






下采样:下采样即通过从原始数据集中以随机或其他特定规则减少多数类样本数量,使数据集达到类平衡状态,以解决数据集中类不平衡问题,提升模型训练效果和效率。
过采样:过采样即通过增加少数类样本数量的方式来解决数据集中类不平衡问题,通常采用复制少数类样本或生成新的少数类样本等方法,使各类样本数量更趋于均衡,以提升模型对少数类的学习效果。
下面让我们来通过代码实现下采样和过采样,还是用之前的银行贷款问题举例
首先对于下采样
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
import numpy as np
#绘制可视化混淆矩阵
def cm_plot(y,p):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm=confusion_matrix(y,p)
plt.matshow(cm,cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data=pd.read_csv('creditcard.csv')#读取数据
#数据标准化,Z标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
a=data[['Amount']]
data['Amount']=scaler.fit_transform(data[['Amount']])
data=data.drop(['Time'],axis=1)
from sklearn.model_selection import train_test_split#该函数主要用于将数据划分成训练集和测试集
X=data.drop('Class',axis=1)
y=data.Class
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)#test_size=0.3分割测试集占30%,random_state=0随机种子
#下采样
data_train = pd.concat([x_train.reset_index(drop=True), y_train.reset_index(drop=True)], axis=1)#将特征数据和标签合成一个完整的数据集
positive_eg=data_train[data_train['Class']==0]#获取所有标签为0的数据
negative_eg=data_train[data_train['Class']==1]
np.random.seed(seed=5)#随机种子
positive_eg=positive_eg.sample(len(negative_eg))#sample表示随机从参数里面选择数据,从正例中随机获得与负例相同的数据量
data_c=pd.concat([positive_eg,negative_eg])#合并正负例
print(data_c)
#划分特征和标签
x_data=data_c.drop('Class',axis=1)
y_data=data_c.Class
x_data_train,x_data_test,y_data_train,y_data_test=train_test_split(x_data,y_data,test_size=0.3,random_state=10)#划分训练集和测试集
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
scores=[]
c_param_range=[0.01,0.1,1,10,100]
for i in c_param_range:
lr=LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000)
score=cross_val_score(lr,x_data_train,y_data_train,cv=8,scoring='recall')#交叉验证,scoring='recall'获取召回率
print(score)
score_mean=sum(score)/len(score)
scores.append(score_mean)
print(score_mean)
best_c=c_param_range[np.argmax(scores)]
lr=LogisticRegression(C=best_c,penalty='l2',max_iter=1000)
lr.fit(x_data_train,y_data_train)
from sklearn import metrics
train_data_predicted=lr.predict(x_data_train)#自测
print(metrics.classification_report(y_data_train,train_data_predicted))
# cm_plot(y_train,train_data_predicted).show()
test_data_predicted=lr.predict(x_data_test)#验证
print(metrics.classification_report(y_data_test,test_data_predicted))
# cm_plot(y_test,test_data_predicted).show()
test_predicted=lr.predict(x_test)#原始测试集预测
print(metrics.classification_report(y_test,test_predicted))
lr=LogisticRegression(C=best_c,penalty='l2')
lr.fit(x_data_train,y_data_train)
#调整分类阈值,根据不同的阈值(thresholds)将概率转换为类别标签。计算并打印每个阈值对应的召回
thresholds=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
recalls=[]
for i in thresholds:
y_predict_proba=lr.predict_proba(x_data_test)
y_predict_proba=pd.DataFrame(y_predict_proba)
y_predict_proba=y_predict_proba.drop([0],axis=1)
y_predict_proba[y_predict_proba[[1]]>i]=1
y_predict_proba[y_predict_proba[[1]]<=i]=0
recall=metrics.recall_score(y_data_test,y_predict_proba[1])
recalls.append(recall)
print(f"{i}Recall metric in the testing dataset:{recall:.3f}")最终我们得到结果
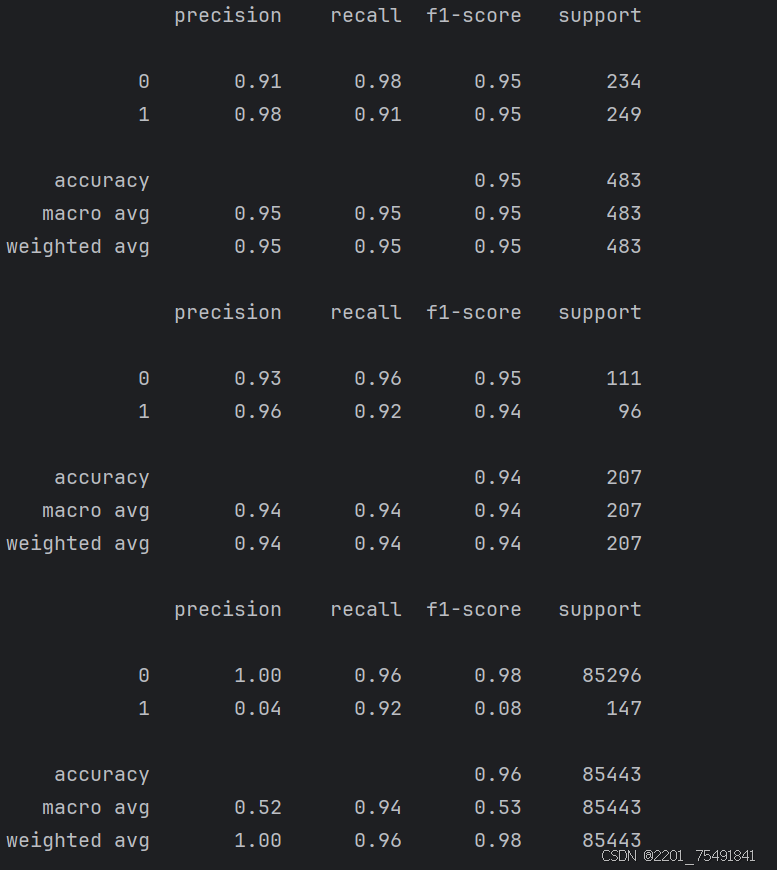
可以发现此时的召回率相比之前有了大大提升
对于过采样
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
import numpy as np
from imblearn.over_sampling import SMOTE
#绘制可视化混淆矩阵
def cm_plot(y,p):
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
cm=confusion_matrix(y,p)
plt.matshow(cm,cmap=plt.cm.Blues)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y],xy=(y,x),horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label')
plt.xlabel('Predicted label')
return plt
data=pd.read_csv('creditcard.csv')
#数据标准化,Z标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
a=data[['Amount']]
data['Amount']=scaler.fit_transform(data[['Amount']])
data=data.drop(['Time'],axis=1)
from sklearn.model_selection import train_test_split#该函数主要用于将数据划分成训练集和测试集
X=data.drop('Class',axis=1)
y=data.Class
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=0)#test_size=0.3分割测试集占30%,random_state=0随机种子
#######################################################################
oversampler=SMOTE(random_state=0)
os_x_train,os_y_train=oversampler.fit_resample(x_train,y_train)
mpl.rcParams['font.sans-serif']=['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus']=False
labels_count=pd.value_counts(os_y_train)
plt.title("正负例样本数")
plt.xlabel("类别")
plt.ylabel("频数")
labels_count.plot(kind='bar')
plt.show()
###
data_train = pd.concat([os_x_train.reset_index(drop=True), os_y_train.reset_index(drop=True)], axis=1)
x_data=data_train.drop('Class',axis=1)
y_data=data_train.Class
###
x_data_train,x_data_test,y_data_train,y_data_test=train_test_split(x_data,y_data,test_size=0.3,random_state=10)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
scores=[]
c_param_range=[0.01,0.1,1,10,100]
for i in c_param_range:
lr=LogisticRegression(C=i,penalty='l2',solver='lbfgs',max_iter=1000)
score=cross_val_score(lr,x_data_train,y_data_train,cv=8,scoring='recall')#交叉验证,scoring='recall'获取召回率
print(score)
score_mean=sum(score)/len(score)
scores.append(score_mean)
print(score_mean)
best_c=c_param_range[np.argmax(scores)]
lr=LogisticRegression(C=best_c,penalty='l2',max_iter=1000)
lr.fit(x_data_train,y_data_train)
from sklearn import metrics
train_data_predicted=lr.predict(x_data_train)#自测
print(metrics.classification_report(y_data_train,train_data_predicted))
# cm_plot(y_train,train_data_predicted).show()
test_data_predicted=lr.predict(x_data_test)
print(metrics.classification_report(y_data_test,test_data_predicted))
# cm_plot(y_test,test_data_predicted).show()
test_predicted=lr.predict(x_test)
print(metrics.classification_report(y_test,test_predicted))
lr=LogisticRegression(C=best_c,penalty='l2')
lr.fit(x_data_train,y_data_train)
#设定阈值(sigmod函数的分类值)
thresholds=[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
recalls=[]
for i in thresholds:
y_predict_proba=lr.predict_proba(x_data_test)
y_predict_proba=pd.DataFrame(y_predict_proba)
y_predict_proba=y_predict_proba.drop([0],axis=1)
y_predict_proba[y_predict_proba[[1]]>i]=1
y_predict_proba[y_predict_proba[[1]]<=i]=0
recall=metrics.recall_score(y_data_test,y_predict_proba[1])
recalls.append(recall)
print(f"{i}Recall metric in the testing dataset:{recall:.3f}")得到如下结果
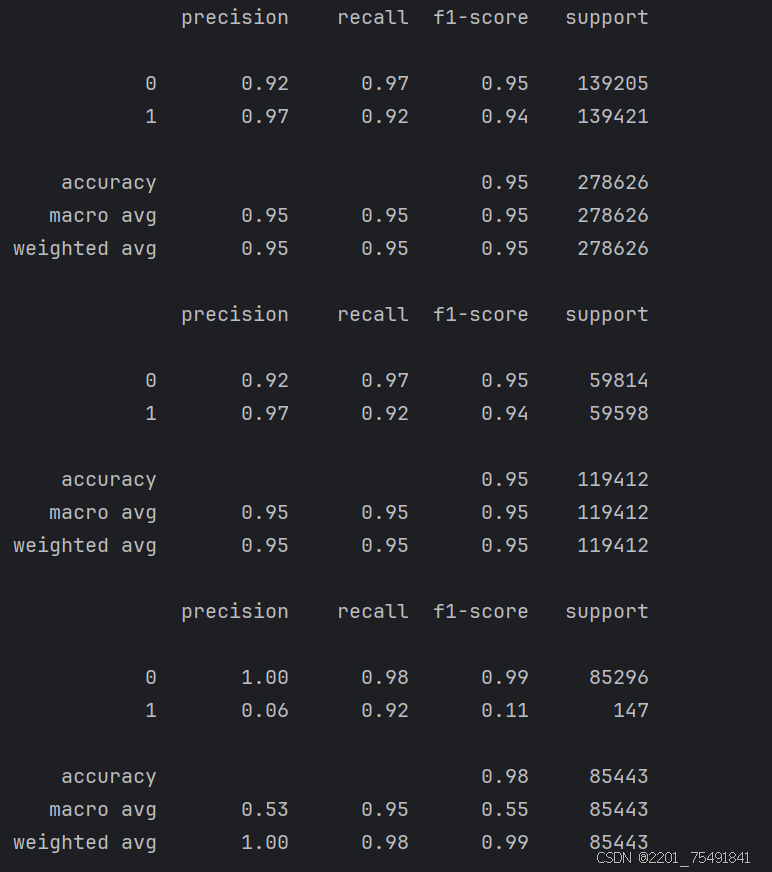
可以发现对数据进行下采样或过采样处理也能大大提升模型性能


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









