







 本文详细介绍了RabbitMQ、Kafka和EMQ在项目中的应用及其优缺点,包括如何保证消息不丢失、解决重复消费问题、处理消息堆积、确保消费顺序性以及各自高可用机制。重点探讨了各组件的使用场景、消息持久化、死信处理和延迟队列等关键特性,为企业服务通信和物联网通信提供了实用的解决方案。
本文详细介绍了RabbitMQ、Kafka和EMQ在项目中的应用及其优缺点,包括如何保证消息不丢失、解决重复消费问题、处理消息堆积、确保消费顺序性以及各自高可用机制。重点探讨了各组件的使用场景、消息持久化、死信处理和延迟队列等关键特性,为企业服务通信和物联网通信提供了实用的解决方案。
RabbitMQ
01- 你们项目中哪里用到了RabbitMQ ?
我们项目中很多地方都使用了RabbitMQ , RabbitMQ 是我们项目中服务通信的主要方式之一 , 我们项目中服务通信主要有二种方式实现 :
- 通过Feign实现服务调用
- 通过MQ实现服务通信
基本上除了查询请求之外, 大部分的服务调用都采用的是MQ实现的异步调用 , 例如 :
- 发布内容的异步审核
- 验证码的异步发送
- 用户行为数据的异步采集入库
- 搜索历史记录的异步保存
- 用户信息修改的异步通知(用户修改信息之后, 同步修改其他服务中冗余/缓存的用户信息)
- 静态化页面的生成
- MYSQL和Redis , ES之间的数据同步
- …
02- 为什么会选择使用RabbitMQ ? 有什么好处 ?
选择使用RabbitMQ是因为RabbitMQ的功能比较丰富 , 支持各种消息收发模式(简单队列模式, 工作队列模式 , 路由模式 , 直接模式 , 主题模式等) , 支持延迟队列 , 惰性队列而且天然支持集群, 保证服务的高可用, 同时性能非常不错 , 社区也比较活跃, 文档资料非常丰富
连续三天都登录过app , 查询用户id
使用MQ有很多好处:
-
吞吐量提升:无需等待订阅者处理完成,响应更快速
-
故障隔离:服务没有直接调用,不存在级联失败问题
-
调用间没有阻塞,不会造成无效的资源占用
-
耦合度极低,每个服务都可以灵活插拔,可替换
-
流量削峰:不管发布事件的流量波动多大,都由Broker接收,订阅者可以按照自己的速度去处理事件
使用MQ也有很多缺点:
- 架构复杂了,业务没有明显的流程线,不好管理
- 需要依赖于Broker的可靠、安全、性能
03- 使用RabbitMQ如何保证消息不丢失 ?
消息从发送,到消费者接收,会经理多个过程 , 其中的每一步都可能导致消息丢失
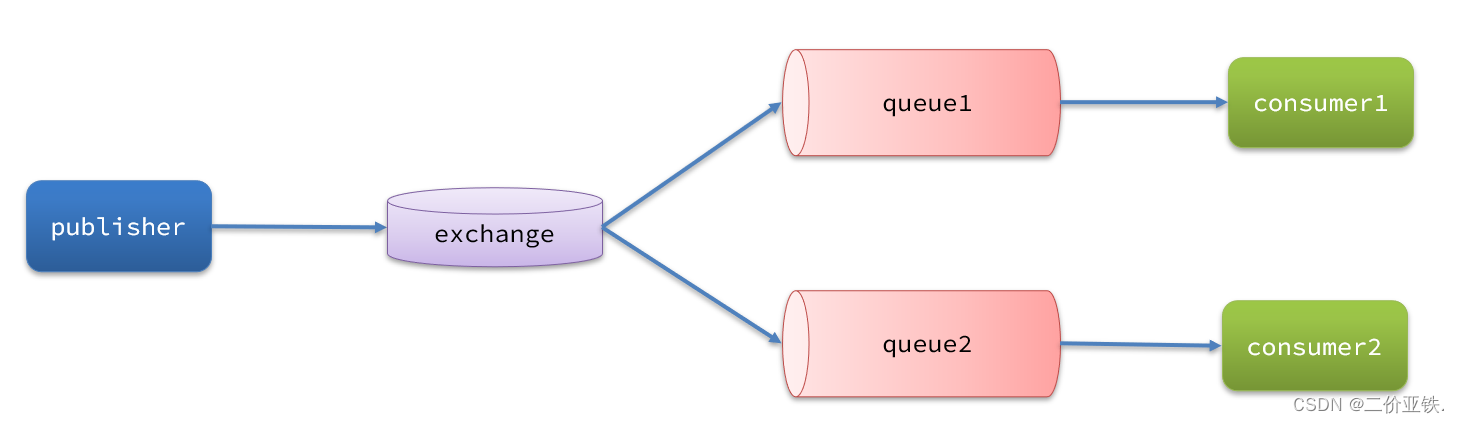
针对这些问题,RabbitMQ分别给出了解决方案:
-
消息发送到交换机丢失 : 发布者确认机制
publisher-confirm消息发送到交换机失败会向生产者返回ACK , 生产者通过回调接收发送结果 , 如果发送失败, 重新发送, 或者记录日志人工介入
-
消息从交换机路由到队列丢失 : 发布者回执机制
publisher-return消息从交换机路由到队列失败会向生产者返回失败原因 , 生产者通过回调接收回调结果 , 如果发送失败, 重新发送, 或者记录日志人工介入
-
消息保存到队列中丢失 : MQ持久化(交换机持久化, 队列持久化 , 消息持久化)
-
消费者消费消息丢失 : 消费者确认机制 , 消费者失败重试机制
通过RabbitMQ本身所提供的机制基本上已经可以保证消息不丢失 , 但是因为一些特殊的原因还是会发送消息丢失问题 , 例如 : 回调丢失 , 系统宕机, 磁盘损坏等 , 这种概率很小 , 但是如果想规避这些问题 , 进一步提高消息发送的成功率, 也可以通过程序自己进行控制
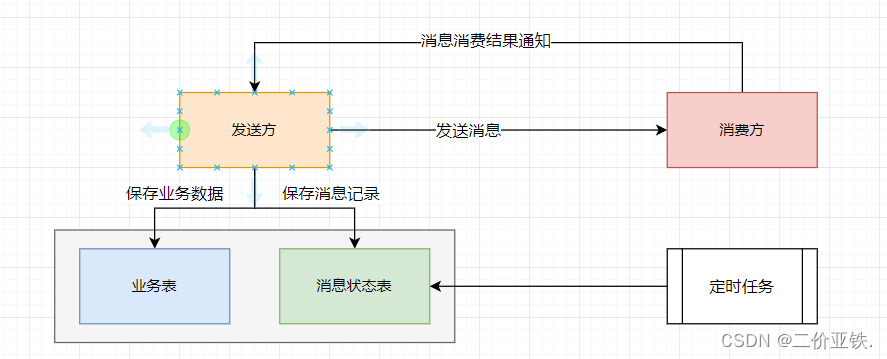
设计一个消息状态表 , 主要包含 : 消息id , 消息内容 , 交换机 , 消息路由key , 发送时间, 签收状态等字段 , 发送方业务执行完毕之后 , 向消息状态表保存一条消息记录, 消息状态为未签收 , 之后再向MQ发送消息 , 消费方接收消息消费完毕之后 , 向发送方发送一条签收消息 , 发送方接收到签收消息之后 , 修改消息状态表中的消息状态为已签收 ! 之后通过定时任务扫描消息状态表中这些未签收的消息 , 重新发送消息, 直到成功为止 , 对于已经完成消费的消息定时清理即可 !
04- 消息的重复消费问题如何解决的 ?
在使用RabbitMQ进行消息收发的时候, 如果发送失败或者消费失败会自动进行重试, 那么就有可能会导致消息的重复消费 , 具体的解决方案其实非常简单, 为每条消息设置一个唯一的标识id , 将已经消费的消息记录保存起来 , 后期再进行消费的时候判断是否已经消费过即可 , 如果已经消费过则不消费 , 如果没有消费过则正常消费
05- 如果有100万消息堆积在MQ , 如何解决 ?
解决消息堆积有三种思路:
-
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4855
4855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











