




 本文深入讲解了KNN算法的工作原理,介绍了如何使用KNN进行分类和回归,特别聚焦于分类应用。文章解释了KNN算法如何通过计算距离来确定样本类别,并提供了Python实现的示例代码。
本文深入讲解了KNN算法的工作原理,介绍了如何使用KNN进行分类和回归,特别聚焦于分类应用。文章解释了KNN算法如何通过计算距离来确定样本类别,并提供了Python实现的示例代码。
KNN算法是一个有监督的算法,也就是样本是有标签的。KNN可以用于分类,也可以用于回归。这里主要讲knn在分类上的原理。KNN的原理很简单:
放入一个待分类的样本,用户指定k的大小,然后计算所有训练样本与该样本的距离,选择距离该样本最近的k个训练样本。这k个样本少数服从多数的结果就是该样本的类别。
计算样本之间的距离一般选择欧式距离,k值的选取可以使用交叉验证。KNN有趣的地方在于它并没有显式的训练,不像其他有监督的算法会用训练集train一个模型(也就是拟合一个函数),然后验证集或测试集用该模型来进行分类和预测。而KNN在训练阶段仅仅是把样本保存起来,等收到测试数据时再进行处理,也就是直接把待分类的样本放入到训练样本中。所以,KNN训练的时间开销为零。
下面为用python实现KNN的代码:
import numpy as np
import operator
import matplotlib.pyplot as plt
##给出训练数据以及对应的类别
def create_dataset():
group = np.array([[1.0, 2.0], [1.2, 0.1],
[0.1, 1.4], [0.3, 3.5]])
labels = ['A','A','B','B']
return group, labels
##通过KNN进行分类
def classify(input, dataSet, label, k):
dataSize = dataSet.shape[0]
## 重复input为dataSet的大小
diff = np.tile(input, (dataSize, 1)) - dataSet
sqdiff = diff**2
## 列向量分别相加,得到一列新的向量
squareDist = np.array([sum(x) for x in sqdiff])
dist = squareDist**0.5
## 对距离进行排序
## argsort()根据元素的值从小到大对元素进行排序,返回下标
sortedDistIndex = np.argsort(dist)
classCount = {}
for i in range(k):
## 因为已经对距离进行排序,所以直接循环sortedDistIndx
voteLabel = label[sortedDistIndex[i]]
## 对选取的k个样本所属的类别个数进行统计
## 如果获取的标签不在classCount中,返回0
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
## 选取出现的类别次数最多的类别
maxCount = 0
for key, value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes
def draw_pic(input):
plt.scatter([1.0,1.2],[2.0,0.1],label='A')
plt.scatter([0.1,0.3],[1.4,3.5],label='B')
plt.scatter(input[0],input[1],label='test')
plt.legend()
plt.show()
data, labels = create_dataset()
input = [0.5, 3.0]
draw_pic(input)
print(classify(input,data,labels,2))
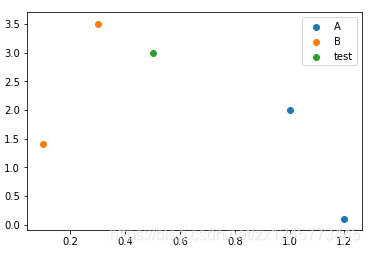
查看运行结果为 B,我们从下图也可以看到预测数据和类别B的距离更近:

















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









