



 本文详细介绍了Java中String类对正则表达式的支持,包括正则表达式的常用标记、String类的方法如matches()、replaceAll()、split()等在数据验证、替换和拆分中的应用。此外,还讲解了java.util.regex包中的Pattern和Matcher类的使用,演示了如何进行字符串的拆分、验证和替换操作。
本文详细介绍了Java中String类对正则表达式的支持,包括正则表达式的常用标记、String类的方法如matches()、replaceAll()、split()等在数据验证、替换和拆分中的应用。此外,还讲解了java.util.regex包中的Pattern和Matcher类的使用,演示了如何进行字符串的拆分、验证和替换操作。
在项目开发中String是一个重要的程序类,String类除了可以实现数据的接受、各类数据类型的转型外,其本身也支持正则表达式(Regular Expression),利用正则表达式可以方便的实现数据的拆分、替换、验证等操作。
范例:使用正则表达式
public class Main {
public static void main(String[] args){
String str="123"; //字符串对象
if (str.matches("\\d+")){ //结构匹配
int num=Integer.parseInt(str); //字符串转为int型数据
System.out.println(num*2); //数字计算
}
}
}
程序执行结果:
246
13.1 常用正则标记
在正则表达式的处理中,最为重要的是正则匹配标记的使用,所有的正则标记都在java.util.regex.Pattern类中定义,下面列举一些。
1.字符:匹配单个字符
- a:表示匹配字母a。
- \\:匹配转义字符"\"。
- \t:匹配转义字符"\t"。
- \n:匹配转义字符"\n"。
2.一组字符:任意匹配里面的一个单个字符。
- [abc]:表示可能是字母a,可能是字母b或者是字母c。
- [^abc]:表示不是字母a,b,c中的任意一个。
- [a-zA-Z]:表示全部字母中的任意一个。
- [0-9]:表示全部数字中的任意一个。
3.边界匹配:在以后编写JavaScript的时候使用正则时要使用到。
- ^:表示一组正则的开始。
- $:表示一组正则的结束。
4.简写表达式:每一位出现的简写标记也只有一位。
- .:表示任意的一个字符。
- \d:表示任意的一位数字,等价于.[0-9]。
- \D:表示任意的一位非数字,等价于.[^0-9]。
- \w:表示任意的一位字母、数字、_,等价于.[a-zA=Z0-9_]。
- \W:表示任意的一位非字母、数字、_,等价于.[^a-zA-Z0-9_]。
- \s:表示任意的一位空格,例如,"\n""\t"等。
- \S:表示任意的一位非空格。
5.数量表示:之前的所有正则都只是表示一位,如果要想表示多位,则就需要数量表示。
- 正则表达式?:此正则出现0次或1次。
- 正则表达式*:此正则出现0次、1次或多次。
- 正则表达式+:此正则出现1次或多次。
- 正则表达式{n}:此正则出现正好n次。
- 正则表达式{n,}:此正则出现n次以上。
- 正则表达式{n,m}:此正则出现n~m次。
6.逻辑表示:与、或、非。
- 正则表达式A正则表达式B:表示表达式A之后紧跟着表达式B。
- 正则表达式A|正则表达式B:表示表达式A或者表达式B,二选一出现。
- (正则表达式):将多个子表达式合成一个表示,作为一组出现。
要求全部背过。
13.2 String类对正则对支持
在JDK1.4后,String类对正则有了直接的方法支持,只需要通过如表方法就可以操作正则。
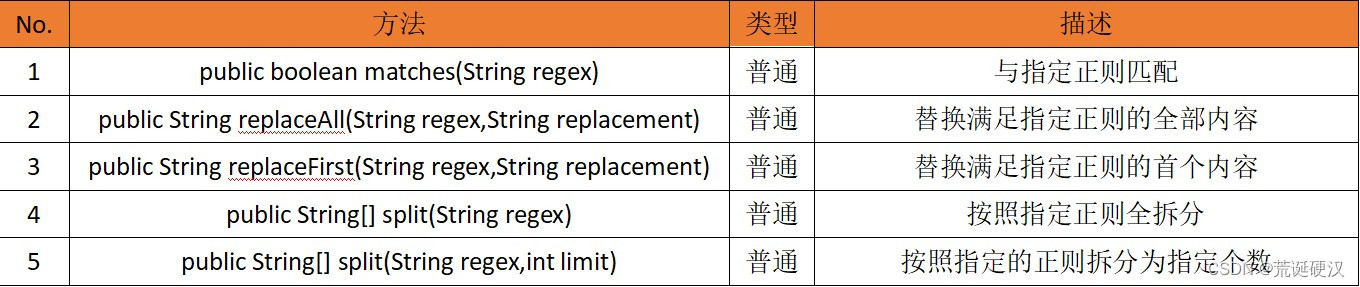
下面进行依次验证:
范例:实现字符串替换(删除非字母和数字)
package cn.kuiba.util;
public class Main {
public static void main(String[] args) throws Exception {
String str="JOE&(*@#*(@##@*()Java"; //要替换的原始数据
//如果现在由非字母和数字所组成“[a-zA-Z0-9]”,数量在1个及多个的时候进行替换
String regex="[^a-zA-Z0-9]+"; //正则表达式
System.out.println(str.replaceAll(regex,""));
}
}
程序执行结果:
JOEJava
本程序由于可能含有多个匹配内容,所以使用了“+”进行数量设置,并且结合replaceAll()方法将匹配成功的内容替换为空格。
范例:实现字符串拆分
package cn.kuiba.util;
public class Main {
public static void main(String[] args) throws Exception {
String str="a1b22c333d4444e55555f666666g"; //要操作的数据
String regex="\\d+"; //正则表达式
String result[]=str.split(regex); //字符串拆分
for (int x=0;x< result.length;x++){
System.out.print(result[x]+"、");
}
}
}
程序执行结果:
a、b、c、d、e、f、g、
范例:判断一个数据是否为小数,如果是小数则将其转为double类型
package cn.kuiba.util;
public class Main {
public static void main(String[] args) throws Exception {
String str="100.1"; //要判断的数据内容
String regex="\\d+(\\.\\d+)?"; //正则表达式
if (str.matches(regex)){ //正则匹配成功
double num=Double.parseDouble(str); //字符串转double
System.out.println(num); //直接输出
}else {
System.out.println("内容不是数字,无法转型。");
}
}
}
程序执行结果:
100.1
本程序在进行小数组成的正则判断时需要考虑到小数点与小数位的情况(两者必须同时出现),所以在定义是使用"(\\.\\d+)?"将两者通过"()"绑定在一起。
范例:判断一个字符串是否由日期组成,如果是由日期组成则将其转为Date类型
package cn.kuiba.util;
import java.text.SimpleDateFormat;
public class Main {
public static void main(String[] args) throws Exception {
String str="1981-20-15"; //要判断的数据
String regex="\\d{4}-\\d{2}-\\d{2}"; //正则表达式
if (str.matches(regex)){ //格式匹配(无法判断数据)
System.out.println(new SimpleDateFormat("yyyy-MM-dd").parse(str));
}else {
System.out.println("内容不是日期格式,无法转型。");
}
}
}
程序执行结果:
Sun Aug 15 00:00:00 CST 1982
范例:判断电话号码格式是否正确,在程序中电话号码的内容有以下3种类型
- 电话号码类型1(7~8位数字):51283346(判断正则:“\\d{7,8}”)。
- 电话号码类型2(在电话号码前追加区号):01051283346(判断正则:“(\\d{3,4})?\\d{7,8}”)。
- 电话号码类型3(区号单独包裹):(010)-51283346(判断正则:“(((\\d{3,4})|(\\(\\d{3,4}\\)-))?\\d{7,8}”)。
package cn.kuiba.util;
public class Main {
public static void main(String[] args) throws Exception {
String str="(010)-51283346"; //要判断的数据
String regex="((\\d{3,4})|(\\(\\d{3,4}\\)-))?\\d{7,8}"; //正则表达式
System.out.println(str.matches(regex)); //正则匹配
}
}
程序执行结果:
true
范例:验证E-mail格式,现在要求一个合格的Email地址的组成规则如下
- E-mail的用户名可以由字母、数字、_所组成(不应该使用“_”开头)。
- E-mail的域名可以由字母、数字、_、-所组成。
- 域名的后缀必须是.cn、.com、.net、.com.cn、.gov。
package cn.kuiba.util; public class Main { public static void main(String[] args) throws Exception { String str="kuibajava888@kuiba.cn"; //要判断的数据 String regex="[a-zA-Z0-9]\\w+@\\w+\\.(cn|com|com.cn|net|gov)"; //正则表达式 System.out.println(str.matches(regex)); //正则匹配 } } 程序执行结果: true正则匹配的结构如图:

13.3 java.util.regex包支持
java.util.regex是从JDK1.4开始正式提供的正则表达式开发包,在此包中定义有两个核心的正则操作类:Pattern(正则模式)和Matcher(匹配)。
java.util.regex.Pattern类的主要功能是进行正则表达式的编译以及获取Matcher类实例,常用方法如表。

Pattern类并没有提供构造方法,如果想要取得Pattern类实例,则必须调用compile()方法。对于字符串的格式验证与匹配的操作,则可以通过matcher()方法获取Matcher类实例完成。Matcher类常用方法如表。

范例:使用Pattern类实现字符串拆分
package cn.kuiba.util;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) throws Exception {
String str="joe()yongli$()java&*()#@Python"; //要拆分的字符串
String regex="[^a-zA-Z]+"; //正则匹配标记
Pattern pat=Pattern.compile(regex); //编译正则表达式
String result[]=pat.split(str); //字符串拆分
for (int x=0;x<result.length;x++){ //循环输出拆分结果
System.out.print(result[x]+"、");
}
}
}
程序执行结果:
joe、yongli、java、Python、
范例:使用Matcher类实现正则验证
package cn.kuiba.util;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) throws Exception {
String str="101"; //要匹配的字符串
String regex="\\d+"; //正则匹配标记
Pattern pat=Pattern.compile(regex); //编译正则表达式
Matcher mat=pat.matcher(str); //获取Matcher类实例
System.out.println(mat.matches()); //正则匹配
}
}
程序执行结果:
true
范例:使用Matcher类实现字符串替换
package cn.kuiba.util;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) throws Exception {
String str="JOE&(*@#*(@##@*()Java"; //要替换的原始数据
String regex="[^a-zA-Z0-9]+"; //正则表达式
Pattern pat=Pattern.compile(regex); //编译正则表达式
Matcher mat=pat.matcher(str); //获取Matcher类实例
System.out.println(mat.replaceAll("")); //字符串替换
}
}
程序执行结果:
JOEJava
范例:使用Matcher类实现数据分组操作
package cn.kuiba.util;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) throws Exception {
//定义一个语法,其中需要获取“#{}”标记中的内容,此时就必须进行分组匹配操作
String str="INSERT INTO dept(deptno,dname,loc) VALUES (#{deptno},#{dname},#{loc})"; //要替换的原始数据
String regex="#\\{\\w+\\}"; //正则表达式
Pattern pat=Pattern.compile(regex); //编译正则表达式
Matcher mat=pat.matcher(str); //获取Matcher类实例
while (mat.find()){ //是否有匹配成功的内容
//获取每一个匹配的内容,并且将每一个内容中的“#{}”标记替换掉
String data=mat.group(0).replaceAll("#|\\{|\\}","");
System.out.print(data+"、");
}
}
}
程序执行结果:
deptno、dname、loc、


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









