




目录:
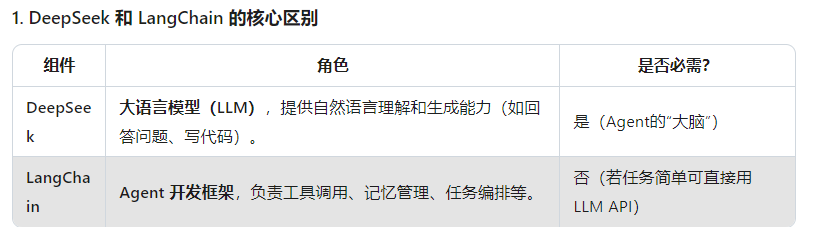
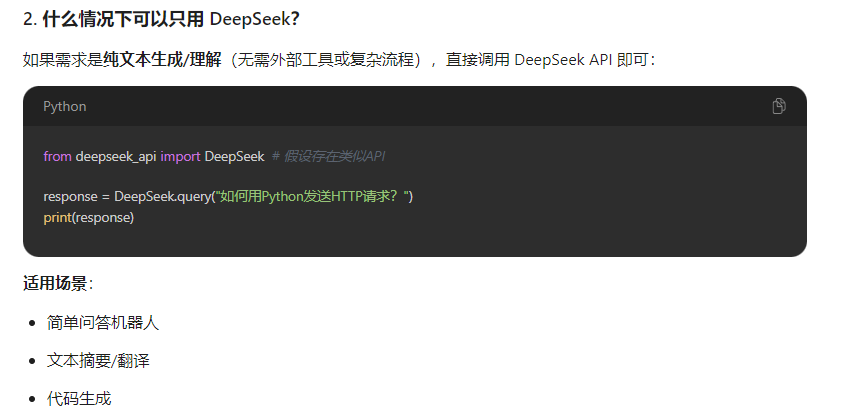
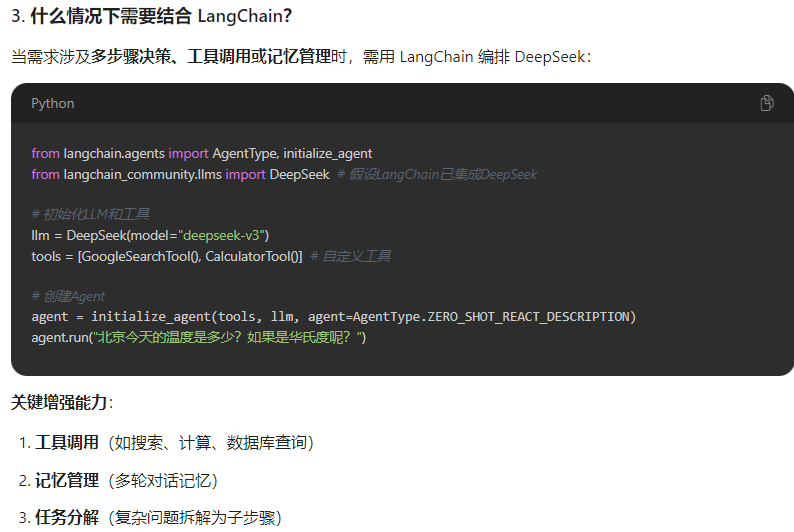
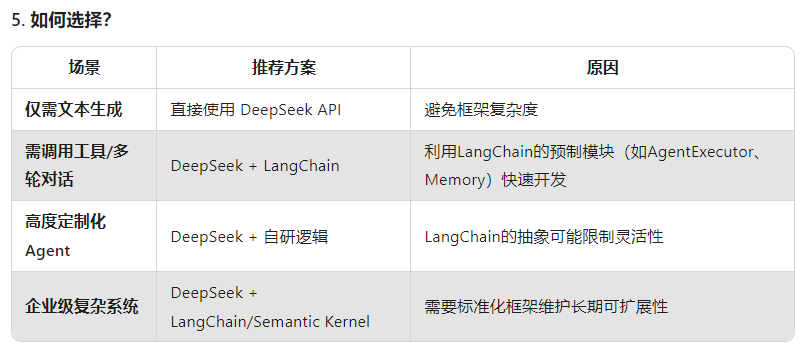
1、deepseek和langchain有什么关联以及使用的场景
2、已有的文档目录如何实现知识库检索
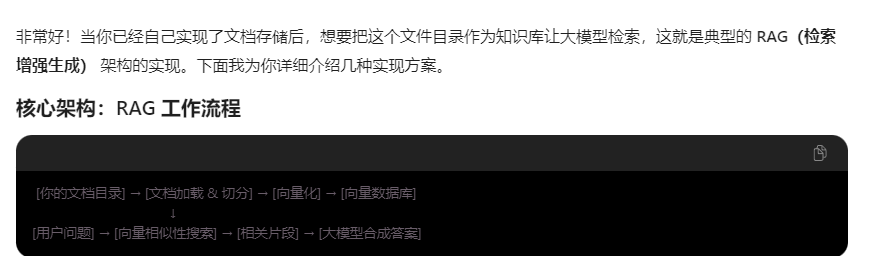
其实就是要把所有文档都加载到向量数据库 大模型才能检索到。
方案一:使用 LangChain/LlamaIndex 框架(推荐)
1. 基于 LangChain 的实现
import os
from langchain.document_loaders import DirectoryLoader, TextLoader, PyPDFLoader, UnstructuredWordDocumentLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import Ollama # 或 OpenAI, Tongyi等
from langchain.chains import RetrievalQA
class DocumentQASystem:
def __init__(self, docs_directory):
self.docs_directory = docs_directory
self.vectorstore = None
def initialize_knowledge_base(self):
"""初始化知识库"""
# 1. 文档文档加载 - 根据不同类型使用不同的loader
loaders = {
'.txt': TextLoader,
'.pdf': PyPDFLoader,
'.docx': UnstructuredWordDocumentLoader,
}
all_docs = []
for ext, loader_class in loaders.items():
try:
loader = DirectoryLoader(
self.docs_directory,
glob=f"**/*{ext}",
loader_cls=loader_class,
show_progress=True
)
docs = loader.load()
all_docs.extend(docs)
except Exception as e:
print(f"加载 {ext} 文件时出错: {e}")
print(f"共加载 {len(all_docs)} 个文档")
# 2. 文本切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个片段的字符数
chunk_overlap=200, # 重叠字符数,保持上下文连贯
length_function=len,
)
splits = text_splitter.split_documents(all_docs)
print(f"切分为 {len(splits)} 个文本片段")
# 3. 向量 向量化模型(本地)
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2" # 轻量且效果好
)
# 4. 创建向量数据库
self.vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./chroma_db" # 向量数据库持久化目录
)
return self
def query(self, question):
"""查询知识库"""
if not self.vectorstore:
raise ValueError("请先初始化知识库")
# 5. 创建检索链
qa_chain = RetrievalQA.from_chain_type(
llm=Ollama(model="qwen:7b"), # 本地LLM,或使用Coze API
chain_type="stuff", # 还有其他方式:map_reduce, refine等
retriever=self.vectorstore.as_retriever(
search_type="similarity", # 相似度搜索
search_kwargs={"k": 4} # 返回最相关的4个片段
),
return_source_documents=True
)
result = qa_chain({"query": question})
return result
# 使用示例
if __name__ == "__main__":
# 初始化
qa_system_system = DocumentQASystem("/path/to/your/documents")
qa_system.initialize_knowledge_base()
# 查询
answer = qa_system.query("你们公司的产品有什么特色?")
print(answer["result"])
# 查看来源文档
for doc in answer["source_documents"]:
print(f"来源: {doc.metadata['source']}, 页码: {doc.metadata.get('page', 'N/A')}")
2. 基于 LlamaIndex 的实现
from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index.llms import Ollama
def setup_llamaindex_knowledgebase(doc_path):
"""使用LlamaIndex设置知识库"""
# 1. 加载文档
documents = SimpleDirectoryReader(doc_path).load_data()
# 2. 配置服务和LLM
embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-zh-v1.5" # 中文优化的向量模型
)
llm = Ollama(model="qwen:7b")
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
chunk_size=1024
)
# 3. 创建索引
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context
)
# 4. 创建查询引擎
query_engine = index.as_query_engine(
similarity_top_k=5,
response_mode="compact"
)
return query_engine
# 使用
query_engine = setup_llamaindex_knowledgebase("/path/to/your/documents")
response = query_engine.query("介绍一下产品的主要功能")
print(response)
3、AI agent的实现原理
AI Agent = LLM + 推理能力 + 工具使用 + 记忆机制
与传统聊天机器人不同,Agent 具有自主性、目标导向和环境交互能力。
总结:
AI Agent的核心原理是将大语言模型从一个单纯的文本生成器升级为具备自主感知、规划、行动、反思能力的智能体。关键在于:
- 推理链路的明确化 - 让思考过程可见可控
- 工具的扩展性 - 突破纯文本的限制
- 记忆的持久化 - 积累经验和知识
- 决策的层次化 - 从战略规划到战术执行
这种架构使得AI能够处理远超单次对话范围的复杂任务,真正成为人类的智能伙伴。
待继续完善。。。。。。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











