度为
,
来自于Decoder中Masked Multi-Head Self Attention的输出,维度为
,经过投影后,
的维度为
,
的维度为
,
的维度为
,得到的每一个head的输出维度为
,拼接之后的维度为
,经过再次投影输出维度为
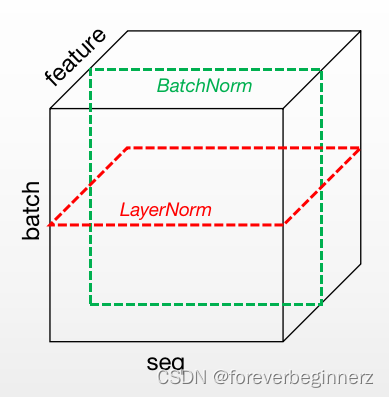
LayerNorm
Transformer的Normalization方法是LayerNorm
LayerNorm和BatchNorm的区别:
- LayerNorm:针对每个样本;序列长度变化较大的情况下,均值、方差抖动很小
- BatchNorm:针对每个特征;序列长度变化较大的情况下,均值、方差抖动很大
Position-wise Feed-Forward Networks
- 两层全连接
- max部分:ReLU
- FFN处理前后维度不变:
- 为什么是position-wise:attention之后,已经全局地抽取了序列中的信息,这里用MLP只是做一个语义空间的转换(与此不同的是,RNN每个时间步上并没有全局性地拿到序列的信息,因此每次都需要边抽取序列信息边做语义空间的转换)
三、训练时的核心细节——正则化
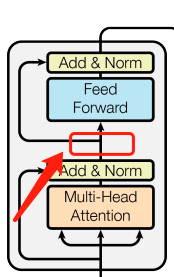
Residual Dropout
对每一个带权重的层都是用的dropout,
1. 在子层输出上添加dropout
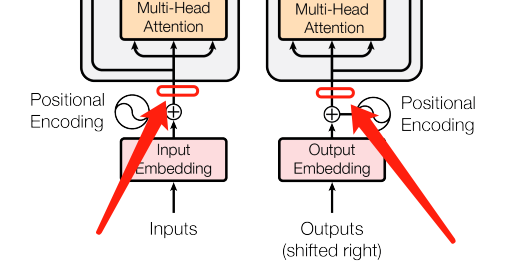
2. 在embedding的和上增加dropout
Label Smoothing
意思就是,对于正确的label,softmax的输出超过0.1即可(说明对置信度的要求很低)
四、这篇论文base模型和big模型的超参
| base | 6 | 512 | 2048 | 8 | 64 | 64 | 0.1 | 0.1 | 100K |
| big | 6 | 1024 | 4096 | 16 | 64 | 64 | 0.3 | 0.1 | 300K |
PS:本文大部分公式和图片都来自于,对本文的理解来自于对论文Attention Is All You Need的学习及对李沐大神讲解李沐大神讲解的学习,有理解不对的地方,欢迎指正

















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







