






最近,要做个迎宾机器人,其中得实现语音交互功能,就记录一下创作过程。
首先,我是调用阿里云的大模型接口的,所以得在阿里云百炼上注册账号。
阿里云百炼官网:阿里云登录 - 欢迎登录阿里云,安全稳定的云计算服务平台
如果是学生的话,可以在阿里云官网进行学生认证,有300元的代金券,用来做研究绰绰有余。
阿里云官网:阿里云-计算,为了无法计算的价值
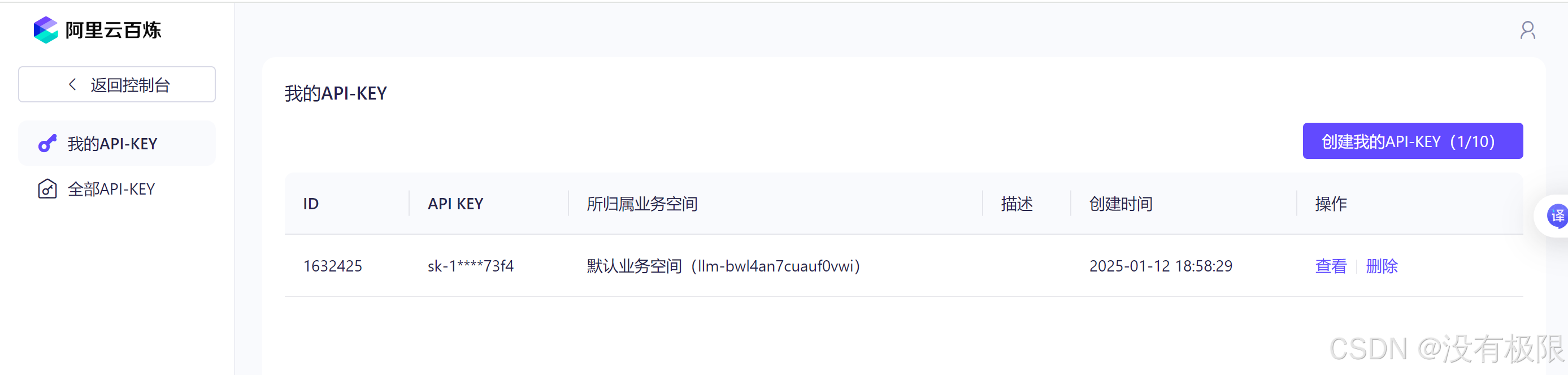
登录进去后,创建一个API-KEY,为了后续能够调用各种AI大模型
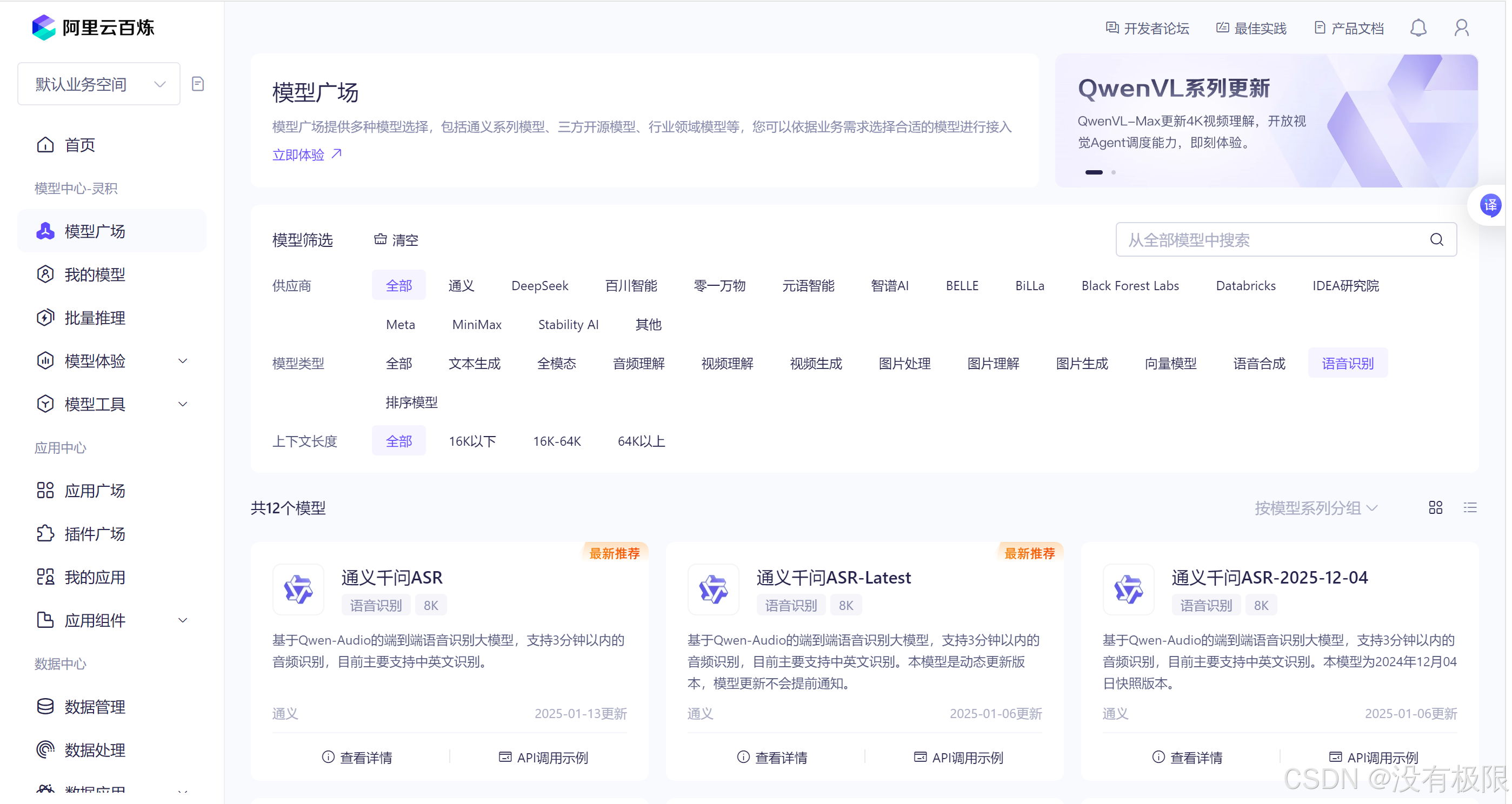
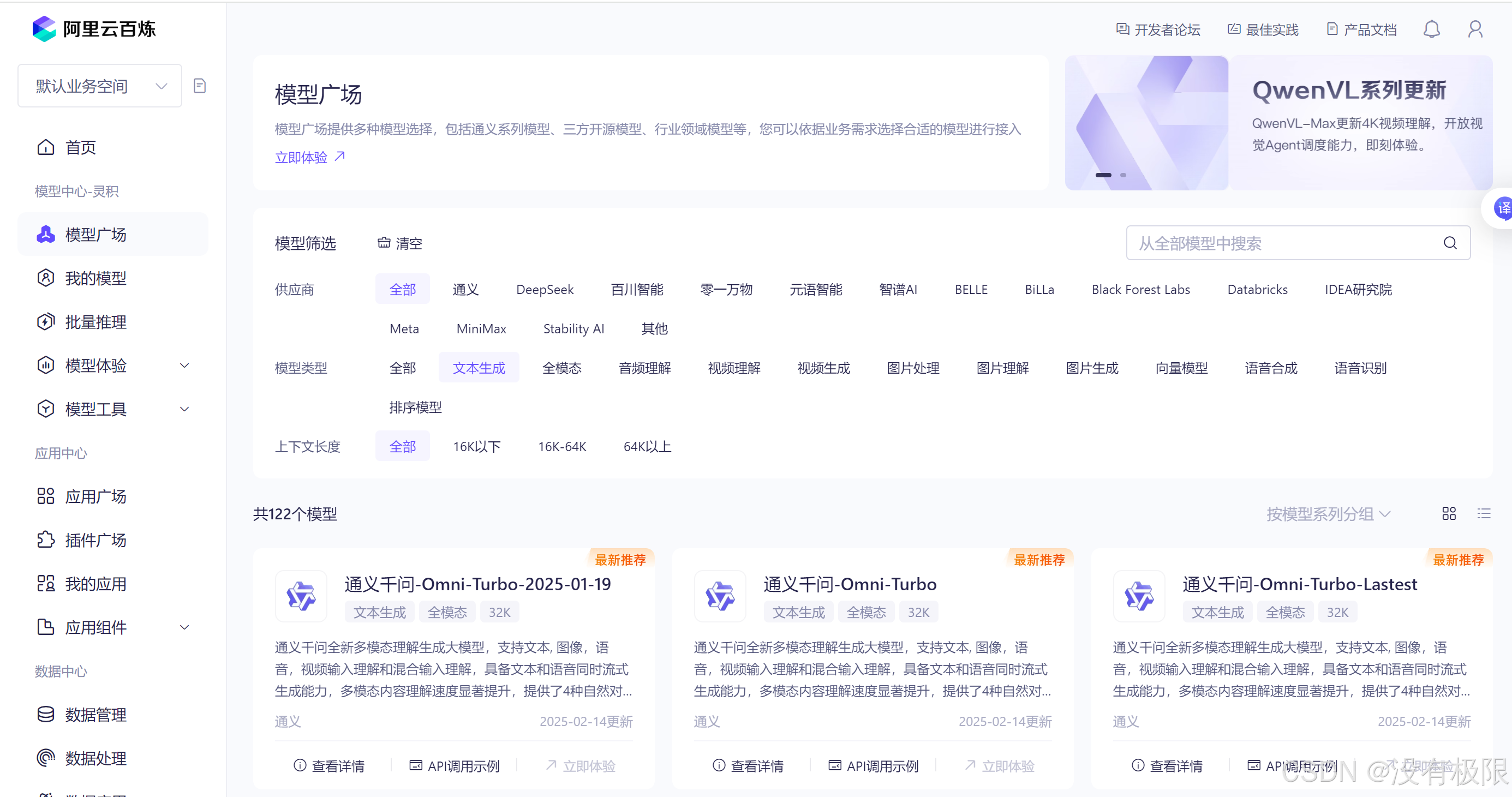
接着,回到创作部分,语音交互,可以简单分解为三个模块:语音识别模块、文字对话模块、语音合成模块。先来看语音识别模块。
在阿里云百炼的模型广场上找到语音识别的大模型
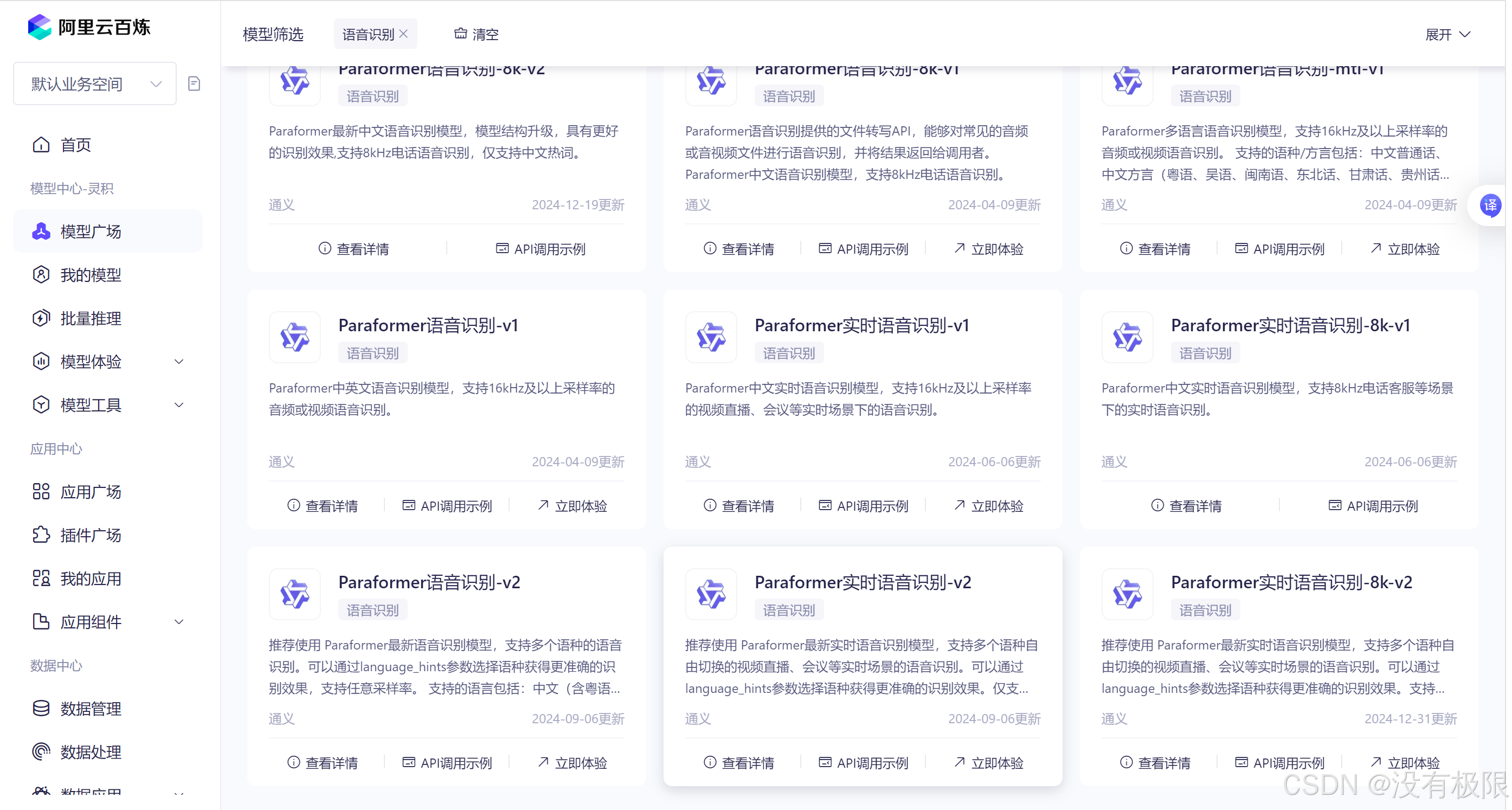
里面有很多模型,我做的语音交互模块要求实时听到语音并输出,所以选的是Paraformer实时语音识别-v2。 点击API调用示例,可以查看如何编写调用代码。
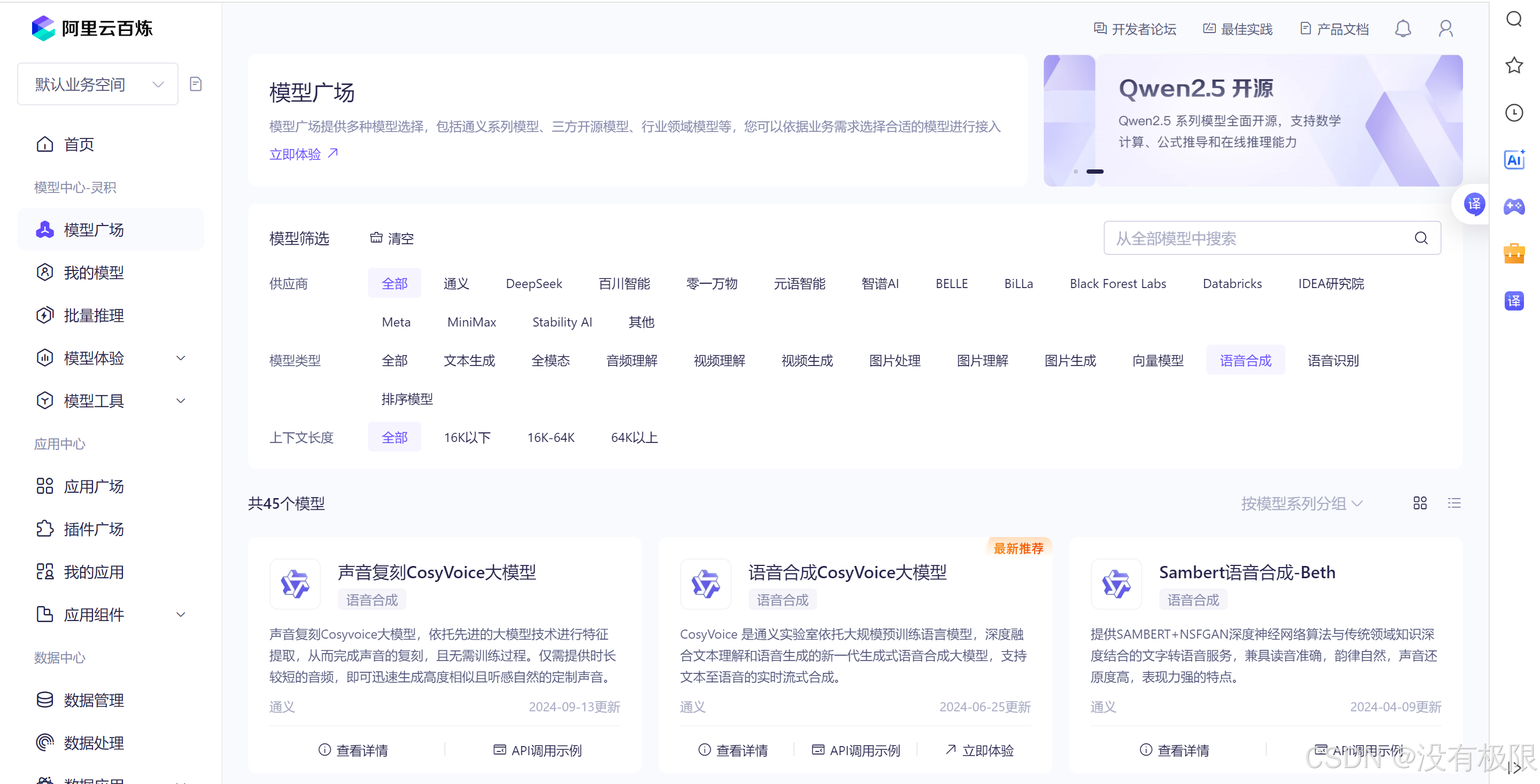
 同样的道理,在文本生成、语音合成那里分别选择一个模型,就可完成大模型的配置。
同样的道理,在文本生成、语音合成那里分别选择一个模型,就可完成大模型的配置。
文本生成我选的是通义千问-Plus,语音合成我选的是语音合成CosyVoice大模型。
在理解了各个模型的调用方法后,便可根据自己的项目要求编写代码了。
这里给上我写的代码
为了使用户能够看到聊天界面和控制聊天的开关,我用pygame显示了语音识别和文字生成的的文字,增加效果显示。将dashcope.api_key替换成自己在阿里云百炼上创建的API-KEY即可运行代码。
from openai import OpenAI
import dashscope
from dashscope.api_entities.dashscope_response import SpeechSynthesisResponse
from dashscope.audio.tts_v2 import *
import pygame
import sys
import time
from dashscope.audio.asr import (Recognition, RecognitionCallback,RecognitionResult)
import pyaudio
import math
#语音识别的回调函数
class Rn_Callback(RecognitionCallback):
def __init__(self):
self.sentence_end=False
self.mic = None
self.stream = None
self.content=''
def on_open(self) -> None:
print('RecognitionCallback open.')
self.mic = pyaudio.PyAudio()
self.stream = self.mic.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True)
def on_close(self) -> None:
print('RecognitionCallback close.')
self.stream.stop_stream()
self.stream.close()
self.mic.terminate()
self.stream = None
self.mic = None
def on_event(self, result: RecognitionResult) -> None:
if result.get_sentence().get('sentence_end')==True:
print('This is the end',result.get_sentence().get('text'))
self.sentence_end=True
self.content+=result.get_sentence().get('text')
#语音合成的回调函数
class Rs_Callback(ResultCallback):
_player = None
_stream = None
def __init__(self):
self.boastcast=1
self.websocket=1
def on_open(self):
print("websocket is open.")
self._player = pyaudio.PyAudio()
self._stream = self._player.open(
format=pyaudio.paInt16, channels=1, rate=22050, output=True
)
def on_complete(self):
print("speech synthesis task complete successfully.")
def on_error(self, message: str):
print(f"speech synthesis task failed, {message}")
def on_close(self):
print("websocket is closed.")
# 停止播放器
self.websocket=0
self._stream.stop_stream()
self._stream.close()
self._player.terminate()
def on_event(self, message):
#print(f"recv speech synthsis message {message}")
return 1
def on_data(self, data: bytes) -> None:
#print("audio result length:", len(data))
self._stream.write(data)
class voice_interaction:
def __init__(self):
pygame.init()
dashscope.api_key = 'your_key'#这里使用自己在阿里云创建的API-KEY
self.model = "cosyvoice-v1" # 语音播放模型
self.voice = "longwan" # 语音声音人物
self.screen = pygame.display.set_mode((1000, 800))
pygame.display.set_caption('语音聊天界面')
self.interval = 20 # 字与字之间的间隔
# 设置楷体字体
self.font = pygame.font.SysFont('KaiTi', self.interval, bold=False, italic=False)
#如果是在树莓派系统上部署项目,使用pygame中自带的中文字体会出现乱码的问题,可在网上下载一个中文字体,放在项目文件夹中,使用下面这行代码显示字体
#self.font = pygame.font.Font('china.ttf', self.interval, bold=False, italic=False)
self.messages=[]
self.Rs_callback = Rs_Callback()
self.input_word=14#用户框的一行字数
self.output_word=25#助手框的一行字数
self.background=(232,238,242)#聊天界面背景颜色
def voice_recognition(self):
Rn_callback = Rn_Callback()
recognition = Recognition(model='paraformer-realtime-v2',
format='pcm',
sample_rate=16000,
callback=Rn_callback)
self.screen.fill(self.background)
self.y = 2
print('按下enter键开始对话')
begin_words=self.font.render('按下任意键开始对话',True,(128,128,128))
self.screen.blit(begin_words,(410,350))
pygame.display.update()
audio = 0
while audio == 0:
for event in pygame.event.get():
if event.type == pygame.QUIT: # 如果收到退出事件,则退出循环
pygame.quit()
sys.exit()
elif event.type == pygame.KEYDOWN:
self.screen.fill(self.background)
recog_words=self.font.render('正在识别语音......',True,(128,128,128))
self.screen.blit(recog_words,(410,350))
pygame.display.update()
recognition.start()
start_time=time.time()
while Rn_callback.sentence_end == False:
data = Rn_callback.stream.read(3200, exception_on_overflow=False)
recognition.send_audio_frame(data)
run_time=time.time()-start_time
if run_time>=10:
break
recognition.stop()
audio=1
self.screen.fill(self.background)
speak_words=self.font.render('对话生成中......',True,(128,128,128))
self.screen.blit(speak_words,(410,350))
pygame.display.update()
self.text = Rn_callback.content#识别语音输入的结果
if self.text=='':
self.text='。'
self.input=[]
self.row_number=math.ceil(len(self.text)/self.input_word)
green = pygame.Color('#7fffd4')
for i in range(self.row_number):
self.input.append(self.text[self.input_word*i:self.input_word*(i+1)])
if len(self.text)>=self.input_word:
first_position=890-self.input_word*self.interval#用户输入框文字的起始位置
pos = first_position - 5, self.interval * self.y - 5,self.input_word*self.interval+10,self.interval*self.row_number+10#矩形框的位置
else:
first_position=890-len(self.input[0])*20
pos=first_position-5,self.interval*self.y-5,self.interval*len(self.text)+5,self.interval+10
pygame.draw.rect(self.screen, green, pos, 0)
#如果想要显示用户头像,解除下面两行注释,并准备一个80*80像素的图片,放在项目文件夹中,更名为user.xxx,xxx为图片格式
#user_image = pygame.image.load('user.jpg') # 用户头像
#self.screen.blit(user_image, [900, 20]) # 显示用户头像
for word in self.input:
text_surface = self.font.render(word, True, (0, 0, 0))
self.screen.blit(text_surface, (first_position, self.interval*self.y))
self.y+=1
pygame.display.update()
def chat(self):
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=dashscope.api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
self.messages.append ({"role": "user", "content": self.text})
self.response = client.chat.completions.create(
model="qwen-plus",
messages=self.messages,
stream=True,
extra_body={
"enable_search": True
}
)
def voice_broadcast(self):
# 流式输出
null = 0
self.title_answers = []
self.synthesizer = SpeechSynthesizer(model=self.model, voice=self.voice,
format=AudioFormat.PCM_22050HZ_MONO_16BIT,
callback=self.Rs_callback, )
for chunk in self.response:
temp = eval(chunk.model_dump_json())
self.answer = temp['choices'][0]['delta']['content']
self.title_answers.append(self.answer)
print(self.answer)
result = self.synthesizer.streaming_call(self.answer)
self.title_answers=''.join(self.title_answers)
self.title_answers=self.title_answers.replace('*','')
self.title_answers=self.title_answers.replace('\n','')
self.title_answers=self.title_answers.replace('😊','')
self.title_answers=self.title_answers.replace('#','')
print(self.title_answers)
self.output=[]
yellow = pygame.Color('#FFF8DC')
output_row_number=math.ceil(len(self.title_answers)/self.output_word)
for i in range(output_row_number):
self.output.append(self.title_answers[self.output_word*i:self.output_word*(i+1)])
print(self.output[i])
if len(self.output[0])>=self.output_word:
width=self.interval*self.output_word+10
height=self.interval*output_row_number+10
else:
width=self.interval*len(self.output[0])+10
height=self.interval+10
pos_output=90-5,self.interval*self.y-5,width,height#输出端矩形框的位置
self.screen.fill(self.background,rect=(410,350,200,200))
skip_words = self.font.render('按下任意键进行下一轮对话', True, (128, 128, 128))
self.screen.blit(skip_words, (710, 350))
pygame.display.update()
pygame.draw.rect(self.screen, yellow, pos_output, 0)
#如果想显示助手头像,解除下面两行注释,并准备一张80*80像素的图片,放在项目文件夹中,更名为assistant.xxx,xxx为图片格式。
#img = pygame.image.load('assistant.png') #显示助手头像
#self.screen.blit(img, [0, 20*(self.y-1)])
for output_word in self.output:
text_surface = self.font.render(output_word, True, (0, 0, 0),yellow)
self.screen.blit(text_surface, (90, 20*self.y))
self.y+=1
pygame.display.update()
self.messages.append({"role": "assistant", "content": self.title_answers})
boastcast=1
while boastcast==1:
for event in pygame.event.get():
if event.type == pygame.QUIT: # 如果收到退出事件,则退出循环
pygame.quit()
sys.exit()
elif event.type == pygame.KEYDOWN:
if self.Rs_callback.websocket==1:
self.synthesizer.streaming_cancel()
boastcast=0
print('下一轮对话')
if __name__ == '__main__':
bot=voice_interaction()
while 1:
bot.voice_recognition()
bot.chat()
bot.voice_broadcast()

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









