



工具:request、beautifulSoup
打开f12发现某度的数据是直接在html中,可通过提取seletor来直接获取数据
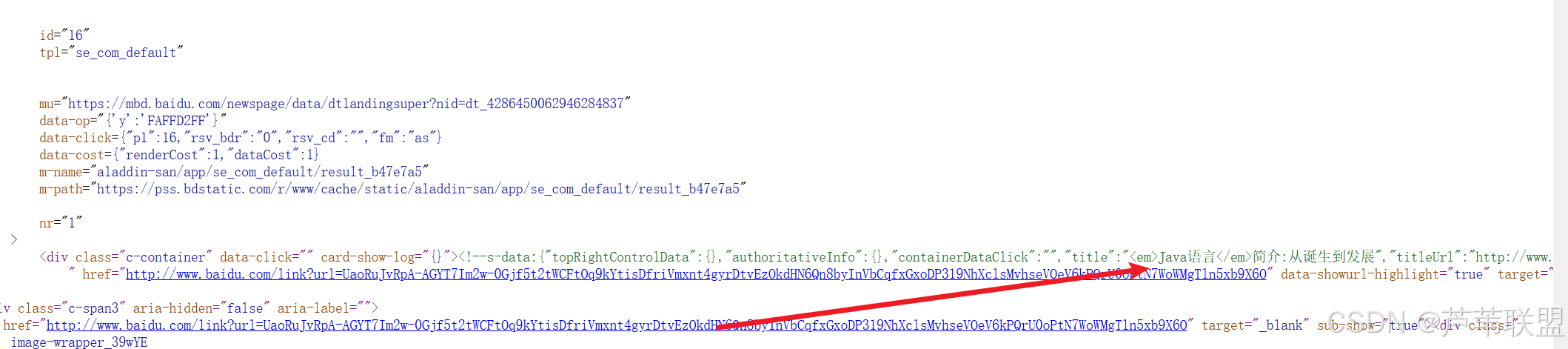
第一步:构造请求(request)
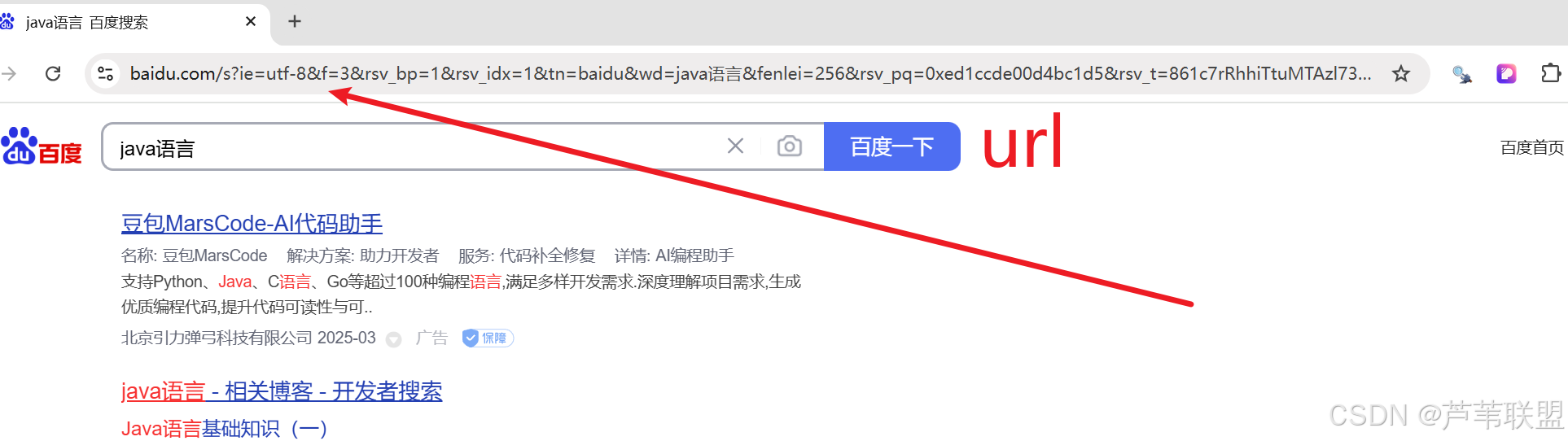
url="https://www.baidu.com/s?wd=java%E8%AF%AD%E8%A8%80&pn=10&oq=java%E8%AF%AD%E8%A8%80&ie=utf-8&usm=3&fenlei=256&rsv_idx=1&rsv_pq=e959d5a30424e6ba&rsv_t=5e8cVda4XcoIsHY%2FEwUcjZki0vJVl%2BuC4idEZ3%2F2pk62eKw3cpCkax1XmAE"
headers={
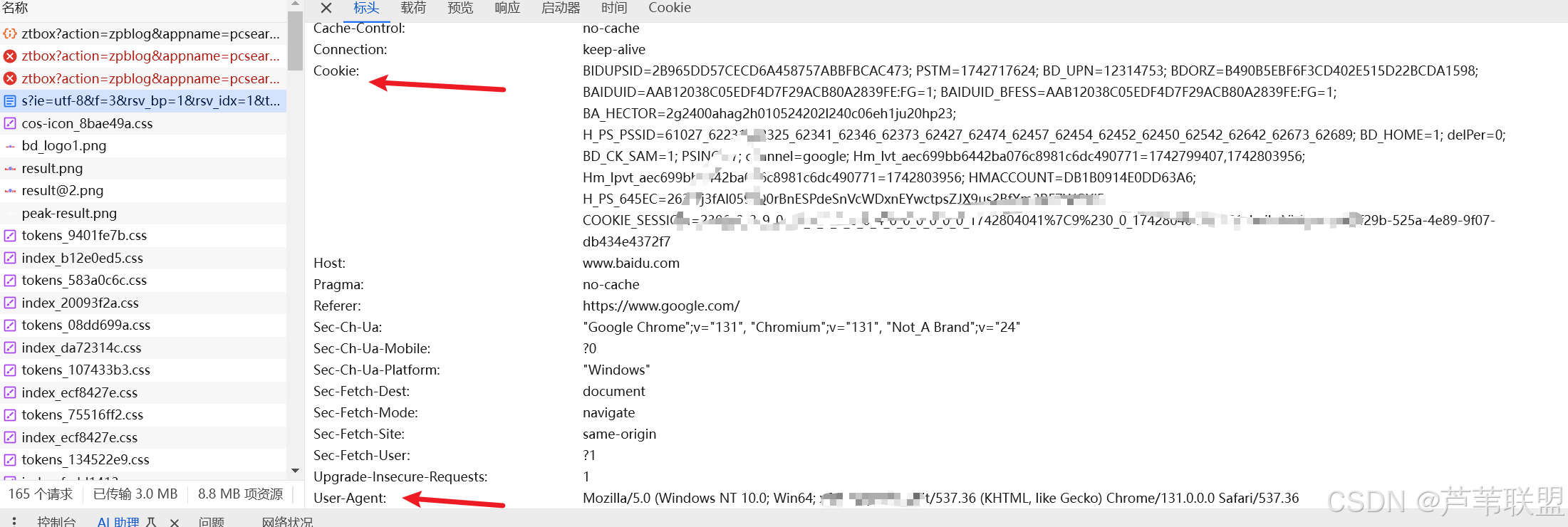
"cookie":"BIDUPSID=2B965DD57CECD6A458757ABBFBCAC473; PSTM=1742717624; BD_UPN=12314753; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID=AAB12038C05EDF4D7F29ACB80A2839FE:FG=1; delPer=0; BD_CK_SAM=1; PSINO=6; BAIDUID_BFESS=AAB12038C05EDF4D7F29ACB80A2839FE:FG=1; BA_HECTOR=2g2400ahag2h010524202l240c06eh1ju20hp23; H_PS_PSSID=61027_62231_62325_62341_62346_62373_62427_62474_62457_62454_62452_62450_62542_62642_62673_62689; BD_HOME=1; H_PS_645EC=290eto1Au%2FZ2hcBUs3aG35250BfKiSR%2BRXtsddurehzwhaCJXQWDbu%2BuqFE; BDSVRTM=890; COOKIE_SESSION=19_0_2_9_0_14_1_1_1_8_1_3_0_0_0_0_0_0_1742799428%7C9%230_0_1742799428%7C1; channel=baidusearch; baikeVisitId=ab3d6f1a-63c8-4119-a974-21b5a65b7ceb",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
html = requests.get(url,headers=headers)头部信息可通过网络抓包获取。
url从浏览器信息栏获取
第二步:解析
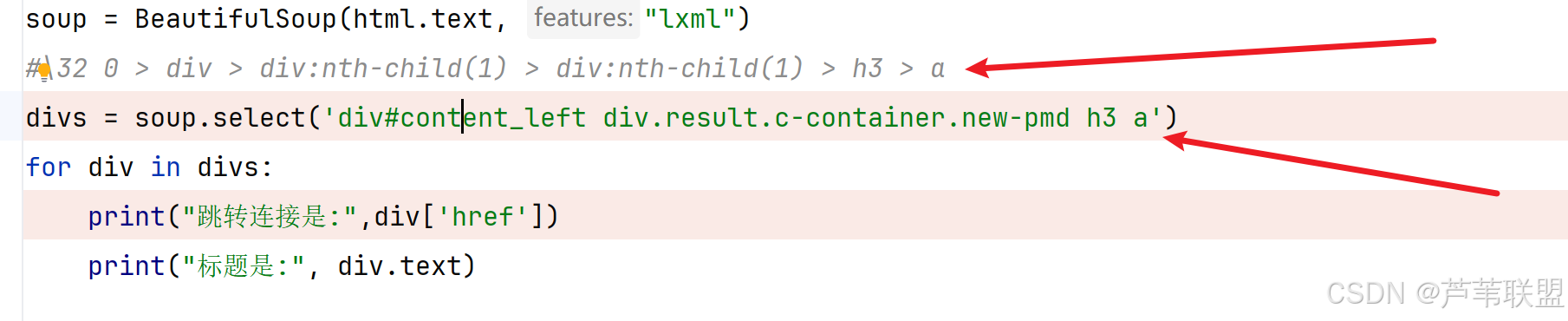 注:selector不可直接通过浏览器右键解析转义,BeautifulSoup不支持CSS选择器中的:nth-child()伪类。需要手动处理层级关系
注:selector不可直接通过浏览器右键解析转义,BeautifulSoup不支持CSS选择器中的:nth-child()伪类。需要手动处理层级关系
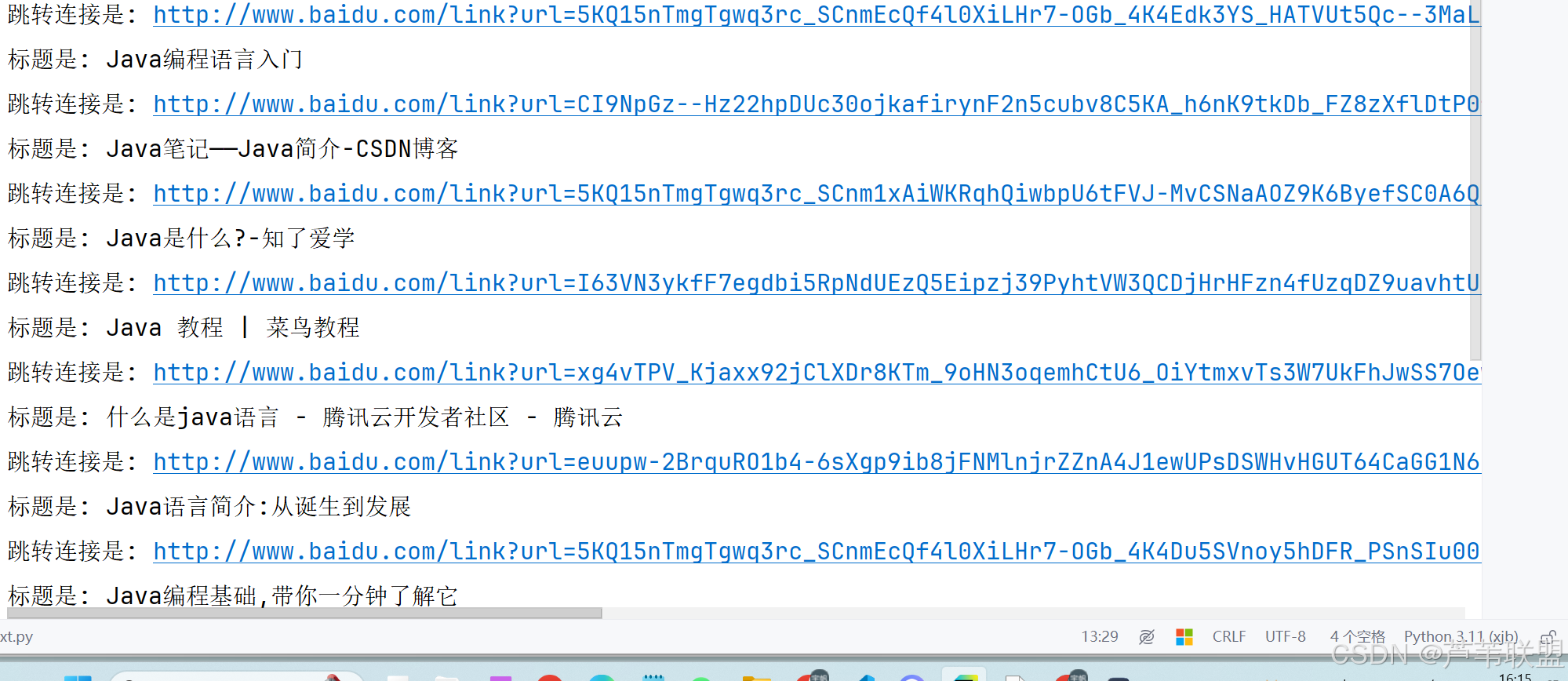
结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









