




Linux深入理解内存管理38(基于Linux6.6)---kswapd内存回收介绍
一、概述
1. 内存回收的必要性
Linux 系统需要有效管理物理内存(RAM)。随着系统中运行的进程和应用程序增多,内存需求也会增加。如果物理内存耗尽且没有足够的交换空间(swap),系统会变得非常不稳定,甚至导致进程崩溃。因此,内存回收机制在 Linux 中显得尤为重要,尤其是在内存压力较大的情况下。
内存回收的目标:
- 保持系统的响应性:确保系统在内存紧张时能够继续运行。
- 避免OOM(Out of Memory,内存不足)错误:通过回收内存或将内存交换到磁盘来避免内存耗尽。
- 优化系统性能:通过适时回收不必要的内存,避免内存的过度使用。
2. kswapd 的工作原理
kswapd 是 Linux 内核中的一个内存管理线程,主要负责在系统内存紧张时进行内存回收操作。其主要任务是将不活跃的内存页面交换到磁盘交换空间,从而释放物理内存供其他进程使用。
基本操作流程:
- 内存压力监测:当系统的空闲内存较低时,
kswapd会被唤醒。内核通过min_free_kbytes参数、free内存页面、以及其他内存状态信息来判断是否需要触发回收操作。 - 选择交换页面:
kswapd会选择一些“脏页”(dirty pages)来回收。脏页是指修改过但尚未写回磁盘的页面。这些页面通常是文件映射、匿名内存或缓存。 - 交换(Swap)操作:将选中的脏页交换到磁盘上的交换空间(swap partition 或 swap file),以释放内存资源。交换是将内存中的页面移动到硬盘的交换区(swap space),这虽然缓解了内存压力,但交换到磁盘的速度远低于内存,可能会影响系统性能。
- 回收页缓存:除了交换页面,
kswapd还会尝试回收页缓存(Page Cache),即那些用于缓存文件系统内容的内存页面。 - 内存释放:在
kswapd完成回收工作后,系统会释放出一定数量的内存页面,减少内存压力。
3. kswapd 的启动与调度
kswapd 是由内核启动的守护进程,它会在系统内存紧张时自动唤醒,并执行内存回收任务。它通常在系统启动时就会开始运行,作为一个内核线程在后台工作,周期性地检查系统内存的状态。
触发条件:
- 内存过低:当系统的空闲内存低于设定的阈值时(通常由
lowmem_reserve_ratio和min_free_kbytes等参数控制),kswapd会被唤醒。 - 内存碎片化:内存碎片化也可能会触发
kswapd的工作,特别是在没有足够连续空闲内存块的情况下。
执行周期:
kswapd 并不是在内存压力高时立即执行回收操作,而是每隔一段时间会检查一次内存的使用情况,避免过于频繁地进行内存回收,从而影响系统性能。它通过内核的调度机制以较低的优先级运行,因此在内存回收时不会对系统的其它任务造成太大干扰。
4. 交换空间与 kswapd 的关系
交换空间是系统在内存不足时用来存储内存页面的磁盘区域。Linux 内核提供了两种类型的交换空间:
- 交换分区(swap partition):一个专用的磁盘分区,用于存放交换页面。
- 交换文件(swap file):一个特殊的文件,存储在磁盘上,也用作交换空间。
当系统内存压力增加时,kswapd 会把内存页面交换到这些交换区域。交换操作会增加磁盘 I/O,这对系统性能有一定影响,因为磁盘的读写速度远低于内存。
5. kswapd 的调度与优先级
kswapd 作为内核线程,其调度优先级较低。它通过系统调度器周期性地运行,并且只有在内存压力达到一定程度时才会被调度执行。虽然它运行的优先级较低,但它的任务依然非常重要,因为它直接影响到系统的内存管理和稳定性。
在linux操作系统中,当内存充足的时候,内核会尽量使用内存作为文件缓存(page cache),从而提高系统的性能。例如page cache缓冲硬盘中的内容,dcache、icache缓存文件系统的数据,这些内容是为了提升性能而设计的,还可以再次从硬盘中重新读取来构建对象,这部分内容可以在内存紧张的时候可以直接释放。
所以内存回收在Linux内存管理中占据非常重要的地位,系统的内存毕竟是有限的,跑的进程成百上千,系统的内存越来越小,必须提供内存回收的机制,以满足别的任务的需求。在内存回收的过程中,会遇到以下问题
- 有哪些内存可以回收
- 什么时候回收,就需要了解回收解决什么问题?回收内存的策略是如何的
- 回收内存时,如何尽可能的减小对系统的性能的影响
二、内存回收的目标
对于内核并不是所有的物理内存都可以参与回收,比如内核的代码段,如果被内核回收了,系统就无法正常运行了,所以一般内核代码段、数据段、内核申请的内存、内核线程占用的内存等都是不可以回收的,除此之外的内存都可以是我们要回收的目标。
内核空间是所有进程公用的,内核中使用的页通常是伴随整个系统运行周期的,频繁的页换入和换出是非常影响性能的,所以内核中的页基本上不能回收,不是技术上实现不了而是这样做得不偿失。
同时,另外一种是应用程序主动申请锁定的页,它的实时性要求比较高,频繁的换入换出和缺页异常处理无法满足它对于时间上的要求,所以这部分程序可能使用mlock api将页主动锁定,不允许它进行回收。
那么我们就比较明确了,并非内存中的所有页面都是可以交换出去的。事实上,只有与用户空间建立了映射关系的物理页面才会被换出去,而内核空间中内核所占的页面则常驻内存。我们下面对用户空间中的页面和内核空间中的页面给出进一步的分类讨论。可以把用户空间中的页面按其内容和性质分为以下几种:
- 进程映像所占的页面,包括进程的代码段、数据段、堆栈段以及动态分配的“存储堆。
- 进程的代码段和数据段所占用的内存页面是可以被换入换出的。
- 通过系统调用mmap()把文件的内容映射到用户空间。
- 这些页面所使用的交换区就是被映射的文件本身。
- 进程间共享内存区。
- 其页面的换入换出比较复杂。
除此之外,内核在执行过程中使用的页面要经过动态分配,但永驻内存,此类页面根据其内容和性质可以分为两类:
- 内核调用kmalloc()或vmalloc()为内核中临时使用的数据结构而分配的页于是立即释放。但是,由于一个页面中存放有多个同种类型的数据结构,所以要到整个页面都空闲时才把该页面释放。
- 内核中通过调用alloc_pages(),为某些临时使用和管理目的而分配的页面,例如,每个进程的内核栈所占的两个页面、从内核空间复制参数时所使用的页面等等。这些页面也是一旦使用完毕便无保存价值,所以立即释放。
在内核中还有一种页面,虽然使用完毕,但其内容仍有保存价值,因此,并不立即释放。这类页面“释放”之后进入一个LRU队列,经过一段时间的缓冲让其“老 化”。如果在此期间又要用到其内容了,就又将其投入使用,否则便继续让其老化,直到条件不再允许时才加以回收。这种用途的内核页面大致有以下这些:
- 文件系统中用来缓冲存储一些文件目录结构dentry的空间。
- 文件系统中用来缓冲存储一些索引节点inode的空间。
- 用于文件系统读/写操作的缓冲区。
按照以上所述,对于内存回收,大致可以分为以下两类:
- 文件映射的页,包括page cache、slab中的dcache、icache、用户进程的可执行程序的代码段,文件映射页面。
其中page cache包括文件系统的page,还包括块设备的buffer cache,万物皆文件,block也是一种文件,它也有关联的file、inode等。另外根据页是否是脏的,在回收的时候处理有所不同,脏页需要先回写到磁盘再回收,干净的页可以直接释放。
- 匿名页,括进程使用各种api(malloc,mmap,brk/sbrk)申请到的物理内存(这些api通常只是申请虚拟地址,真实的页分配发生在page fault中),包括堆、栈,进程间通信中的共享内存,pipe,bss段,数据段,tmpfs的页。这部分没有办法直接回写,为他们创建swap区域,这些页也转化成了文件映射的页,可以回写到磁盘。
三、内存回收机制
内核之所以要进行内存回收,主要原因有两个:
- 内核需要为任何时刻突发到来的内存申请提供足够的内存,以便cache的使用和其他相关内存的使用不至于让系统的剩余内存长期处于很少的状态。
内核使用内存中的page cache对部分文件进行缓存,以便提升文件的读写效率。所以内核有必要设计一个周期性回收内存的机制,以便cache的使用和其他相关内存的使用不至于让系统的剩余内存长期处于很少的状态。
- 当真的有大于空闲内存的申请到来的时候,会触发强制内存回收。
所以内核针对这两种回收的需求,分别实现了两种不同的机制。
- 针对第①种,Linux系统设计了kswapd后台程序,当内核分配物理页面时,由于系统内存短缺,没法在低水位情况下分配内存,因此会唤醒kswapd内核线程来异步回收内存
- 针对第②种,Linux系统会触发直接内存回收(direct reclaim),在内核调用页分配函数分配物理页面时,由于系统内存短缺,不能满足分配请求,内核就会直接触发页面回收机制,尝试回收内存来解决问题
这两种回收的触发方式不同,其区别如下图所示:
| 特点 | kswapd 回收 | 直接内存回收 |
|---|---|---|
| 触发机制 | 系统内存压力较大时自动触发,通常是空闲内存不足 | 系统内存不足或进程需要更多内存时由内核直接触发 |
| 回收方式 | 通过将不活跃的内存页面交换到磁盘交换空间(swap) | 直接回收页缓存、匿名页或文件映射的内存页面 |
| 内存回收目标 | 释放内存,通过将内存页面交换到磁盘来腾出空间 | 回收未被使用或低优先级的内存页面,通常优先回收脏页 |
| 回收对象 | 主要是交换空间中的页面,通常是脏页和不活跃的缓存 | 包括页缓存、匿名内存、文件映射等各类内存页面 |
| 执行优先级 | 优先级较低,由内核定期调度运行 | 优先级较高,通常在内存紧张时直接触发 |
| 性能影响 | 交换到磁盘的速度较慢,可能导致较大的磁盘I/O,影响性能 | 回收内存页面通常较快,性能影响较小 |
| 内存回收效果 | 主要通过交换将内存页面转移到磁盘,可能导致性能下降 | 直接释放内存,通常能迅速减少内存压力 |
| 内存压力应对方式 | 通过交换减少内存占用,但可能导致交换延迟 | 直接回收内存,减少内存占用,避免系统过载 |
| 影响的系统组件 | 影响交换空间和磁盘 I/O,可能导致交换延迟 | 主要影响内存分配和页面回收,不涉及磁盘 I/O |
| 触发时机 | 系统内存不足时自动触发,内核定期检查内存状态 | 系统内存压力大时直接触发,通常在内存分配失败时进行回收 |
四、kswapd内核线程
为了避免总在CPU忙碌时也就是缺页异常发生时,临时再来搜寻空页面换出的页面进行换出,内核将定期检查并预先将若干页面换出以腾出空间,维持系统空闲内存的的保有量,以减轻系统在缺页异常发生时的负担。为此内核设置了一个专司页面换出的守护神kswapd进程。
kswapd内核线程初始化时会为系统每个NUMA内存节点创建一个名为“kswapd%d”的内核线程,kswapd进程创建的代码如下:
mm/vmscan.c
static int __init kswapd_init(void)
{
int nid;
swap_setup();
for_each_node_state(nid, N_MEMORY)
kswapd_run(nid);
return 0;
}
module_init(kswapd_init)
- swap_setup函数根据物理内存大小设定全局变量page_cluster,当megs小于16时候,page_cluster为2,否则为3。
page_cluster为每次swap in或者swap out操作多少内存页 为2的指数,当为0的时候,为1页,为1的时候,2页,2的时候4页,通过/proc/sys/vm/page-cluster 查看。
- 然后通过for_each_node_state遍历所有 节点,kswapd_run中kthread_run为每个节点创建一 个kswapd%d线程。
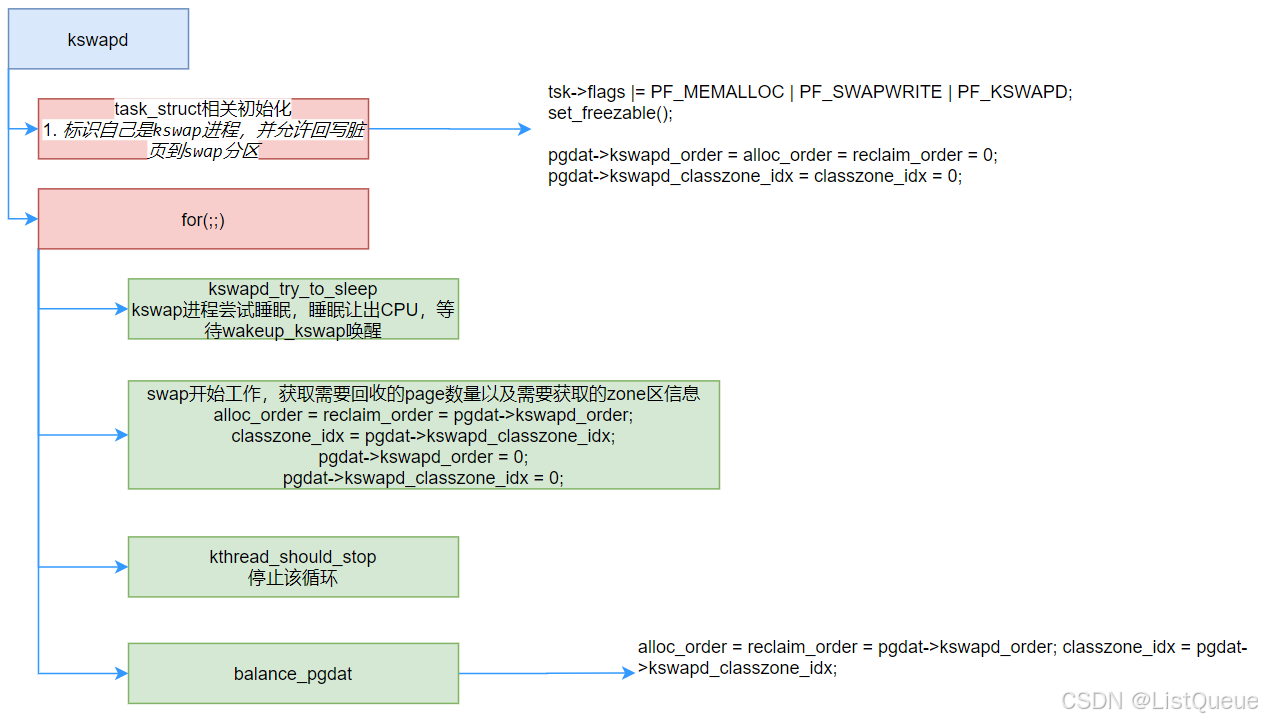
Kswapd的主循环是一个死循环,只有当kthread _should_stop的时候才会break跳出循环体,会kswapd_try_to_sleep中睡眠,并让出CPU控制权。当系统内存紧张时,这时内存分配函数会调用wakeup_kswapd()来唤醒kswapd内核线程,此时kswapd内核线程在kswapd_try_to_sleep函数中被唤醒,然后调用balance_pgdat()函数来回收页面。下面重点是看看kswapd_try_to_sleep。
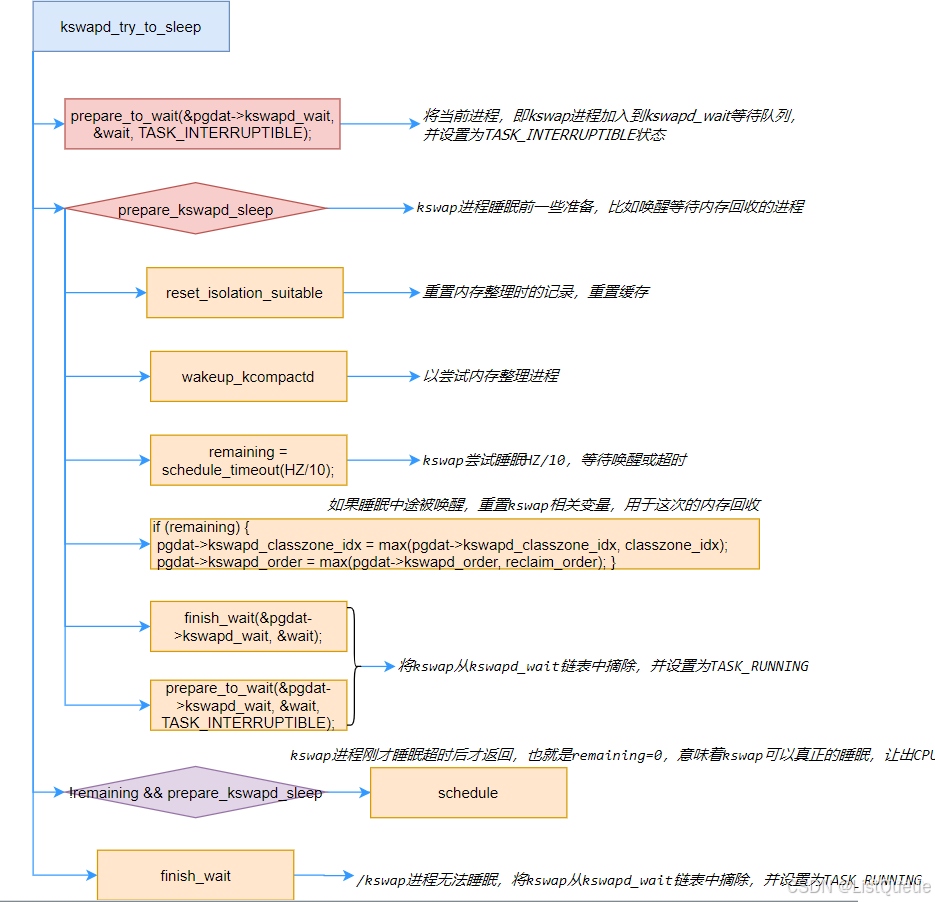
其主要的流程为:
- 首先,定义一个wait在kswapd_wait上等待,设置进程状态为TASK_INTERRUPTIBLE,通过prepare_kswapd_sleep判断kswapd是否准好睡眠。
- 可以尝试睡眠HZ/10,若返回不为0,则说明没有HZ/10内没有被唤醒了,HZ一般定义为1000,则是100ms。
- 如果中途没有被唤醒,说明kswap可以睡眠,让出CPU,schedule出去。
- 如果中途被唤醒则返回上层函数,执行内存回收。
4.1、kswap的触发条件
kswap进程虽然是系统启动时就会创建,但是大多数时候它处于睡眠状态,只有在进程由于内存不足导致分配内存失败时会被唤醒,从而回收内存,供进程使用。
在NUMA系统中,使用pg_data_t来描述物理内存布局,和kswapd相关参数有。
include/linux/mmzone.h
typedef struct pglist_data {
...
wait_queue_head_t kswapd_wait;//等待队列
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* Protected by mem_hotplug_begin/end() */
int kswapd_max_order;
enum zone_type classzone_idx;/最合适分配内存的zone序号
...
} pg_data_t;
- kswapd_wait是一个等待队列,每个pg_data_t都有一个等待队列,在free_area_init_core函数中初始化。
- kswapd_max_order和classzone_idx:在分配内存路径上的唤醒函数wakeup_kswapd作为参数传递给kswapd内核线程。
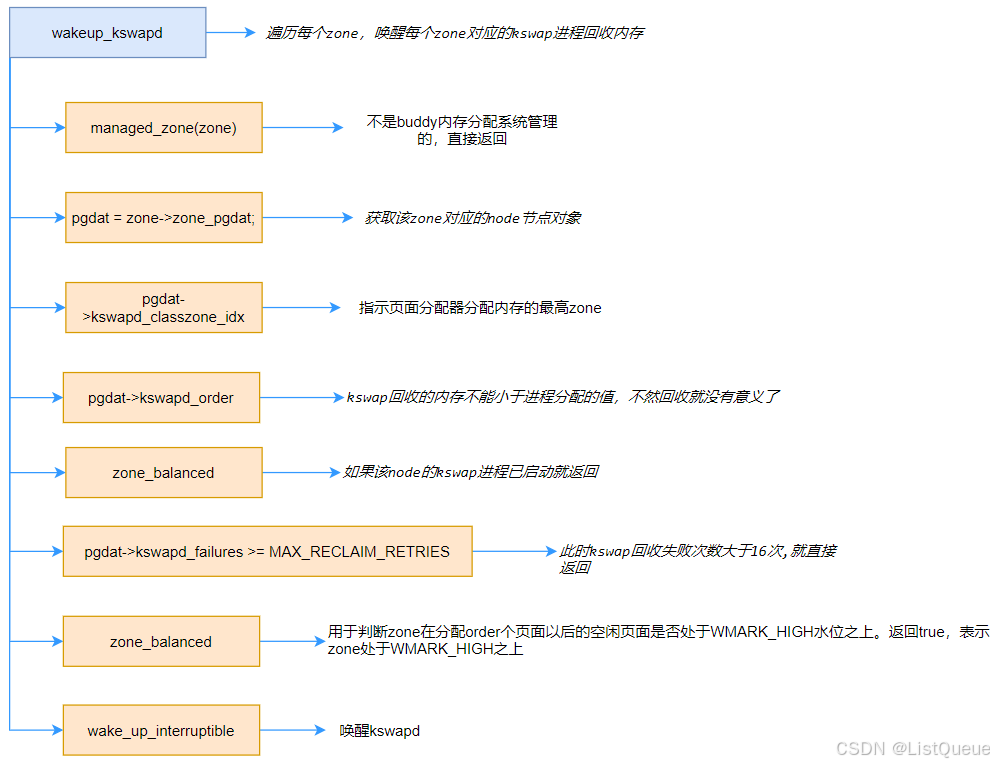
在分配内存路径上,如果在低水位(ALLOC_WMARK_LOW)的情况下无法成功分配内存,那么就会通过wakeup_kswapd函数唤醒kswapd内核线程来回收页面以便释放一些内存。
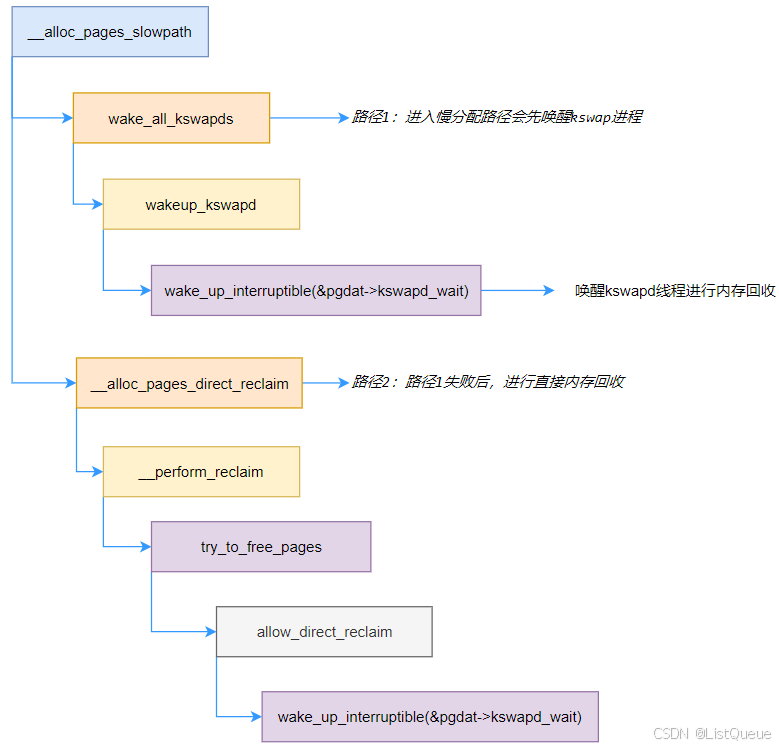
- kswap唤醒路径1
在这种情况下,使用wake_all_kswapds函数唤醒kswapd内核线程来回收内存,以便释放一些内存。
- kswap唤醒路径2——直接内存回收(阻塞)
当路径1唤醒kswap返回后,会尝试分配内存,如果还是失败,会再一次切换zone,如果切换后还是无法分配出内存,就只能进行直接内存回收了。直接回收内存阻塞在于throttle_direct_reclaim,它会一直唤醒kswap回收内存,直到空闲内存满足要求才返回。
4.2、balance_pgdat函数
kswapd内核线程被唤醒后,调用balance_pgdat来回收页面,balance_pgdat()是回收页面的主函数。这是一个大循环,首先从高端zone往低端zone方向查找第一个处于不平衡状态end_zone;而后从最低端zone开始回收页面,直到end_zone;在大循环里检查从最低端zone到classzone_idx的zone是否处于平衡状态,而后不断加大扫描力度。
在kswapd回收内存过程中有一个扫描控制结构体,用于控制这个回收过程。既然是回收内存,就需要明确要回收多少内存,在哪里回收,以及回收时的操作权限等,我们看下这个控制结构struct scan_control主要的一些变量。
mm/vmscan.c
struct scan_control {
unsigned long nr_to_reclaim; //shrink_list()需要回收的页面数量
gfp_t gfp_mask;//分配掩码
int order; //进程内存分配页面数量,从分配器传递过来的参数
nodemask_t *nodemask; //指定可以在那个node回收内存
struct mem_cgroup *target_mem_cgroup; //是否针对某个cgroup扫描回收内存
int priority; //控制每次扫描数量,默认是总页数的1/4096
enum zone_type reclaim_idx; //进行页面回收的最大zone id
unsigned int may_writepage:1; //是否可以回写
unsigned int may_unmap:1; //是否可以执行unmap
unsigned int may_swap:1; //是否可以将页面交换
...
unsigned int compaction_ready:1; //是否可以进行内存压缩,即碎片整理
unsigned long nr_scanned; //已扫描的非活动页面数量
unsigned long nr_reclaimed; //shrink_zones()中已回收页面数量
...
};
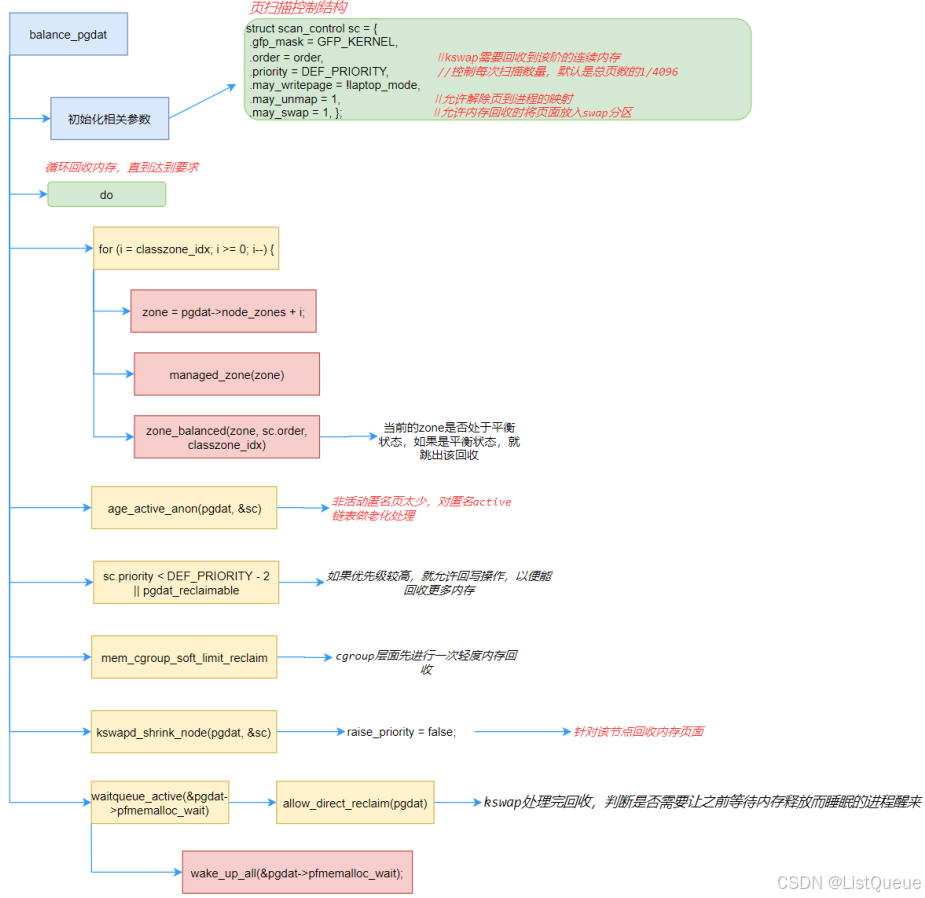
该函数中有两个重要的函数,zone_balanced用于判断zone在分配order个页面以后的空闲页面是否处于WMARK_HIGH水位之上。返回true,表示zone处于WMARK_HIGH之上。
static bool zone_balanced(struct zone *zone, int order, int classzone_idx)
{
unsigned long mark = high_wmark_pages(zone);
if (!zone_watermark_ok_safe(zone, order, mark, classzone_idx))
return false;
/*
* If any eligible zone is balanced then the node is not considered
* to be congested or dirty
*/
clear_bit(PGDAT_CONGESTED, &zone->zone_pgdat->flags);
clear_bit(PGDAT_DIRTY, &zone->zone_pgdat->flags);
return true;
}
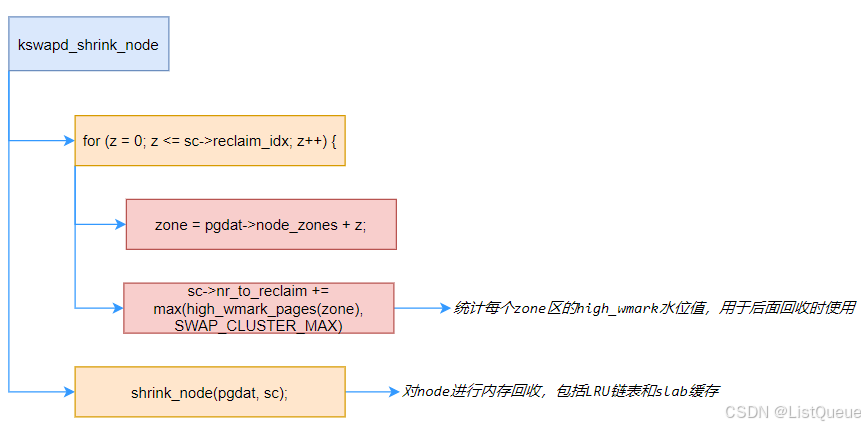
对于这块后面再单独分析,主要关注重点的函数kswapd_shrink_node,其处理流程如下:
五、总结
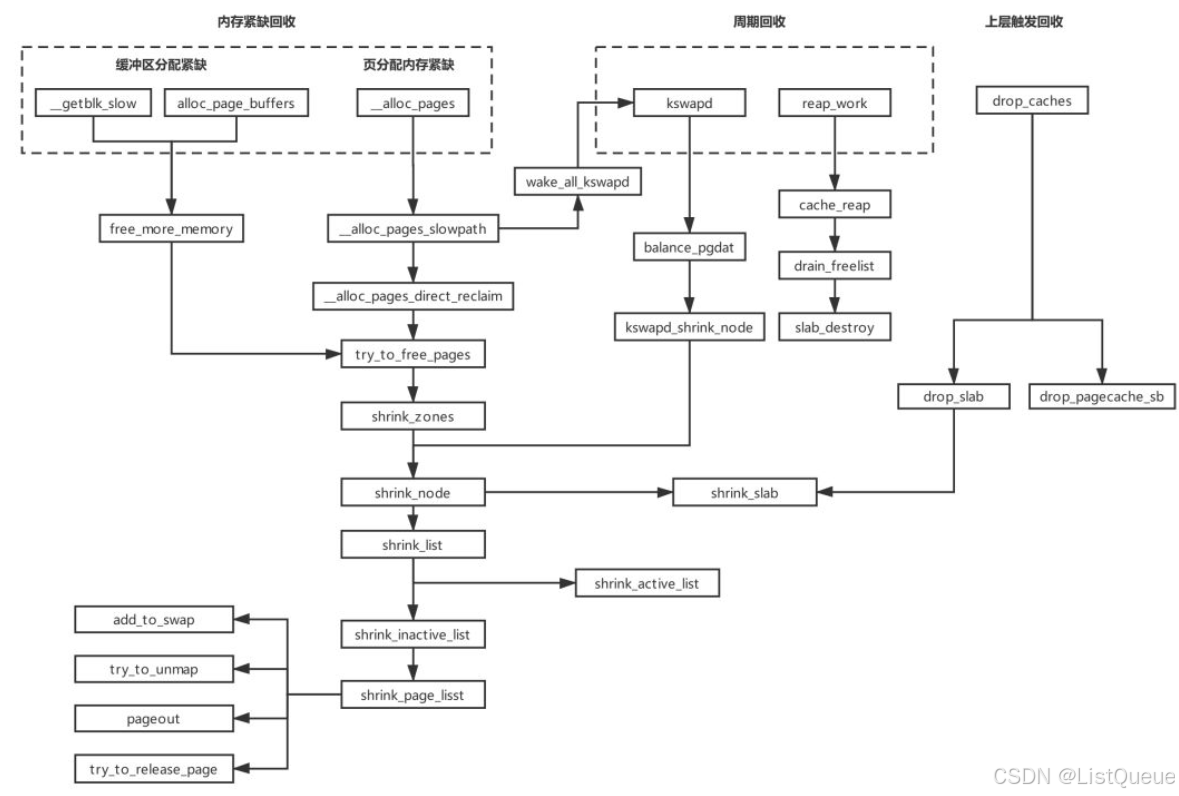
Linux内核触发页面回收的机制有3个:
- 直接页面回收机制: 在内核态调用页面分配接口函数分配物理内存时,由于系统内存短缺,不能满足分配请求,因此会直接到页面回收机制,尝试回收内存来解决当前的问题
- 周期性内存回收机制:也就是kswapd内核线程的工作职责,当内核路径调用alloc_pages分配物理内存页面时,由于系统内存短缺,没法再低水位情况下分配内存,因此会唤醒kswapd的内核线程来异步回收内存
- slab(slab shrinker机制):对于slab,是由缓存的,所以当内存短缺,直接页面回收和周期性回收内存会调用slab回收机制回收对象。
slab机制分配的内存主要是用于slab对象和kmalloc接口,页可以用于内核空间的内存分配,比较文件的Node缓存等。
kswapd本身是一个内核线程,它和调用的关系是异步的,如我们用户空间的进程尝试调用alloc_pages来分配内存,当发现在低水位的情况下无法分配出内存时,它将唤醒kswapd内核线程。这时,Kswapd内核线程就开始执行页面回收工作了,同时test进程会尝试其他办法来分配内存,如调用直接回收内存机制。所以对于页面回收机制的主要调用关系如下图所示
1、内存回收机制
内存回收是内存管理的关键部分,目的是在系统面临内存压力时,尽量回收不再需要的内存资源,确保系统持续稳定运行。
交换(Swap)机制
当物理内存不足时,Linux 会将一部分不活跃的内存页面交换到硬盘上的 swap 分区 或 swap 文件 中。交换的过程主要由 kswapd 进程管理。
- kswapd:内核线程,在系统内存压力较大时自动进行内存回收,将内存页面交换到 swap 中以释放物理内存。
- Swap 机制的代价:虽然可以缓解内存不足的情况,但从内存交换到磁盘的操作速度较慢,可能会导致 I/O 操作瓶颈,进而影响系统性能。
页面回收(Page Reclamation)
Linux 使用 页面回收 来管理内存压力下的内存释放。页面回收主要通过以下几种方式进行:
- 清理脏页(Dirty Pages):内存中的页面如果被修改过,会标记为“脏”状态。在系统空闲时,这些脏页会被写回磁盘,以释放内存。
- 回收匿名页:匿名内存(如进程的堆栈和堆)在系统内存不足时会被回收。回收过程中,内核会选择优先回收不活跃的页面。
- 回收文件缓存:当文件缓存占用过多内存时,内核会根据需要回收一部分文件页面。
内存压力与 OOM(Out-Of-Memory)管理
当内存不足,且无法通过回收、交换等方式释放足够的内存时,Linux 会触发 OOM Killer(内存溢出杀手)机制。
- OOM Killer:当系统内存不足时,OOM Killer 会选择终止某些进程,优先选择占用内存最多的进程,以释放内存资源。
- OOM 管理:OOM Killer 的触发条件和选择策略会根据内核配置进行调节,可以通过内核参数调整。
直接内存回收(Direct Memory Reclamation)
- kswapd 回收内存的过程是通过交换(swap)等方式实现的,但在内存压力更大时,系统会直接回收内存。
- 直接回收机制:当系统发现内存资源无法满足需求时,会直接回收未被使用的内存页,减少内存占用,从而避免内存分配失败。
2、内存回收算法与策略
LRU(Least Recently Used)算法
Linux 内核使用 LRU(最近最少使用) 算法来管理内存页面的回收。页面被访问时,会被标记为“最近使用”。LRU 算法优先回收最久未被使用的页面。
页面移位(Page Migration)
Linux 还支持页面的迁移(page migration),尤其是在 NUMA(非统一内存访问)架构下。页面可以从一个 NUMA 节点迁移到另一个节点,以提高内存访问效率。
内存整理(Memory Compaction)
内存碎片问题是内存回收中的一个重要挑战。Linux 提供了内存整理(compaction)机制,它将分散的内存页合并成连续的大块内存页,以提高大块内存分配的效率。

















 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









