




端到端的文本无关说话人确认的深度神经网络嵌入
论文:Snyder D, Ghahremani P, Povey D, et al. Deep neural network-based speaker embeddings for end-to-end speaker verification. 2016 IEEE Workshop on Spoken Language Technology, SLT 2016 - Proceedings[C]. 2017: 165–170.
摘要
在文本无关的说话人确认中,D. Snyder 研究了一种深度神经网络(Deep Neural Network, DNN)的端到端系统。该系统由一个 DNN 组成,该模型将长度可变的语音投影为说话人嵌入,进而进行相似度计算。端到端系统的最大特点是相似度计算公式整合在优化目标中。结果表明:1)大量的说话人的训练数据集显著提升文本无关的说话人确认系统;2)DNN 嵌入对时长鲁棒,适用于短时语音段的说话人特征提取;3)DNN 嵌入与 i-vector 在得分上是互补的。
方法
论文介绍了两种文本无关的说话人确认方法,其中 i-vector 系统作为基准系统,端到端系统是提出的方法:
-
i-vector 系统:
- 模型:输入(60-d) ↦ \mapsto ↦ UBM(4096-c) ↦ \mapsto ↦ i-vector 提取器(600-d) ↦ \mapsto ↦ PLDA
- 输入:共 60 维,20 MFCC + Delta + Acceleration,25 ms 帧长,平均归一化,3s滑窗,基于GMM的VAD
- UBM:4096个全方差 GMM 成分
- i-vector:600 维,中心化,长度归一化
- PLDA:剪切的训练数据,开始的1-20s,短时语音训练(1-20s)或者混合时长(增加 full)的训练
-
-
模型:输入(180-d) ↦ \mapsto ↦ 端到端 DNN
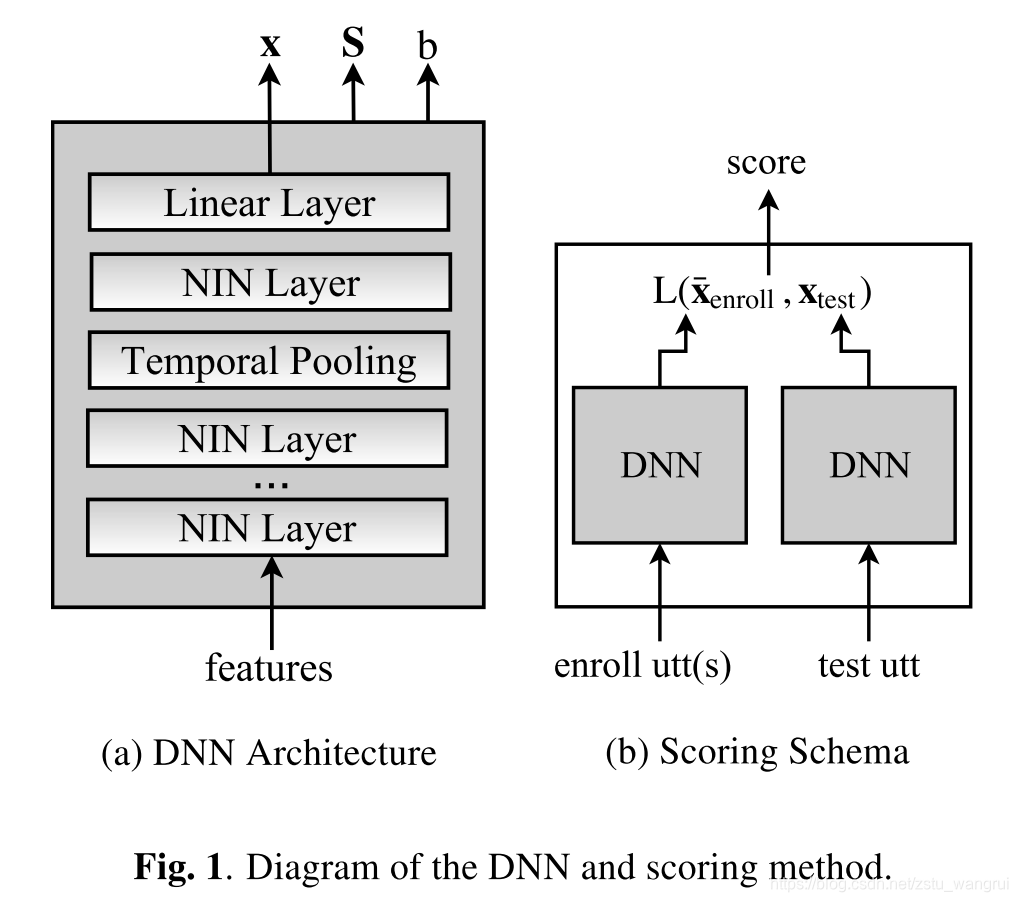
-
输入:共 180 维,20 MFCC,25 ms 帧长,滑窗 3s 平均归一化,9 帧被拼接在一起,拼接后,执行与 i-vector 系统相同的 VAD
-
端到端 DNN:
-
结构:4 隐藏层 + 时间池化层 + 线性层,输出嵌入 x;激活函数采用 network-in-network (NIN),共6,700,000 变量
-
独立变量:对称矩阵 S、补偿 b,与输入无关
-
优化目标:
E = − ∑ x,y ∈ P same ln ( P r ( x,y ) ) − K ∑ x,y ∈ P diff ln ( 1 − P r ( x,y ) ) E=-\sum_{\textbf{x,y}\in P_{\text{same}}}\ln(Pr(\textbf{x,y}))-K\sum_{\textbf{x,y}\in P_{\text{diff}}}\ln(1-Pr(\textbf{x,y})) E=−x,y∈Psame
-
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









