






 本文深入解读 Apache Flink 1.9 的关键特性,包括 Table API 的增强、与 Hive 的集成、Kubernetes 部署、机器学习算法库以及在快手的实际应用案例。
本文深入解读 Apache Flink 1.9 的关键特性,包括 Table API 的增强、与 Hive 的集成、Kubernetes 部署、机器学习算法库以及在快手的实际应用案例。
6月29日,浦项中心B座
本来是想当天就把这个写了的,但是因为各种原因拖到了今天,已经拖了3天了,拖延症真是个好东西
拢共6个Topic:
《Apache Flink 1.9 特性解读》
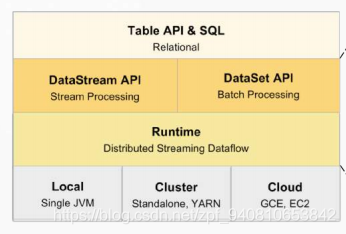
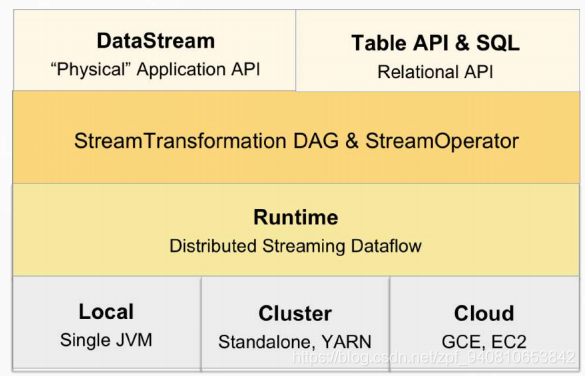
由这两张图可以看到出来,从架构上,DataSet API没了(注意:只是架构上没有了,用还是能用的),DataStream API和Table API & SQL并列在了一层,Runtime上加了Stream Transformation DAG & StreamOperator,
1、既然Table API要替换DataSet API,那么肯定要做大的改动,会有哪些改动大会上也说了:
- Table模块进行拆分
- Table支持多个Runner,用户可自行选择使用哪个Runner
- Flink runner保持原来的行为,继续翻译到DataStream和DataSet
- Blink runner对接新的runtime架构,流批作业使用统一的DAG和StreamOperator来描述
- 未来只保留Blink runner
2、Table API & SQL 新特性预览
- SQL语义保证和标准SQL标准语义一致,例如保障Decimal的精确信息
- 只包含纯粹的逻辑类型信息,可支持多种物理存储类型,我的理解就是数据类型的自动装箱、拆箱
- 类型支持

- 从SQL文本自动区分流批计算
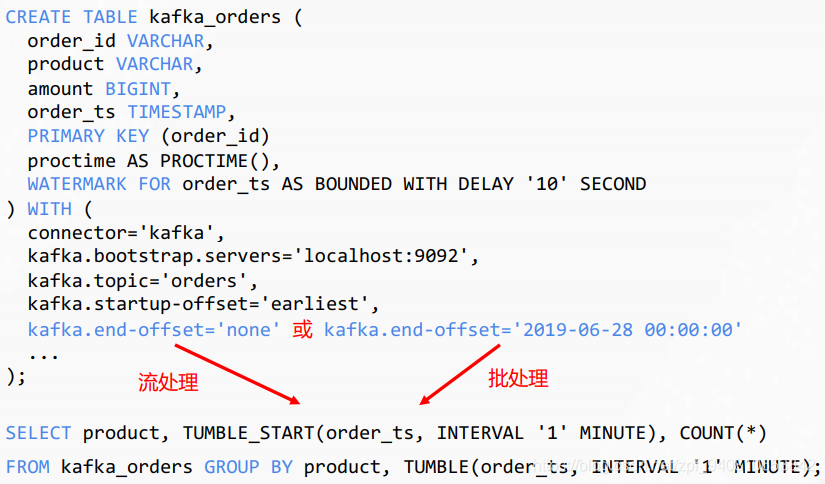
- Table API增加了操作列的API,丰富了处理方法
- 统一的Catalog API:完整支持DDL的基础;可以使用不同的介质存储meta信息;便于和现有系统集成;使Flink不仅具备异步数据源的联合计算能力,甚至提供跨数仓的联合计算
- 支持和Hive相关的DML
- Blink Runner 数据结构的二进制化,提升流批处理的性能,避免资源的开销
- Blink Runner Minibatch Aggregation 减少state读写,提升吞吐
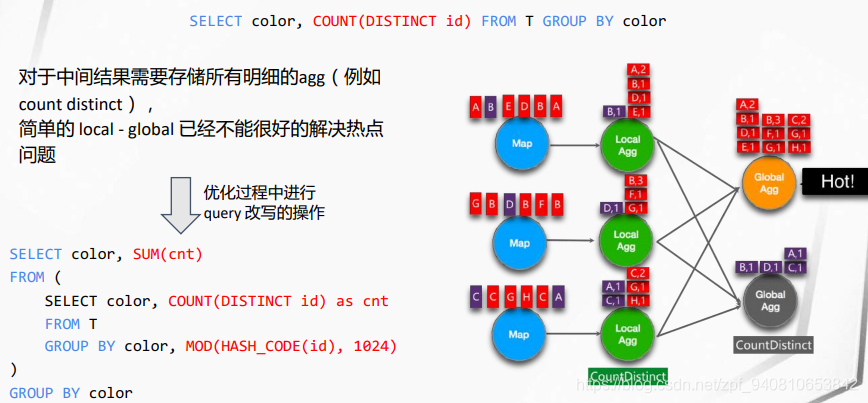
- Blink Runner Global Agg热点问题,增加一个本地 Global Agg,复杂的Agg热点,使用两层嵌套:
- Blink Runner 维表Join
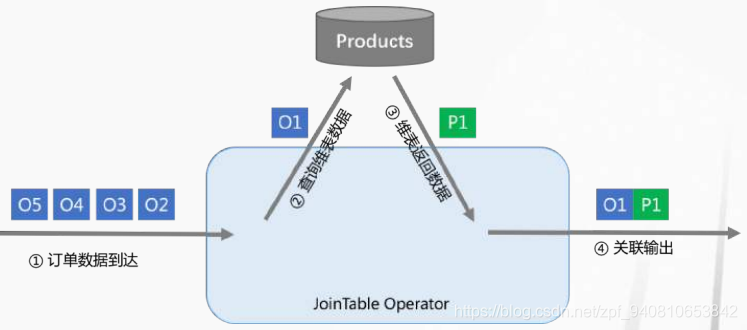
- Blink Runner TopN计算:在流计算中,会识别这样的query pattern并优化成一个单独的算子;针对不同的细分场景,有多种不同的实现,优化器自动进行选择

- Blink Runner 高效流式去重:借鉴上面TopN计算,对内查询的数据进行升序和降序的Order By,实现去重

- Flink从1.9开始成为传统批处理引擎的有力竞争者!
- Flink批处理基本功能完善
- 支持多种Join方式 (inner、left、right、full outer、semi、anti)
- 完整支持几乎所有over window
- 支持子查询(correlated / uncorrelated)
- 支持高级分析函数(grouping set,cube,rollup)
- Runtime进行了大量稳定性优化
- Shuffle service 插件化
3、Runtime(这部分应该是Flink内置的优化,对使用者来说无感知,(个人理解,而且也没太听懂))
- 降低错误恢复花费的时间和I/O资源


- Shuffle Manager 插件化

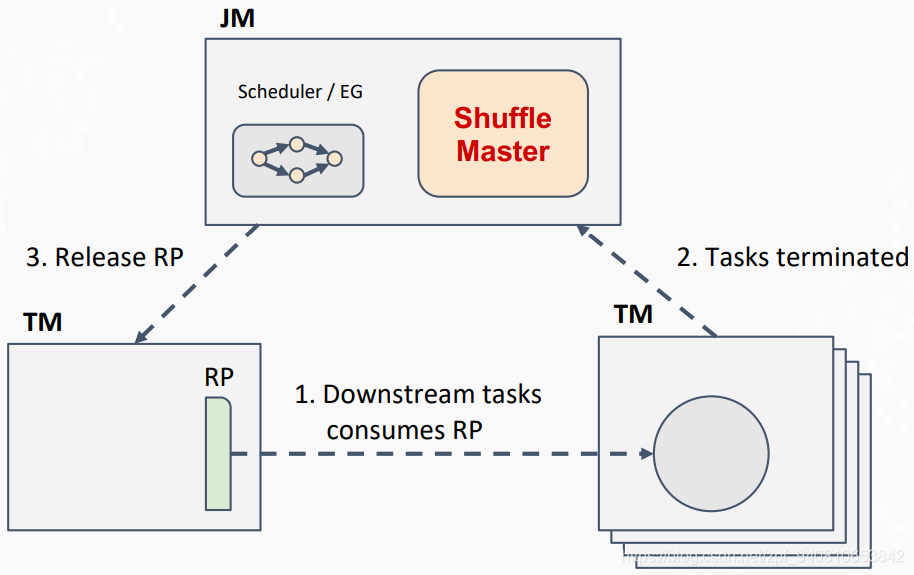
- State Progressing API:从开发者来看,减少核心代码中用于应付状态多版本间格式相容的读写逻辑
- Python Table API 架构设计,是在Java Table API上直接套的Python API吧
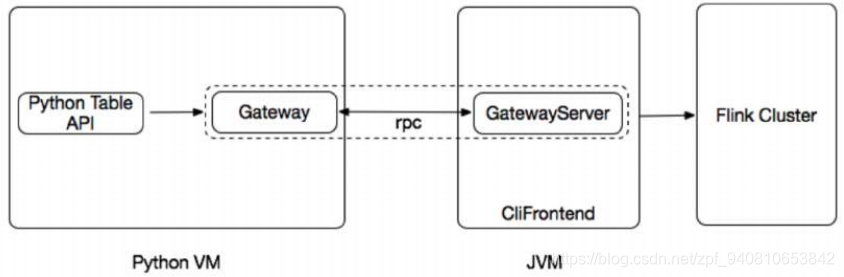
- 计划

《打造基于 Apache Flink Table API 的机器学习生态》
内容简介:Flink 社区在最近的一段时间里对 Table API 进行了一系列功能强化来使其更好的为各种数据计算需求服务。机器学习作为一种重要的计算场景也是Table API发展规划中的关键的组成部分。本次分享将介绍Flink 社区基于 Flink Table API来打造机器学习生态方面的各项工作规划和进展。
不得不吐槽一下这位老师的PPT配色让人看的眼花,而且还是全英文(疯了),我就直接附上课件的地址吧,机器学习我也不会
PPT地址:https://files.alicdn.com/tpsservice/0dea2e3b7c5f95964397874ad4fa3286.pdf
《基于 Flink on Kubernetes 的大数据平台》
- Kubernetes的心路历程和架构
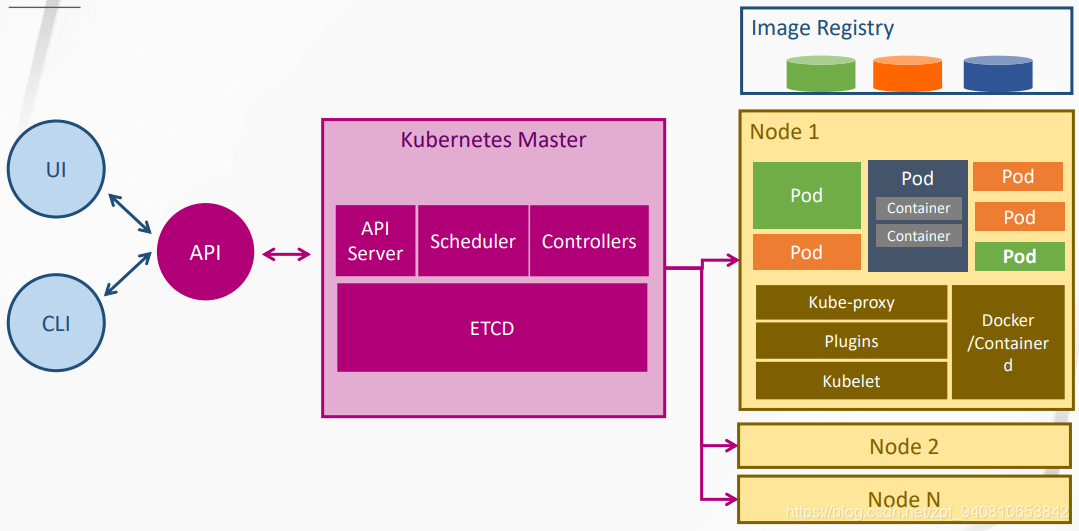
- 阿里云的公有云和私有云在Kubernetes上的应用ACK-Alibaba cloud Container service On Kubernetes,自家的宣传还是得做好
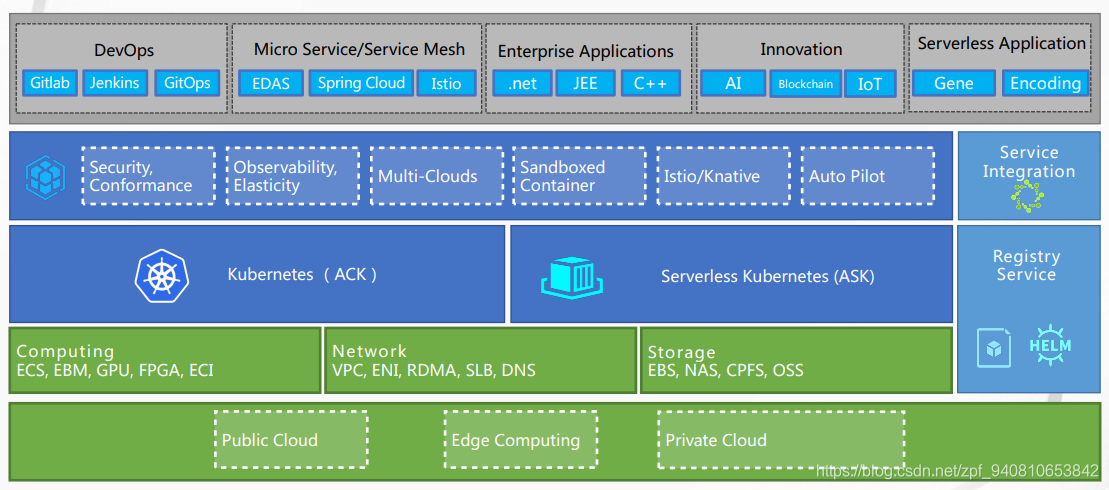
- Flink On K8s - Standalone,单机版,我自己还没搭建过,
https://github.com/docker-flink/examples
- Flink On K8s - Operator,是一个Kubernetes操作符,它管理Kubernetes上的Flink应用程序。操作员充当控制平面来管理应用程序的完整部署生命周期。
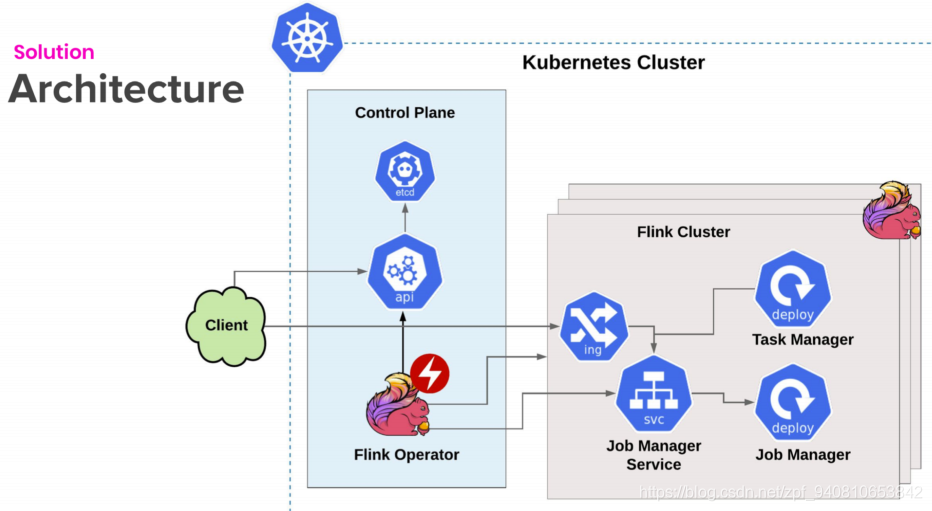
https://github.com/lyft/flinkk8soperator
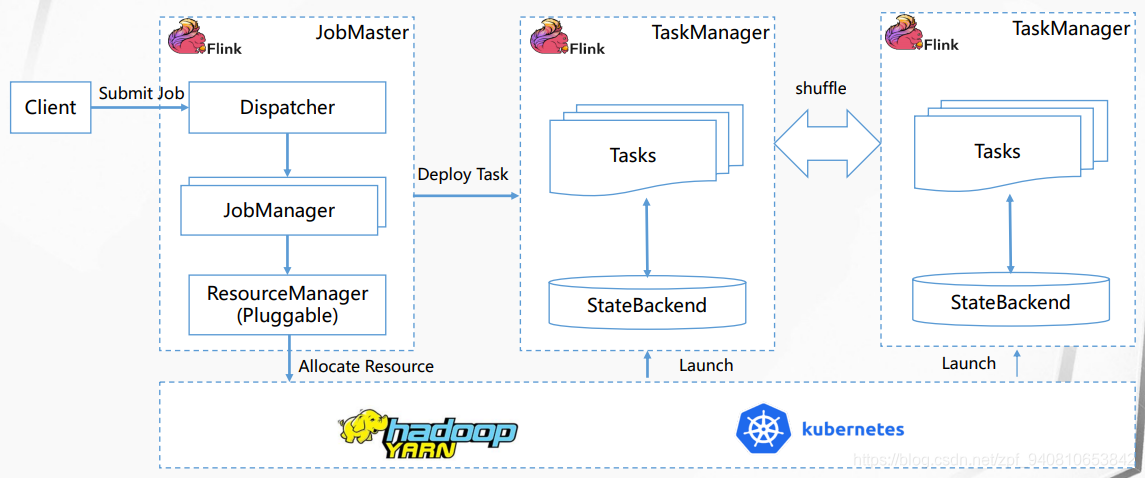
Flink On K8s - Natively,第二张图还在理解消化中......
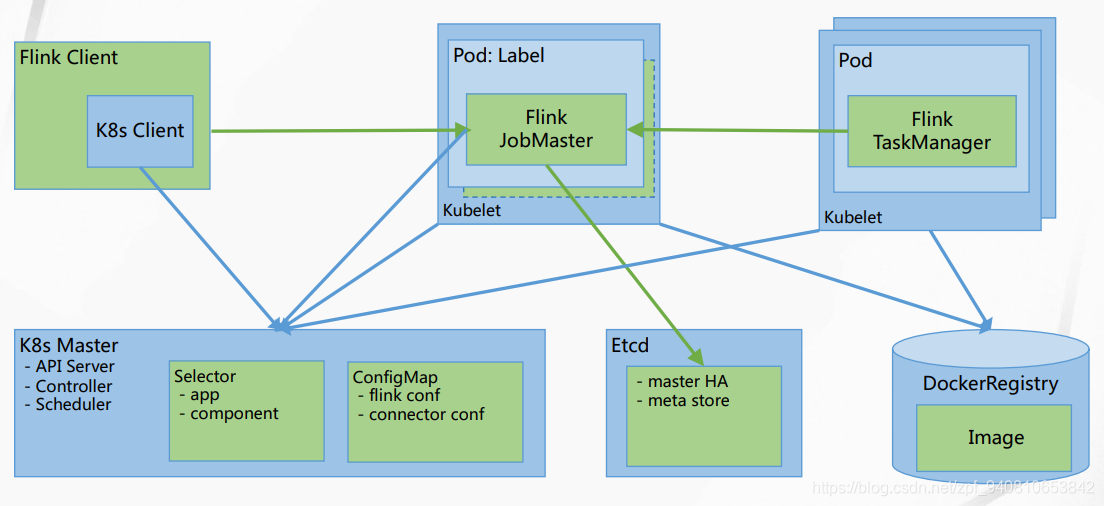
还有一些阿里大数据平台在K8s上的部署架构图了
看文档吧:https://files.alicdn.com/tpsservice/e29cdd9dfc5f2f0330562fa82f3a3e85.pdf
《基于 Apache Flink 的高性能机器学习算法库》
演讲简介:阿里巴巴计算平台事业部正在与Flink社区合作,开源自研的机器学习算法库,基于该算法库,用户可以更方便地构建高性能的Flink机器学习作业。我们希望通过开源来促进Flink社区在机器学习领域的发展。同时也欢迎更多开发者与我们携手共进,建立更强大、更完整的Flink算法库。本次分享主要围绕团队基于Flink研发高性能机器学习算法库过程中的技术积累与收获。
阿里机器学习平台Alink简介
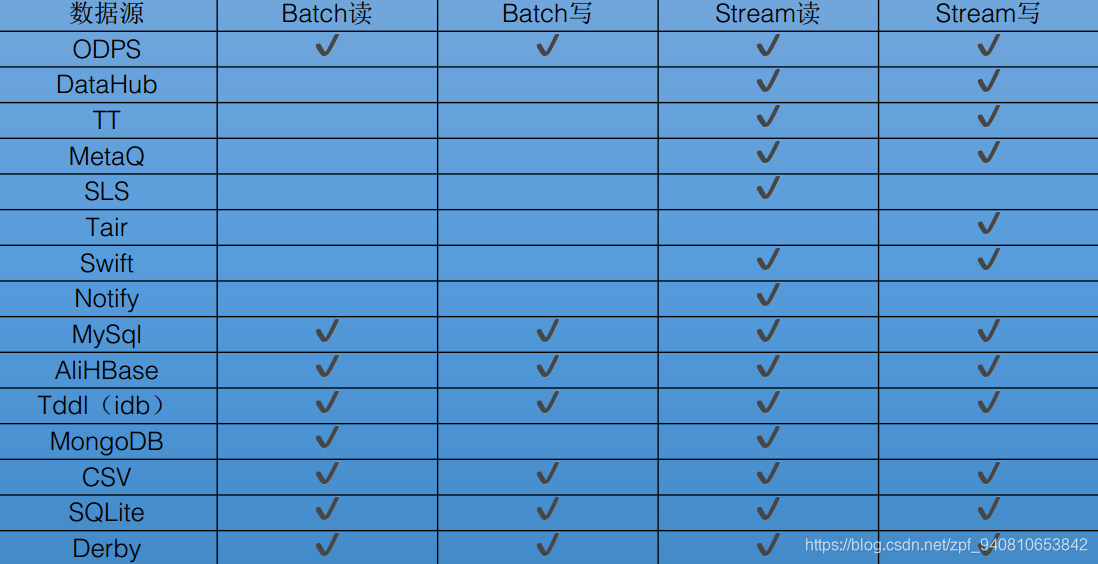
- 支持的数据源
- 回归
- 分类
- 聚类
- 深度学习
- 在线学习
- 评估
- 数据处理
- 特征工程
- 基本统计
- 变量关系
- 数据分布
- 假设检验
- 数据降维
- 时间序列
- 异常检测
- 推荐算法
- 文本
- 图算法
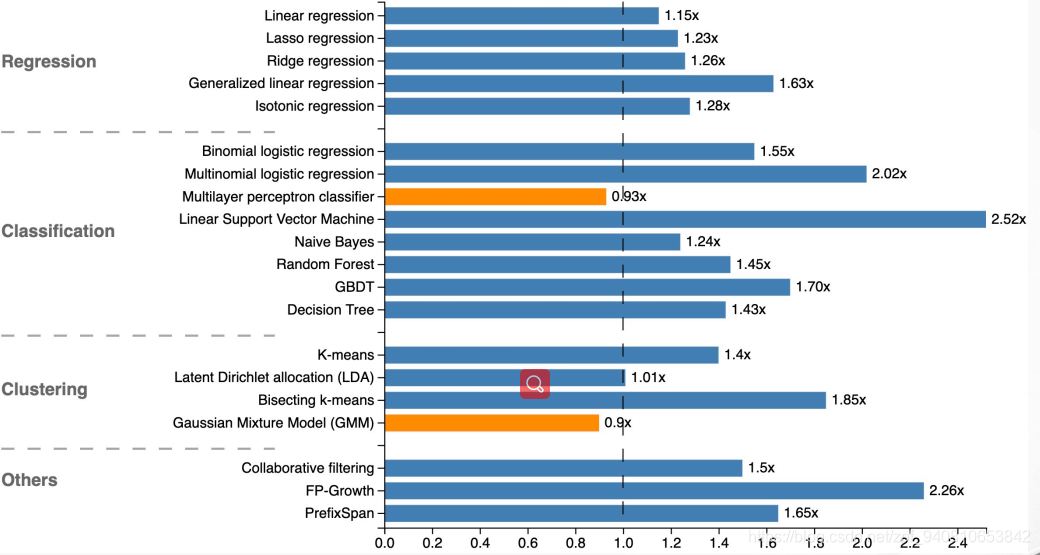
- 与Spark ML的对比图,1.0代表的是Spark ML 的指标,可以看出来,Flink只有两个指标比Spark慢了一点点
- 下面还讲了一部分算法,我也不会,就不班门弄斧了,看文档吧
《Apache Flink 在快手的应用与实践》
演讲简介: Flink系统在快手有着广泛的应用,包括实时监控、实时统计分析、多源数据join等,涉及到公司几乎所有数据相关业务部门。目前Flink集群的整体规模超过千台、日处理条目超过264亿条,处理峰值超过3.6千万条/s。本次分享将会介绍Flink系统在快手的应用实践,以及我们遇到的稳定性、性能等相关问题以及解决思路。例如,如何解决interval join场景下rockdb backend的性能瓶颈、大量读取历史数据时多数据源取数速度差异导致的稳定性问题等等。具体提纲:
1、 Flink在快手应用场景与规模
2、 快手Flink引擎的优化与改进
3、 未来计划
可以听的出来这个小姐姐有点紧张,声音都在发抖,要是我,我也抖,而且比她抖的还厉害,哈哈~~
感觉这一节没有什么重点,也就是Flink在快手的应用场景,集群规模,集群架构,数据Join的场景优化策略,但是视频质量监控调度应用,这个对实时性和稳定性的要求很高,
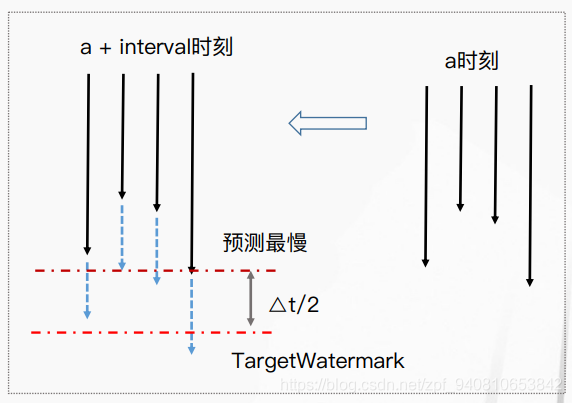
数据源控速的机制,比如有四个速度不一致的数据源,通过协调中心SourceCoodinator,预测最慢的,进而空速
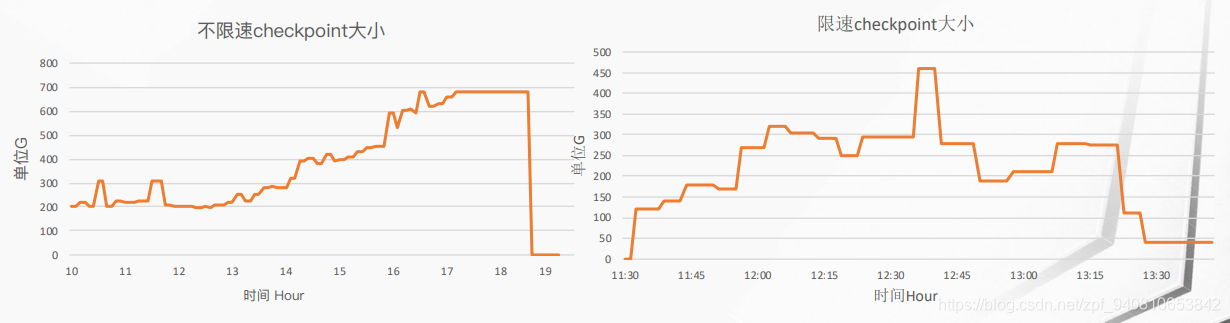
限制前后对比图,限制前:当数据量达到state峰值的时候,这个作业就直接done了,限制后:到达峰值时,会限制最大的那个state,知道后续数据来了之后并处理完成,才会放开,最后任务执行完毕。
感兴趣的也看文档吧:https://files.alicdn.com/tpsservice/afa1bb345e56967fadd83a66b22d9523.pdf
《Apache Flink-1.9 与 Hive 的兼容性》
演讲简介:为了完善Flink SQL的功能,更好地挖掘Flink在批处理方面的潜力,我们提出了Flink与Hive集成的项目,为用户提供通过Flink SQL与Hive进行互操作的功能。本演讲将介绍该项目的设计与架构,在Flink-1.9中与Hive集成的进展,以及我们后续工作的计划等。
项目进展:
1、Catalog API
- GenericlnMemoryCatalog
- HiveCatalog
- 支持的元数据对象,Database、Table、Partition、View、Function
- 除statistics以外的功能已经完成
2、读写Hive数据
- 支持大部分基础数据类型,除interval、timestamp with time zone等
- 支持复杂数据类型(除union),Array、Map、Struct
- 支持多种文本格式,Text、Orc、Parquet、Sequence
- 支持partitioning,Static、Dynamic
3、Hive UDF
- 可直接使用hive内置的、自定义的function
- UDF、GenericUDF、UDTF、UDAF
4、多版本支持
- Hive-1.2.1、Hive-2.3.4
- 需要用户部署hive-exec.jar
- 可通过yaml文件指定hive-site.xml和hive版本
- 基本的DDL,show catalogs、show databases、show tables、desc table
总结:
- Flink从1.9开始成为传统批处理引擎的有利竞争者!
- Flink ML将会超过Spark ML
- 随着Kubernetes的流行,Flink On K8s也将会成为一个趋势,或已然成为了一个大的趋势
- Flink与现有的Hadoop生态和Spark生态的各个组件的兼容性
活动详情:https://www.huodongxing.com/event/9492578872100
视频复播:https://developer.aliyun.com/live/1120
课件地址:
1.《Apache Flink 1.9 特性解读》
https://files.alicdn.com/tpsservice/4b1a9eb9ad437192d312339c9f82c887.pdf
2.《打造基于Flink Table API的机器学习生态》
https://files.alicdn.com/tpsservice/0dea2e3b7c5f95964397874ad4fa3286.pdf
3.《基于Flink on Kubernetes的大数据平台》
https://files.alicdn.com/tpsservice/e29cdd9dfc5f2f0330562fa82f3a3e85.pdf
4.《基于Apache Flink的高性能机器学习算法库》
https://files.alicdn.com/tpsservice/a4ceebbc0e4978d91190cf736413836a.pdf
5.《Apache Flink在快手的应用与实践》
https://files.alicdn.com/tpsservice/afa1bb345e56967fadd83a66b22d9523.pdf
6.《Apache Flink-1.9与Hive的兼容性》
https://files.alicdn.com/tpsservice/0d3f9b5125adf9a80a32e068b94b8a5b.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









