




PyTorch-Kaldi 深度学习语音识别开源软件
论文:Ravanelli M (Mirco Ravanelli), Parcollet T, Bengio Y. The Pytorch-kaldi Speech Recognition Toolkit. ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019: 6465–6469.
GitHub:https://github.com/mravanelli/pytorch-kaldi
SpeechBrain 是 PyTorch-Kaldi 的进阶版,使用 All-in-One PyTorch 的模式。
语音识别与说话人识别的区别:相比较说话人识别,语音识别的流程更加复杂,额外需要内容相关的标签和解码方法。
文章目录
摘要
Kaldi 是 C++ 实现的语音识别软件,缺少像 Python 的简单与灵活。PyTorch-Kaldi 旨在构建 Kaldi 与 PyTorch 之间的联系,充分利用 Kaldi 高效性与 PyTorch 灵活性。PyTorch-Kaldi 除了建立 Kaldi 与 PyTorch 之间的联系,还嵌入了非常有用的功能,用于开发最新的语音识别器。程序易于加入自定义的声学模型,包含初始化方法和预执行的模型。PyTorch-Kaldi 支持多个特征和标签流、神经网络组合的建模。程序已公开发布在 Github,适用于运行在本地和高性能计算集群上。
引言
近十年,自动语音识别(Automatic Speech Recognition, ASR)迎来了飞速的发展。深度学习技术开始克服传统高斯混合模型(Gaussian Mixture Models, GMMs)的不足,在众多数据集上表现出优异的性能,例如 TIMIT、AMI、DIRHA、CHiME、Babel 和 Aspire。
语音识别开源软件的发展,诸如 HTK、Julius、CMU-Sphinx、RWTH-ASR、LIA-ASR 和 2011 年以后的 Kaldi,极大地推进了 ASR 的发展,为研究的进行和应用的开发提供了便利。
Kaldi 是目前非常流行的 ASR 工具,它提供一系列 C++ 库。
深度学习框架,例如 Theano、TensorFlow、CNTK 和 PyTorch,为 ASR 机器学习系统的发展提供了帮助。这些软件提供了灵活的神经网络设计模式和大量的深度学习应用。
PyTorch 是 Python 语音的 GPU 加速软件,自动梯度工具使其是用于高效地深度学习应用开发。
PyTorch-Kaldi 建立了 Kaldi 与 PyTorch 之间的桥梁。该软件使用 PyTorch 执行声学建模,使用 Kaldi 执行特征提取、标签/对齐、编码等,是用于 DNN-HMM 框架的 ASR 系统。
PyTorch-Kaldi 能够部署在本地机器和高性能计算机上,支持多 GPU 训练、恢复策略、自动数据分块。
PyTorch-Kaldi 项目
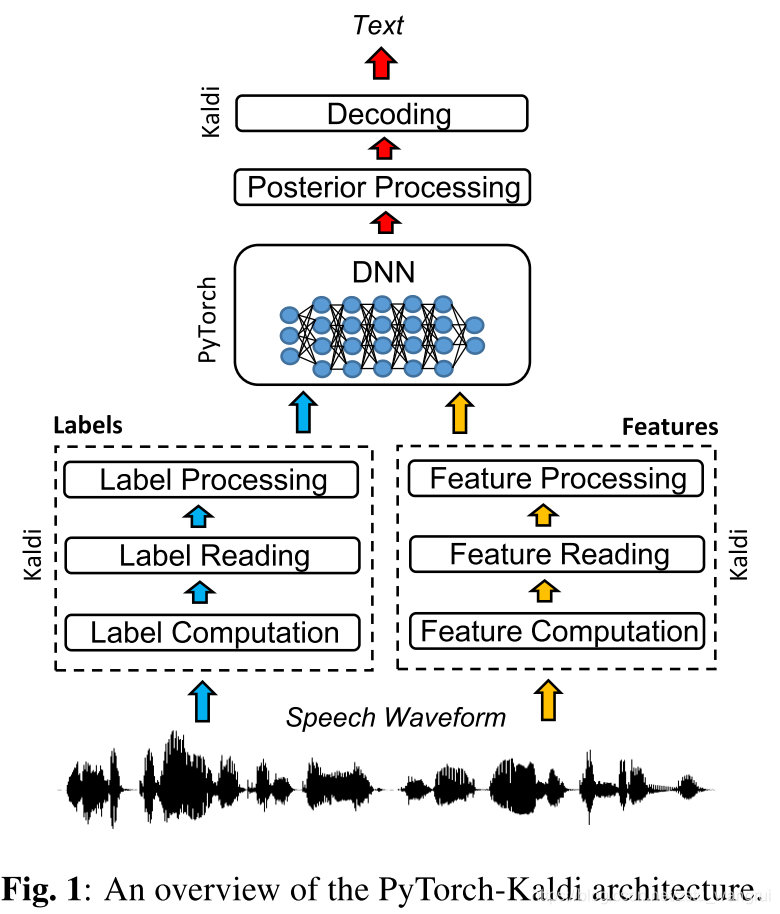
PyTorch-Kaldi 是 Python 语言开发的基于 Kaldi 和 PyTorch 的 ASR 工具。类似地,PyKaldi 是 Kaldi 的 Python 包装,未提供神经网络建模方法;ESPnet 仅支持 ASR 端到端建模,训练的设计需要非常细心。
Fig. 1 描述了 PyTorch-Kaldi 的框架,Kaldi 执行特征提取与语音解码,PyTorch 执行神经网络建模与后处理。主要脚本 run_exp.py 管理 ASR 系统所有的组成成分,包括:特征与标签提取、训练、验证、解码和评分。
配置文件
配置文件采用 INI 格式,用于 run_exp.py:
-
[Exp]:高层次信息,例如文件夹、训练的次数、随机种子、执行 CPU/GPU/多 GPUs 等;
-
[dataset*]:特征与标签的信息(存储的路径、上下文窗口的特效、语音数据划分的 chunks 数量)等;
-
[architecture*]:神经网络模型的描述;
-
[model]:神经网络如何结合;
-
[decoding]:定义解码参数;
-
其他。
该项目采用 *.cfg 文件定义配置文件,例如
# Source: https://github.com/mravanelli/pytorch-kaldi/blob/e06682f9b23ca453b2c3fc35bc474e0617a6cc80/cfg/TIMIT_baselines/TIMIT_MLP_mfcc_basic.cfg
[cfg_proto]
cfg_proto = proto/global.proto
cfg_proto_chunk = proto/global_chunk.proto
[exp]
seed = 1234
use_cuda = True
multi_gpu = False
[dataset1]
data_name = TIMIT_tr
n_chunks = 5
[dataset2]
data_name = TIMIT_dev
n_chunks = 1
[dataset3]
data_name = TIMIT_test
n_chunks = 1
[data_use]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 260
260




 到【灌水乐园】发言
到【灌水乐园】发言







