




一、根据输出空间分类
1, 分类(classification)
1.1 二值分类 (binary classification):输出为 {+1, -1}。
那个银行发信用卡的案例中,对于任意用户,输出只可能有两个结果{η}={+1,-1},+1就发卡,-1就不发。这是一个简单的【二元分类问题】。同样的问题有很多,例如贷款(贷还是不贷)、签证(签还是不签)、答案(对还是不对)、邮件(是不是垃圾邮件)等。
1.2 多值分类 (multiclass classification):输出为有限个类别,{1, 2, 3, ... , K}
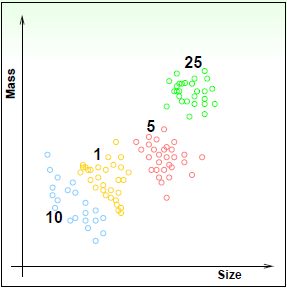
相对二元分类,当然有【多元分类问题】。例如,美分硬币共有四种(1、5、10、25美分),输入数据为(尺寸,重量),输出集合{η}={1美分,5美分,10美分,25美分}。这是一个4分类问题。
一般的讲,多元分类问题的输出可表示为:
{η}={ 1, 2,···,K } (K≥2)
二元分类问题是多元分类问题的一个特例,其K=2。
认知行为基本上都是分类问题,比如:
识别数字字符,输出为{η}={1,2,3,4,5,6,7,8,9,0};通过图像识别水果,输出为{η}={苹果,橘子,香蕉 ··· };识别垃圾邮件,输出为{η}={垃圾邮件,广告邮件,社交邮件 ··· }。
想象一下用不同的机器学习方法诊断病人。
二分类:病人数据 => { 你有病,你挺好的 };多分类:病人数据 => { 肺炎,感染,禽流感 ··· };
2, 回归(regression)
输出空间:实数集 R , 或 区间 [lower, upper]
病人数据 => 放心,你有99%的概率在N天后康复。。。大数据资料挖掘么,当一个机器了解了很多病人的特征、症状和康复数据后,将这些参数作为随机变量,机器能针对特定病人,用统计方法构建这些随机变量的概率密度函数。对于每一个病人,它们的康复就是可预测的了。
类似的问题还有,通过公司数据预测股票价格,通过气象数据预测降水概率等。
3, 结构学习(structured learning):典型的有序列化标注问题
输出是一个结构(如句子中每个单词的词性), 可以成为 hyperclass, 通常难以显示地定义该类。
-
自然语言处理(NLP)就属于此类问题。比如:
我 爱 机器学习
这句话中“我”是代词(Pronoun),“爱”是动词(Verb),“机器学习”是名词(Noun)。它与“PVN”结构匹配。同理,还可以存在“PVP”,"NVN"等很多组合,但一定不包括“VVV”这种不合乎语法的组合。此时,输出集{η}的内容不是显性确定的,而是由一套规则(这里是语法)隐性决定的。所以学习难度增加了。
小结,最基础的算法是二元分类和回归分析,以它们为基础可以构建出更复杂高级的学习算法。
二, 根据数据标签(label) 情况来分类。
训练数据集{D}不同
1, 有监督学习(supervised learning):训练数据中每个xi 对应一个标签yi。
应用:分类
即每一个有效的输入,都对应一个输出(x(i) -> y(i))。在硬币识别问题中,训练数据集D就是一堆美分硬币的重量与尺寸以及对应的面值。在寻找近似目标函数g的过程中,机器知道在哪些数据上有错误,并能正对错误不断迭代,最终找到犯错最少或不犯错的g函数。
以上过程有点像《越狱兔》里普京在狱卒的监督下分拣小鸡,它必须把混在一起的小鸡按性别分放在不同的容器里。假设普京不知道怎么区分小鸡性别,所以狱卒拿出50只小鸡先训练他(训练数据集D)。输入就是小鸡的外形特征,输出就是他的性别。如果普京放错了,狱卒就会拿鞭子虐他,他知道错了,下次看到有同样特征的小鸡就不会搞错他的性别了。
2, 无监督学习(unsupervised learning):没有指明每个xi 对应的是什么,即对x没有label。
应用:聚类,密度估计(density
estimation), 异常检测。
即每一个有效的输入都没有对应的输出(没有y(i))。我只给你一堆硬币的重量和尺寸,但我不告诉你对应的面值。所以你能做的只是把它们分成几类,但你并不知道每种类别的意义。
所以无监督学习很适合分群问题,密度估算,异常探测等。
分群问题:{x(n)} -> cluster(x)。例如输入文章内容划分文章主题。
密度估算:{x(n)} -> density(x)。例如输入交通数据,确定事故高发区。
异常探测:{x(n)} -> unusual(x)。例如输入网络日志,找到系统异常。
3, 半监督学习(semi-supervised learning):只有少量标注数据,利用未标注数据。
应用:人脸识别;医药效果检测。
即在训练数据集D中,有一部分x(i)被标注了y(i)。好比狱卒在训练普京的时候,在50只小鸡中随机选了10只,并标注了它们的性别,然后就不管了,让普京自己学习。普京不仅能够根据小鸡外形特征分类,而且还能根据标记来推测不同分类对应的性别。
4,
增强学习(reinforcement learning):通过隐含信息学习,通常无法直接表示什么是正确的,但是可以通过”惩罚“不好的结果,”奖励“好的结果来优化学习效果。
应用:广告系统,扑克、棋类游戏。
很像训练小狗。人类的一个口令(输入),对应小狗的一个动作(输出)。主人喊”蹲下!“时,无法直接告诉它什么动作是对的,但如果小狗撒了泡尿,主人会劈头盖脸打一顿。直到有一次,小狗动作对了,主人终于不打它了,递了一块排骨上去,小狗明白了听到这个口令只要蹲下就不会挨打还有肉吃。
强化学习通常都是顺序进行的。比如用户对垃圾邮件的标注都是一封一封的。
三, 根据不同的协议来分类:学习算法不同
1, 批量学习 - Batch learning:
利用所有已知训练数据来学习,
就是利用大量标记数据(即有监督),解决分类问题。
2,
在线学习 - online learning;【顺序学习】(Sequence Learning)
通过序列化地接收数据来学习,逐渐提高性能。
应用:垃圾邮件, 增强学习。
数据并不是一麻袋扔给机器,而是一个一个顺序出现。以垃圾邮件过滤器为例:
1. 观察一封邮件x(i);
2. 使用当前的目标函数g(i)预测x(i)是否为垃圾邮件;
3. 收到用户反馈y(i),利用(x(i), y(i))更新g(i)。
3, 主动学习 - active learning
learning by asking:开始只有少量label, 通过有策略地”问问题“ 来提高性能。
比如遇到xi, 不确定输出是否正确,则主动去确认yi 是什么,依次来提高性能。
四, 通过输入空间来分类:输入几何{x}不同
1,
具体特征 - concrete features
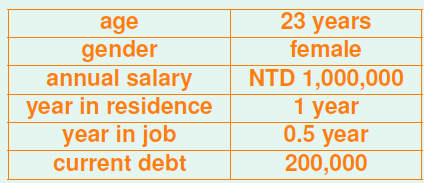
特征中通常包含了人类的智慧。例如对硬币分类需要的特征是(大小,重量);对信用分级需要的特征是客户的基本信息。这些特征中已经蕴含了人的思考,是具有实质意义的数据。例如银行客户的数据:年龄、性别、年收入等都是具有社会意义、人类能够识别的数据。
2,
原始特征 - raw features
这些特征对于学习算法来说更加困难,通常需要人或机器(深度学习,deep learning)将这些特征转化为离散(concrete)特征。
例如数字识别,输入数据是16*16像素的黑白数字图片,输出是识别图片中数字的值。对于机器,它只知道像素矩阵中每个像素点的灰度值,这是图像所包含的的最原始的信息。此时,通常需要机器或人类将其转化为具有实质意义的信息。

3,
抽象特征 - abstract features
抽象特征通常没有任何真实意义,更需要认为地进行特征转化、抽取和再组织。
例如,预测某用户对电影的评分,原始数据是(userid, itemid, rating), rating 是训练数据的标签,相当于y。这里的(userid, itemid)本身对学习任务是没有任何帮助的,我们必须对数据所进一步处理、提炼、再组织。打个比方,我喊一声你好朋友的名字,你在脑海里立刻就能想起他的样子、爱穿什么衣服、爱吃什么菜等信息,就是说输入了一个抽象的名字”李二小“,输出却是关于”李二小“的大量信息。实现的前提是你的数据库里(大脑)已经存储了关于”李二小“的足够数据。
总结:具体特征具有丰富的自然含义;原始特征有简单的自然含义;抽象特征没有自然含义。
原始特征、抽象特征都需要再处理,此过程成为特征工程(feature engineering),是机器学习、数据挖掘中及其重要的一步。具体特征一般只需要简单选取就够了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









