




 本文介绍了SQL中的关键功能,包括类型转换函数CAST,常用统计函数如SUM和AVG,取样方法,NULL值处理用COALESCE,以及探索复杂数据结构的EXPLODE和日期转换函数。
本文介绍了SQL中的关键功能,包括类型转换函数CAST,常用统计函数如SUM和AVG,取样方法,NULL值处理用COALESCE,以及探索复杂数据结构的EXPLODE和日期转换函数。
1.类型转换函数
使用CAST函数转换数据类型(可以起别名)
SELECT
rating,
CAST(timeRecorded as timestamp)
FROM
movieRatings;支持的数据类型有:
BIGINT、BINARY、BOOLEAN、DATE 、DECIMAL(p,s)、 DOUBLE、 FLOAT、 INT、 INTERVAL intervalQualifier、 VOID、 SMALLINT、 STRING、 TIMESTAMP、 TIMESTAMP_NTZ、 ARRAY、 MAP < keyType,valueType >、 STRUCT < [fieldName : fieldType [NOT NULL][COMMENT str][, …]] >
2.常见统计函数
SUM、AVG、SPLIT
SELECT sum(quantity) as totalQuantity,countryName
FROM sales3.取样函数
3.1 随机排序并取前N条
SELECT * FROM DCDataRaw
ORDER BY RAND()
LIMIT 3;3.2 从所有数据中取样N条
SELECT * FROM outdoorProductsRaw TABLESAMPLE (5 ROWS)3.3 按比率抽样数据
SELECT * FROM outdoorProductsRaw TABLESAMPLE (2 PERCENT) ORDER BY InvoiceDate 4.Null值填充 COALESCE
-- Description字段为null的填充为“Misc”
SELECT
COALESCE(Description, "Misc") AS Description,
SPLIT(InvoiceDate, "/")[0] month,
SPLIT(InvoiceDate, "/")[1] day
FROM
outdoorProductsRaw5. explore函数单行拆多行
复杂的数据类型可以通过explore来拆分多行。访问深层的数据可以直接点 “.” 或[key]来查询。
-- source是key value键值对map数据
select source from DCDataRaw;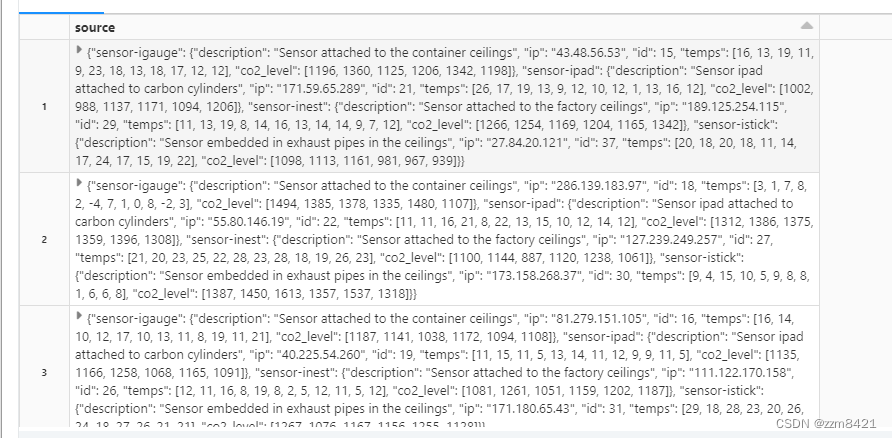
-- EXPLODE 与数组和映射表达式的元素一起使用。
当与数组一起使用时,它将元素分成多行。
与映射一起使用(如本例所示),它将映射的元素拆分为多行和多列,
并使用默认名称、键和值来命名新列。
该数据结构被映射为每个键(某个设备的名称)保存一个对象(值),其中包含有关该设备的信息。
SELECT EXPLODE (source)
FROM DCDataRaw; 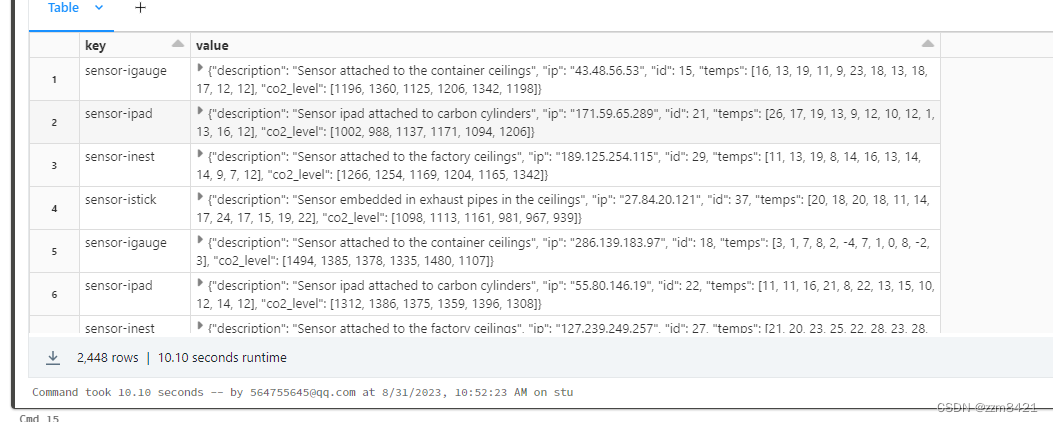
通过点“.”来查询深层数据
SELECT
key,
value.description,
value.ip,
value.temps,
value.co2_level
FROM
ExplodeSource; 通过[key]查询
SELECT
dc_id,
to_date(date) AS date,
source['sensor-igauge']
FROM
DCDataRaw6.日期转换, 字符串转日期类型:to_date,日期转字符串类型date_format
-- 字符串转日期格式
SELECT
to_date(sDate, "MM/dd/yy") date
FROM
standardDate
-- 日期转字符串格式
SELECT
date_format(date, "E") day
FROM
salesDateFormatted6.1 查询周几 dayofweek
select dayofweek(eventDate) as dayWeek from purchaseEvents
















 1675
1675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









