






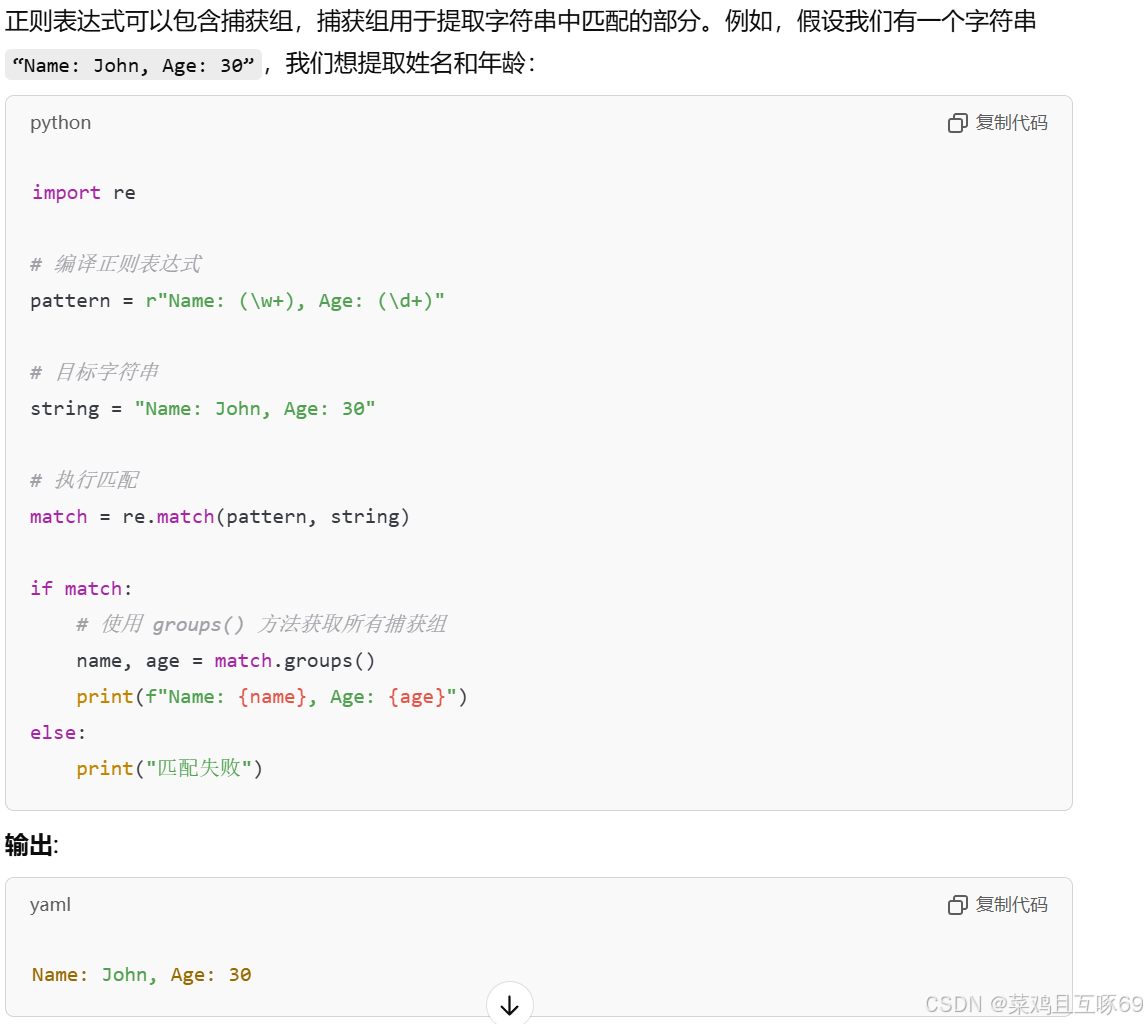
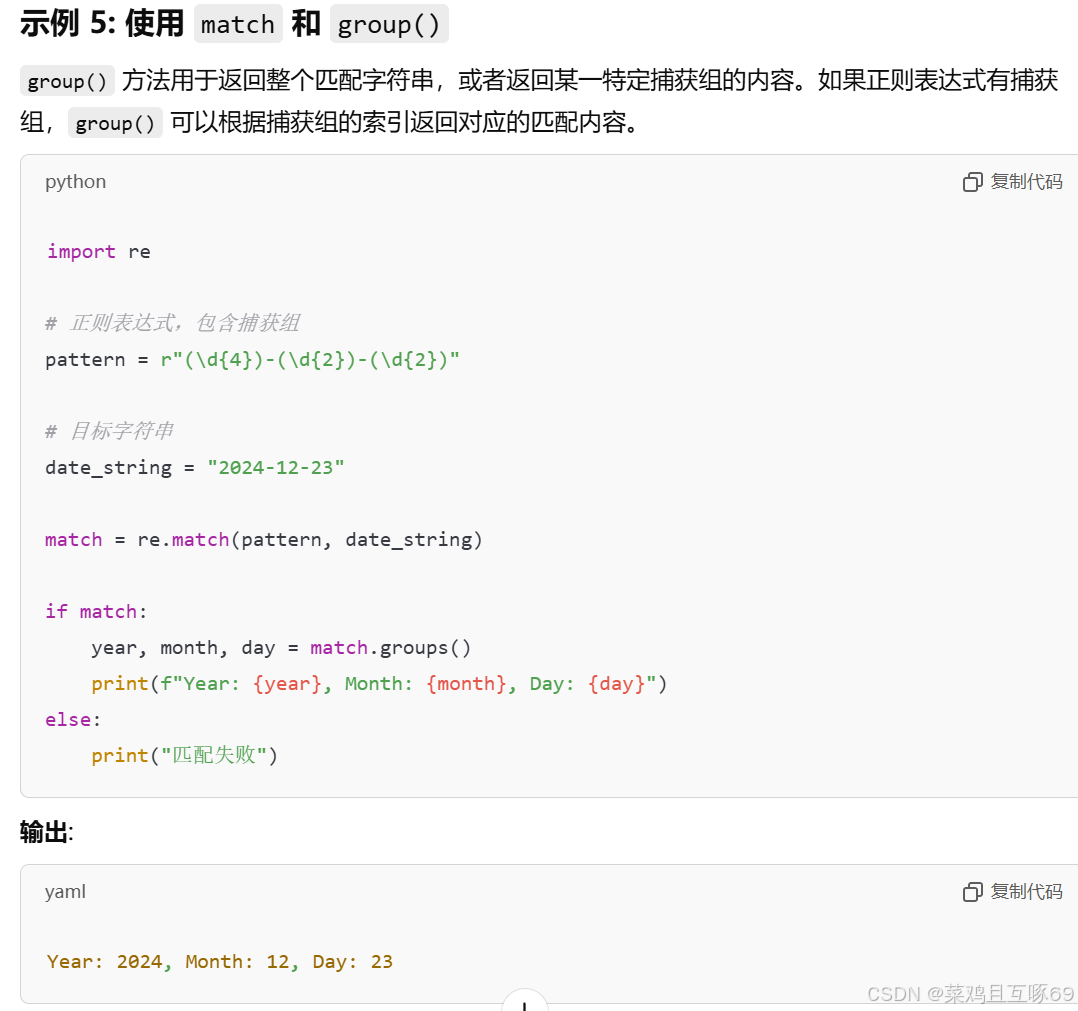
通过re.match匹配成功,可以使⽤group⽅法来提取数据。group() 同group(0)就是匹配正则表达式整体结果,group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分。
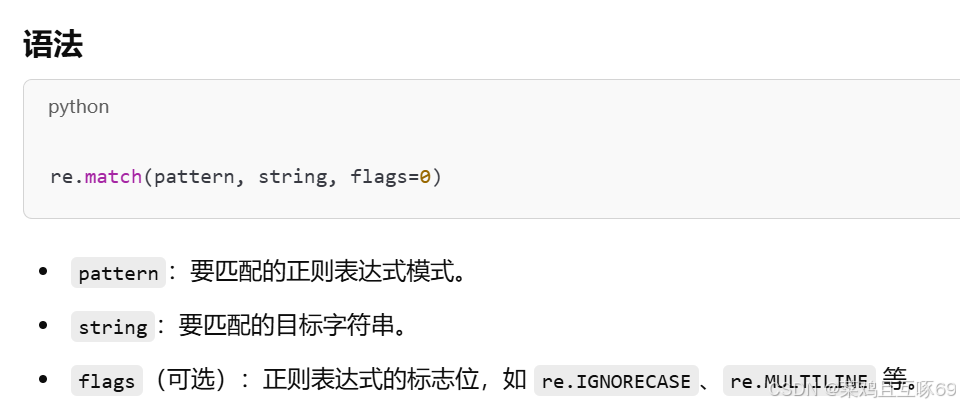
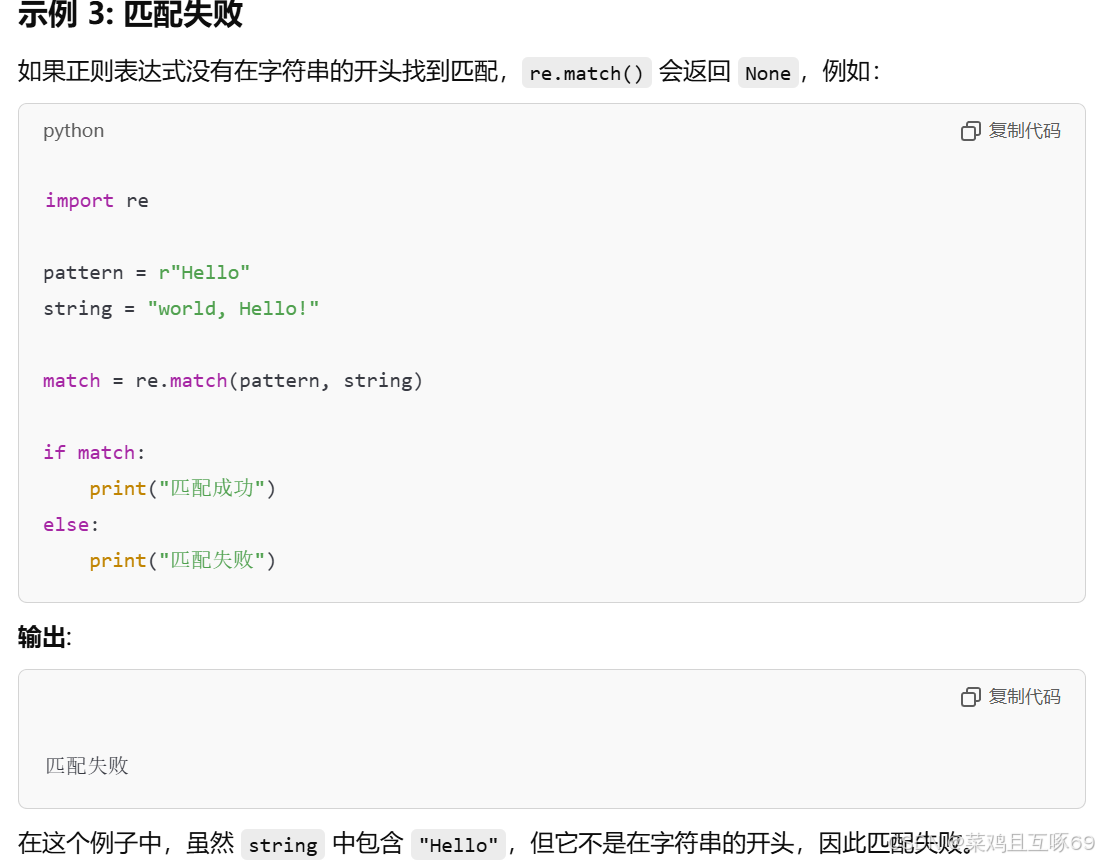
re.match() 是 Python 中 re 模块的一个函数,用于尝试从字符串的开头开始匹配正则表达式。如果正则表达式在字符串的起始位置匹配成功,re.match() 返回一个匹配对象;如果匹配失败,返回 None


groups是返回匹配到的两个括号中的内容
import re
line = "Cats are smarter than dogs"
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
# (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
matchObj = re.match(r'(.*?) are (.*?) ', line, re.M | re.I)
if matchObj:
print("matchObj.group() : ", matchObj.group())
print("matchObj.group(1) : ", matchObj.group(1))
print("matchObj.group(2) : ", matchObj.group(2))
else:
print("No match!!")


















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









