




Linux深入理解内存管理24(基于Linux6.6)---伙伴系统页面分配介绍
一、概述
伙伴系统分配是如何分配出连续的物理页面的。内核中常用的分配物理内存页面的接口是alloc_pages,用于分配一个或者多个连续的物理页面,分配的页面个数只能是2^n。相对于多次离散的物理页面,分配连续的物理页面有利于提高系统内存的碎片化。
1. 基本原理
伙伴系统的基本思想是将内存划分成大小为2的幂次方的块(页面)。内存被分成多个“块”(通常是内存页),这些块的大小为2的幂。通过对这些块进行分配和回收,系统可以高效地管理内存,同时减少碎片。
- 页面:通常是4KB的基本内存单位,或者根据体系结构的不同,可能为更大的单位(如8KB、16KB等)。
- 块的大小:内存块的大小是2的幂次方,例如:1页(4KB)、2页(8KB)、4页(16KB)等。
2. 内存分配过程
-
页面大小与块的匹配:
- 当系统需要分配内存时,首先会选择最接近的2的幂次方大小的块。比如,如果请求的内存是5KB,系统将分配一个8KB的块。
-
分配页面:
- 如果当前没有足够大小的空闲块,系统会尝试分割更大的块。比如,如果请求了8KB内存,但只有16KB的块空闲,系统会将16KB的块分割成两个8KB的块,一个分配给请求的进程,另一个继续保留为空闲块。
-
分割过程:
- 当一个较大的内存块被请求时,系统会将较大的块分割成两块大小相同的较小块。这个过程一直持续,直到分割出的块大小与请求的内存块大小匹配为止。
-
合并过程:
- 当一个内存块被释放时,系统会检查该块的“伙伴”是否也处于空闲状态。如果是,两个空闲的块就会合并成一个更大的块,从而减少内存碎片。
3. 合并与分割
- 合并(Coalescing):当两个“伙伴”块都是空闲的,它们可以被合并成一个更大的块。这有助于减少内存碎片并使内存更加连续。
- 分割(Splitting):当请求的内存较大时,系统将一个较大的块分割成两个较小的块。这一过程保证了内存分配时块的大小始终是2的幂。
4. 内存块的管理
Linux内核通过**页框(Page Frame)来管理内存,而这些页框被分成多个“区域”(zones),每个区域包含一组相同大小的空闲块。每个块都被组织在一个空闲链表(free list)中,按块的大小分类。对于每个大小类别,Linux使用一个空闲区域(free area)**来存储空闲块。
- 空闲链表:每个大小的块都有一个空闲链表,空闲块被插入到对应大小的链表中。每个空闲链表包含所有大小相同的空闲块。
- 页框(Page Frames):每个物理内存页面被称为一个页框,内核管理这些页面的分配和回收。
二、页的分配
对于所有的内存分配接口,最后都会调用alloc_pages_node,这个是伙伴系统最重要的接口,其定义如下:
include/linux/gfp.h
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (nid == NUMA_NO_NODE)
nid = numa_mem_id();
return __alloc_pages_node(nid, gfp_mask, order);
}
这个函数只是执行了一个简单的检查,防止申请的过大的内存。如果指定节点不存在,内核自动使用当前执行CPU对应的节点ID,最终调用prepare_alloc_pages,这个函数使伙伴系统的核心函数,下面来看看这个函数处理流程:
mm/page_alloc.c
static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order,
int preferred_nid, nodemask_t *nodemask,
struct alloc_context *ac, gfp_t *alloc_gfp,
unsigned int *alloc_flags)
{
ac->highest_zoneidx = gfp_zone(gfp_mask);
ac->zonelist = node_zonelist(preferred_nid, gfp_mask);
ac->nodemask = nodemask;
ac->migratetype = gfp_migratetype(gfp_mask);
if (cpusets_enabled()) {
*alloc_gfp |= __GFP_HARDWALL;
/*
* When we are in the interrupt context, it is irrelevant
* to the current task context. It means that any node ok.
*/
if (in_task() && !ac->nodemask)
ac->nodemask = &cpuset_current_mems_allowed;
else
*alloc_flags |= ALLOC_CPUSET;
}
might_alloc(gfp_mask);
if (should_fail_alloc_page(gfp_mask, order))
return false;
*alloc_flags = gfp_to_alloc_flags_cma(gfp_mask, *alloc_flags);
/* Dirty zone balancing only done in the fast path */
ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE);
/*
* The preferred zone is used for statistics but crucially it is
* also used as the starting point for the zonelist iterator. It
* may get reset for allocations that ignore memory policies.
*/
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->highest_zoneidx, ac->nodemask);
return true;
}
struct alloc_context数据结构是伙伴系统分配函数中用于保存相关参数的数据结构,对于该结构gfp_zone()函数从分配掩码中计算出zone的zoneidx,并放到high_zoneidx成员中。
include/linux/gfp.h
static inline enum zone_type gfp_zone(gfp_t flags)
{
enum zone_type z;
int bit = (__force int) (flags & GFP_ZONEMASK);
z = (GFP_ZONE_TABLE >> (bit * GFP_ZONES_SHIFT)) &
((1 << GFP_ZONES_SHIFT) - 1);
VM_BUG_ON((GFP_ZONE_BAD >> bit) & 1);
return z;
}
首先flags&GFP_ZONEMASK,是将与GFP_XXX无关的其他位清零, 内核通过标志判断从哪个zone分配内存。而对于该结构体中,通过gfp_migratetype函数将gpf_mask分配掩码转换成MIGRATE_TYPES类型,例如分配的掩码为GFP_KERNEL,那么其类型为MIGRATE_UNMOVABLE;如果分配的掩码为GFP_HIGHUSER_MOVABLE,那么类型就是MIGRATE_MOVABLE,其定义为:
include/linux/gfp.h
static inline int gfp_migratetype(const gfp_t gfp_flags)
{
VM_WARN_ON((gfp_flags & GFP_MOVABLE_MASK) == GFP_MOVABLE_MASK);
BUILD_BUG_ON((1UL << GFP_MOVABLE_SHIFT) != ___GFP_MOVABLE);
BUILD_BUG_ON((___GFP_MOVABLE >> GFP_MOVABLE_SHIFT) != MIGRATE_MOVABLE);
BUILD_BUG_ON((___GFP_RECLAIMABLE >> GFP_MOVABLE_SHIFT) != MIGRATE_RECLAIMABLE);
BUILD_BUG_ON(((___GFP_MOVABLE | ___GFP_RECLAIMABLE) >>
GFP_MOVABLE_SHIFT) != MIGRATE_HIGHATOMIC);
if (unlikely(page_group_by_mobility_disabled))
return MIGRATE_UNMOVABLE;
/* Group based on mobility */
return (__force unsigned long)(gfp_flags & GFP_MOVABLE_MASK) >> GFP_MOVABLE_SHIFT;
}
然后进入到should_fail_alloc_page函数,检查内存分配是否可行,如果不可行就直接返回,即以失败告终,否则就继续执行内存分配,之后就是一些判断条件,然后进入到真正尝试分配物理页面,其处理流程如下:
mm/page_alloc.c
noinline bool should_fail_alloc_page(gfp_t gfp_mask, unsigned int order)
{
return __should_fail_alloc_page(gfp_mask, order);
}
ALLOW_ERROR_INJECTION(should_fail_alloc_page, TRUE);
* may get reset for allocations that ignore memory policies.
*/
ac.preferred_zoneref = first_zones_zonelist(ac.zonelist,
ac.high_zoneidx, ac.nodemask);
if (!ac.preferred_zoneref->zone) {
page = NULL;
/*
* This might be due to race with cpuset_current_mems_allowed
* update, so make sure we retry with original nodemask in the
* slow path.
*/
goto no_zone;
}
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
首先通过first_zones_zonelist()从给定的zoneidx开始查找,这个给定的zoneidx就是highidx,之前通过gfp_zone()函数转换得来的:
include/linux/mmzone.h
static inline struct zoneref *first_zones_zonelist(struct zonelist *zonelist,
enum zone_type highest_zoneidx,
nodemask_t *nodes)
{
return next_zones_zonelist(zonelist->_zonerefs,
highest_zoneidx, nodes);
}
first_zones_zonelist()函数会调用next_zones_zonelist()函数来计算zoneref,最后返回zone数据结构:
mm/mmzone.c
struct zoneref *__next_zones_zonelist(struct zoneref *z,
enum zone_type highest_zoneidx,
nodemask_t *nodes)
{
/*
* Find the next suitable zone to use for the allocation.
* Only filter based on nodemask if it's set
*/
if (likely(nodes == NULL))
while (zonelist_zone_idx(z) > highest_zoneidx)
z++;
else
while (zonelist_zone_idx(z) > highest_zoneidx ||
(z->zone && !zref_in_nodemask(z, nodes)))
z++;
return z;
该函数提供3个参数,对于处理如下:
- highest_zoneidx是gfp_zone()函数计算分配掩码得来;
- z是通过node_zonelist,主要是node_zonelists,zone在系统处理时会初始化这个数组,具体函数在build_zonelists_node()中,分配物理页面时会优先考虑ZONE_HIGHMEM,因为ZONE_HIGHMEM在zonelist中排在ZONE_NORMAL前面;
- nodes,一般为NULL。
如果分配gfp_zone(GFP_KERNEL)函数返回0,那么highest_zoneidx为0,而这个节点在内存第按高到低排列,那么第一个zone是ZONE_HIGHMEM,其zone编号zone_index的值为1,因此最终next_zones_zonelist中,z++,那么返回的是ZONE_NORMAL;而如果分配的时gfp_zone(GFP_HIGHUSER_MOVABLE),那么这个highest_zoneidx返回的时2,所以zone_index的值小于highest_zoneidx,那么就直接返回ZONE_HIGHMEM。
mm/page_alloc.c
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
no_zone:
/*
* Runtime PM, block IO and its error handling path can deadlock
* because I/O on the device might not complete.
*/
alloc_mask = memalloc_noio_flags(gfp_mask);
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
if (unlikely(ac.nodemask != nodemask))
ac.nodemask = nodemask;
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
- 首先get_page_from_freelist()会去尝试分配物理页面,这里是快速分配,是以alloc_flags = ALLOC_WMARK_LOW为参数,以low为标准,遍历zonelist,尝试获取2^order个连续的页框,在遍历zone时,如果zone的当前空闲内存减去需要申请的内存之后,空闲内存是低于low阀值,那么此zone会进行快速内存回收。
- 如果这里分配失败,就会调用到__alloc_pages_slowpath()函数,这里是慢速分配,并且同样分配时不允许进行IO操作 ,这个函数会尝试唤醒页框回收线程,后面会详细分析。
三、Alloc fast path
首先来看看快速分配get_page_from_freelist()接口函数,其主要流程如下:
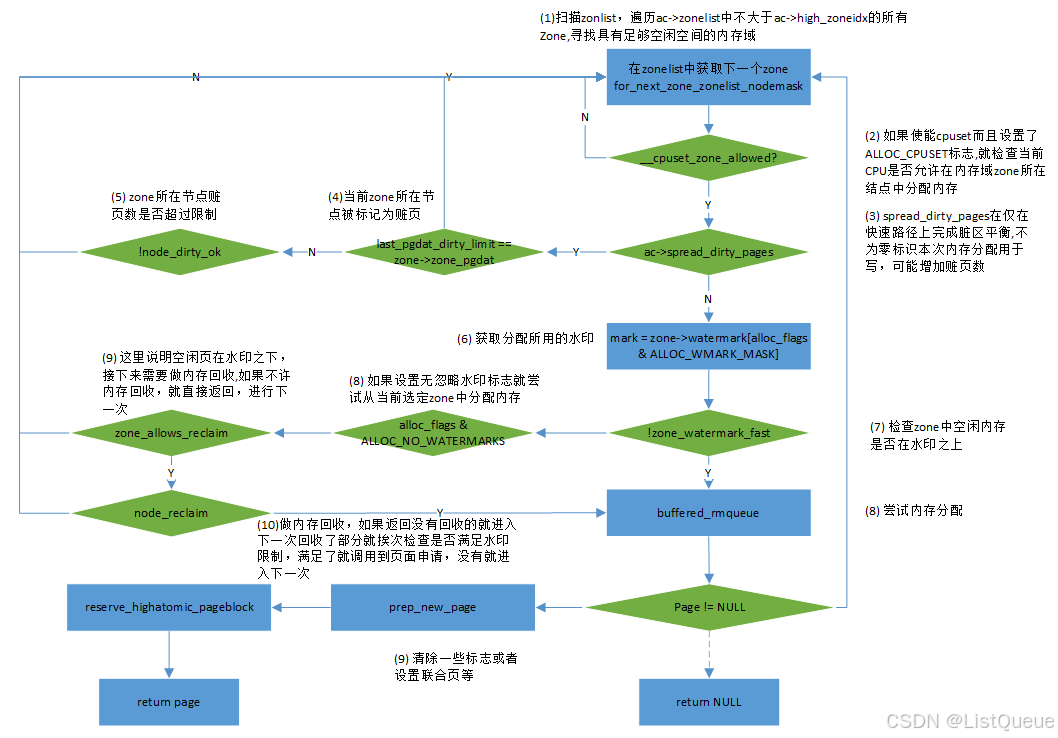
从流程中,当判断当前的zone空闲页面低于WMARK_LOW水位后,会调用node_reclaim函数进行页面回收;而当空闲页面充足时候,会调用rmqueue_buddy函数从伙伴系统中分配物理页面
static __always_inline
struct page *rmqueue_buddy(struct zone *preferred_zone, struct zone *zone,
unsigned int order, unsigned int alloc_flags,
int migratetype)
{
struct page *page;
unsigned long flags;
do {
page = NULL;
spin_lock_irqsave(&zone->lock, flags);//禁止本地CPU中断,禁止前先保存中断状态
/*
* order-0 request can reach here when the pcplist is skipped
* due to non-CMA allocation context. HIGHATOMIC area is
* reserved for high-order atomic allocation, so order-0
* request should skip it.
*/
if (order > 0 && alloc_flags & ALLOC_HARDER)
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (!page) {
page = __rmqueue(zone, order, migratetype, alloc_flags);
if (!page) {
spin_unlock_irqrestore(&zone->lock, flags);
return NULL;
}
}
__mod_zone_freepage_state(zone, -(1 << order),
get_pcppage_migratetype(page));
spin_unlock_irqrestore(&zone->lock, flags);
} while (check_new_pages(page, order));
__count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order);//统计,减少zone的free_pages数量统计,因为里面使用加法,所以这里传进负数
zone_statistics(preferred_zone, zone, 1);
return page;
}
这里根据order数值,order大于0的情况,就从伙伴系统中分配。
- 分配的页面数为1,那么就不需要从buddy系统中获取,因为per-cpu的页缓存提供了一种更快分配和释放的机制。在伙伴系统中每个CPU都对应高速缓存,里面保持着migratetype分类的单页框的双向链表,当申请内存只需要一个页框时,内核从CPU的高速缓存中相应类型的单页框链表中获取一个页框交给申请者,这样好处是,释放单个页框时会放入CPU高速缓存链表,这样的页框就称为热页。
- 需要多个页框,从伙伴系统中分配,如果分配标志位中设置了ALLOC_HARDER,则从free_list[MIGRATE_HIGHATOMIC]的链表中进行页面分配,分配成功则返回;前两个条件都不满足,则在正常的free_list[MIGRATE_*]中进行分配,分配成功则直接则返回。
内核经常请求和释放单个页框,为了提升系统性能,每个内存管理区定义了一个"每CPUI"页框的高速缓存,所有“每CPU”高速缓存包含了一些预先分配的页框,它们被用于满足本地CPU发出的单一内存请求。
为每个内存管理区和每CPU提供两个高速缓存,在内存管理区中,分配单页使用per-cpu机制,分配多页使用伙伴算法
- 热高速缓存,它存放页框中所包含的内容很可能就在CPU硬件高速缓存中。
- 冷高速缓存。
- zone结构体中pageset成员指向内存域per-CPU管理结构。
struct zone {
...
#ifdef CONFIG_NUMA //若定义了CONFIG_NUMA宏,pageset为二级指针,否则为数组
struct per_cpu_pageset *pageset[NR_CPUS];
#else
struct per_cpu_pageset pageset[NR_CPUS];
#endif
...
}
mm/page_alloc.c
/*
* Do the hard work of removing an element from the buddy allocator.
* Call me with the zone->lock already held.
*/
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype,
unsigned int alloc_flags)
{
struct page *page;
if (IS_ENABLED(CONFIG_CMA)) {
/*
* Balance movable allocations between regular and CMA areas by
* allocating from CMA when over half of the zone's free memory
* is in the CMA area.
*/
if (alloc_flags & ALLOC_CMA &&
zone_page_state(zone, NR_FREE_CMA_PAGES) >
zone_page_state(zone, NR_FREE_PAGES) / 2) {
page = __rmqueue_cma_fallback(zone, order);
if (page)
return page;
}
}
retry:
page = __rmqueue_smallest(zone, order, migratetype);//直接从migratetype类型的链表中获取了2的order次方个页框
if (unlikely(!page)) {// 如果page为空,没有在需要的migratetype类型中分配获得页框,
说明当前需求类型(migratetype)的页框没有空闲
if (alloc_flags & ALLOC_CMA)
page = __rmqueue_cma_fallback(zone, order);//从CMA中获取内存
if (!page && __rmqueue_fallback(zone, order, migratetype,
alloc_flags))//根据fallbacks数组从其他migratetype类型的链表中获取内存
goto retry;
}
return page;
}
根据传递的分配阶、用于获取页的内存域、迁移类型,__rmqueue_smallest扫描页的列表,直至找到适当的连续内存块。如果指定的迁移列表不能满足分配请求,就会看migratetype类型是MIGRATE_MOVABLE,就首先从CMA中分配;如果分配失败,则调用 _ _rmqueue_fallback尝试其他的迁移列表,作为应急措施。
__rmqueue_smallest本质上,由一个循环组成,按照递增顺序遍历内存域的各个特定迁移类型的空闲页列表,直至找到合适的一项为止。
mm/page_alloc.c
/*
* Go through the free lists for the given migratetype and remove
* the smallest available page from the freelists
*/
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/// 循环遍历这层之后的空闲链表
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = get_page_from_free_area(area, migratetype);
if (!page)//获取空闲链表中第一个结点所代表的连续页框
continue;
del_page_from_free_list(page, zone, current_order);//将页框从空闲链表中删除
expand(zone, page, order, current_order, migratetype);//将current_order阶的页拆分成小块并重新放到对应的链表中去
set_pcppage_migratetype(page, migratetype);//设置页框的类型与migratetype一致
trace_mm_page_alloc_zone_locked(page, order, migratetype,
pcp_allowed_order(order) &&
migratetype < MIGRATE_PCPTYPES);
return page;
}
return NULL;
}
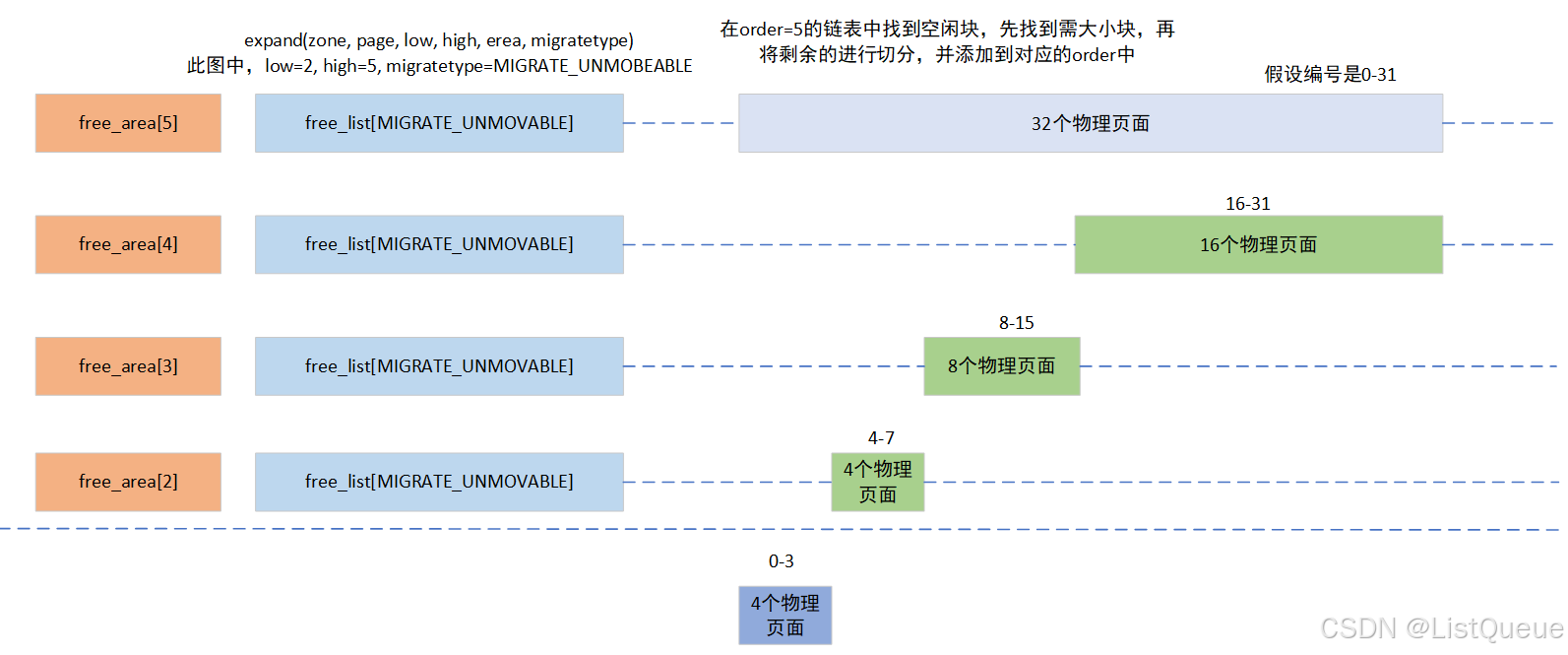
__rmqueue_smallest()函数中只会对migratetype类型的链表进行操作,并且会从需要的order值开始向上遍历,直到成功分配连续页框或者无法分配连续页框为止,比如order为8,页就是需要连续的256个页框,那么尝试从order为8的空闲页框链表中申请内存,如果失败,order就会变成9,从连续512个页框的空闲页框块链表中尝试分配,如果还是失败,就以此寻找和尝试分配…当分配到内存的order与最初的order不相等,比如最初传入的值是8,而成功分配是10,那么就会连续页框进行拆分,这时候就会拆分为256、256、512这三块连续页框,并把512放入order为9的free_list,把一个256放入order为8的free_list,剩余一个256用于分配。
如果需要分配的内存块长度小于所选择的连续页范围,即如果因为没有更小的适当内存块可用,而从较高的分配阶分配一块内存,那么该内存块必须按照伙伴系统的原理分裂成小的块,其过程主要是在expand中实现。
mm/page_alloc.c
static inline void expand(struct zone *zone, struct page *page,
int low, int high, int migratetype)
{
unsigned long size = 1 << high;
//如果high大于 low说明在需要拆分高阶页块来满足本次内存分配
while (high > low) {//循环拆分大页块直到与low一样大
high--;
size >>= 1;
VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]);
/*
* Mark as guard pages (or page), that will allow to
* merge back to allocator when buddy will be freed.
* Corresponding page table entries will not be touched,
* pages will stay not present in virtual address space
*/
if (set_page_guard(zone, &page[size], high, migratetype))
continue;
add_to_free_list(&page[size], zone, high, migratetype);
set_buddy_order(&page[size], high);//设置页块阶数
}
}
当在大的order链表中申请到了内存后,剩余部分会插入到其他的order链表中,实例如下:
 如果在特定的迁移类型列表上没有连续内存区可用,则__rmqueue_smallest返回NULL指针,说明zone的mirgratetype类型的连续页框不足以分配本次1 << order个连续页框。内核接下来根据备用次序,尝试使用其他迁移类型的列表满足分配请求,那么就会调用_ _rmqueue_fallback()进行分配,在__rmqueue_fallback()函数中,主要根据fallbacks表,尝试将其他migratetype类型的pageblock中的空闲页移动到目标类型的mirgratetype类型的空闲页框块链表中。
如果在特定的迁移类型列表上没有连续内存区可用,则__rmqueue_smallest返回NULL指针,说明zone的mirgratetype类型的连续页框不足以分配本次1 << order个连续页框。内核接下来根据备用次序,尝试使用其他迁移类型的列表满足分配请求,那么就会调用_ _rmqueue_fallback()进行分配,在__rmqueue_fallback()函数中,主要根据fallbacks表,尝试将其他migratetype类型的pageblock中的空闲页移动到目标类型的mirgratetype类型的空闲页框块链表中。
mm/page_alloc.c
static __always_inline bool
__rmqueue_fallback(struct zone *zone, int order, int start_migratetype,
unsigned int alloc_flags)
{
struct free_area *area;
int current_order;
int min_order = order;
struct page *page;
int fallback_mt;
bool can_steal;
//这是和指定迁移类型的遍历不一样,这里是从最大阶开始遍历,
找到最大可能的内存块,就是为了防止内存碎片
/*
* Do not steal pages from freelists belonging to other pageblocks
* i.e. orders < pageblock_order. If there are no local zones free,
* the zonelists will be reiterated without ALLOC_NOFRAGMENT.
*/
if (order < pageblock_order && alloc_flags & ALLOC_NOFRAGMENT)
min_order = pageblock_order;
/*
* Find the largest available free page in the other list. This roughly
* approximates finding the pageblock with the most free pages, which
* would be too costly to do exactly.
*/
for (current_order = MAX_ORDER - 1; current_order >= min_order;
--current_order) {
area = &(zone->free_area[current_order]);//得到高阶空闲数组元素
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);//检查是否有合适的fallback空闲页框
if (fallback_mt == -1)
continue;
/*
* We cannot steal all free pages from the pageblock and the
* requested migratetype is movable. In that case it's better to
* steal and split the smallest available page instead of the
* largest available page, because even if the next movable
* allocation falls back into a different pageblock than this
* one, it won't cause permanent fragmentation.
*/
if (!can_steal && start_migratetype == MIGRATE_MOVABLE
&& current_order > order)
goto find_smallest;
goto do_steal;
}
return false;
find_smallest:
for (current_order = order; current_order < MAX_ORDER;
current_order++) {
area = &(zone->free_area[current_order]);
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);//调用steal_suitable_fallback进行真正的page的迁移
if (fallback_mt != -1)
break;
}
/*
* This should not happen - we already found a suitable fallback
* when looking for the largest page.
*/
VM_BUG_ON(current_order == MAX_ORDER);
do_steal:
page = get_page_from_free_area(area, fallback_mt);
steal_suitable_fallback(zone, page, alloc_flags, start_migratetype,
can_steal);
trace_mm_page_alloc_extfrag(page, order, current_order,
start_migratetype, fallback_mt);
return true;
}
内核定义了一个二维数组来描述迁移的规则,其定义如下。
mm/page_alloc.c
/*
* This array describes the order lists are fallen back to when
* the free lists for the desirable migrate type are depleted
*
* The other migratetypes do not have fallbacks.
*/
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};
#ifdef CONFIG_CMA
static __always_inline struct page *__rmqueue_cma_fallback(struct zone *zone,
unsigned int order)
{
return __rmqueue_smallest(zone, order, MIGRATE_CMA);
}
#else
static inline struct page *__rmqueue_cma_fallback(struct zone *zone,
unsigned int order) { return NULL; }
#endif
- 不可移动的备用迁移类型优先级顺序:MIGRATE_RECLAIMABLE > MIGRATE_MOVABLE
- 可回收的备用迁移类型优先级顺序: MIGRATE_UNMOVABLE > MIGRATE_MOVABLE
- 可移动的备份迁移类型优先级顺序: MIGRATE_RECLAIMABLE > MIGRATE_UNMOVABLE
mm/page_alloc.c
int find_suitable_fallback(struct free_area *area, unsigned int order,
int migratetype, bool only_stealable, bool *can_steal)
{
int i;
int fallback_mt;
if (area->nr_free == 0)
return -1;
*can_steal = false;
for (i = 0;; i++) {
fallback_mt = fallbacks[migratetype][i];---解析1
if (fallback_mt == MIGRATE_TYPES)
break;
if (free_area_empty(area, fallback_mt))---解析2
continue;
if (can_steal_fallback(order, migratetype))---解析3
*can_steal = true;
if (!only_stealable)
return fallback_mt;
if (*can_steal)
return fallback_mt;
}
return -1;
}
此函数主要的用途是找到合适的迁移类型,其主要完成以下工作
- 1.根据当前的迁移类型获取到一个备份的迁移类型,如果迁移类型MIGRATE_TYPES,则break
- 2.如果当前的迁移类型的freelist的链表为空,说明备份的迁移类型没有可用的页,则去下一级获取页
- 3.can_steal_fallback来判断此迁移类型释放可以作为备用迁移类型,如果则返回true
static void steal_suitable_fallback(struct zone *zone, struct page *page,
int start_type)
{
unsigned int current_order = page_order(page);
int pages;
/* Take ownership for orders >= pageblock_order */
if (current_order >= pageblock_order) {//如果选定的页块大于pageblock_order,就改变整页块的迁移类型
change_pageblock_range(page, current_order, start_type);
return;
}
//统计页块在伙伴系统中的页和不在伙伴系统中并且类型为MOVABLE的页数量并且删除在伙伴系统中的页
pages = move_freepages_block(zone, page, start_type);
/* Claim the whole block if over half of it is free */
if (pages >= (1 << (pageblock_order-1)) ||
page_group_by_mobility_disabled)
set_pageblock_migratetype(page, start_type);//通过修改页块在zone-> pageblock_flags中对应bit来修改页块的迁移类型
}
到此,对于当申请一个page的时候,去对应order的freelist的迁移类型链表中找对应的page,如果没有找到对应的page,则就会去对应类型的备用类型的freelist去获取page,将此page挂载到之前需要申请的freelsit中,然后进行retry再通过__rmqueue_smallest申请一次即可。
四、Alloc slowpath
当前面快速分配内存没有成功,就会通过各种途径尝试分配所需的内存,对于慢速分配,里面涉及的流程太过于复杂,涉及到的内存压缩(同步和异步)、直接内存回收和kswapd线程唤醒,后续分析。
1. 快速分配失败后的慢速分配
在Linux内核中,当快速分配内存失败时,内核会进行一系列的慢速内存分配操作。这些操作的目标是通过各种方式回收和重新分配内存,以满足进程的内存需求。慢速分配主要包括以下几个步骤:
- 内存回收:系统尝试通过回收内存来释放空间,进行内存压缩,或者通过触发
kswapd线程来进行交换。 - 同步与异步内存回收:不同的内存回收方式会影响性能,具体做法是通过同步回收或异步回收来处理不同的内存压力情况。
2. 内存压缩(同步与异步)
内存压缩(例如 Zswap 和 Zswap)是一种在内存不足时减少内存占用的技术,特别是针对内存中的交换空间进行压缩,以减少内存的物理占用。
-
同步内存压缩:当内存分配失败时,系统会立即尝试压缩内存内容,减少占用的内存空间。这是一个同步操作,意味着在内存压力过大时,操作系统会尽量通过减少内存使用来避免交换操作或杀死进程。
-
异步内存压缩:如果系统内存压力较低或者内存负载较轻时,内核会异步进行内存压缩工作。在这种情况下,内核不会立即响应内存请求,而是以后台方式进行内存压缩,并将压缩后的数据存储到交换设备中。
3. 直接内存回收(Direct reclaim)
直接内存回收(Direct Reclaim)是内核在分配内存失败时的一项机制。当内存分配无法通过正常路径进行时,系统会通过直接回收内存来释放空闲页面。这个过程通常是同步的,意味着内核必须等待直到内存回收完成才会继续其他操作。
直接内存回收的流程大致如下:
- 触发回收:当内存分配请求失败时,内核会尝试回收不再使用的页面。这些页面可能来自空闲的内存块,或者是由正在运行的进程的虚拟内存页面。
- 回收页面:内核会通过一系列策略,选择某些页面进行回收。这包括淘汰页面(如被映射到磁盘的页面)或者回收被缓冲区缓存占用的页面。
- 回收过程中阻塞:在内存压力较大时,内核可能会发生阻塞,等待直到内存被回收并释放。
直接回收可能会导致进程的延迟,特别是在内存极度不足的情况下,系统需要花费较多时间来执行回收操作。
4. kswapd线程与内存回收
在Linux中,kswapd是一个负责内存回收的后台线程,用于确保系统内存足够,并在必要时执行内存的交换操作(swapping)。当系统内存不足时,kswapd会被唤醒,执行内存交换操作,将一部分内存页写入交换空间,以释放内存。
-
kswapd线程唤醒:当内存分配失败,并且系统无法通过其他方式满足内存请求时,
kswapd线程会被唤醒。它会尝试通过将一些内存页写入交换空间来回收内存。通常,这个过程会优先回收那些不经常使用的页面或缓存页面。 -
内存交换:
kswapd会通过交换空间(swap space)来释放内存。交换空间通常是在磁盘上预先划分的区域,存放不常用的内存数据。通过将页面从内存写入交换空间,系统可以释放出物理内存供其他进程使用。 -
内存压力与优先级:
kswapd的工作通常会在系统内存压力较大的情况下进行,内核会根据内存的优先级来决定回收哪些页面。如果内存压力过高,kswapd会在短时间内执行更多的交换操作。内核会根据不同内存区的压力来决定哪些页面应该被交换出去。
5. 与内存分配的关系
-
内存分配的优先级:内存分配过程中,内核首先会尝试快速分配,例如通过伙伴系统分配内存。如果内存不足,会触发慢速分配,包括内存回收、交换、压缩等一系列机制。
-
内存回收与内存占用:内存回收机制的目标是最大化可用内存。通过kswapd线程的唤醒和内存压缩机制,内核能够在内存压力大的情况下尽量避免系统崩溃或进程被终止。
五、总结
伙伴系统的主要目标是实现内存块的快速分配和回收,特别是在需要连续内存时。以下是伙伴系统如何分配连续页面的详细过程总结:
1. 内存区划分(Zone)与页面块的组织
首先,物理内存被分成若干个内存区(zone),常见的有:
- ZONE_DMA:适用于低端内存,通常用于 DMA(直接内存存取)操作。
- ZONE_NORMAL:用于常规的内存分配。
- ZONE_HIGHMEM:在高内存区域,通常用于内存较大的系统。
在每个内存区中,内存会被划分成大小为 2 的幂次方的块。每个块叫做一个页面(通常是 4KB),多个页面根据需要被合并成更大的块来处理。页面的大小通常为 4KB,但也可以根据体系结构的不同调整。
2. 伙伴系统的内存块管理
每个内存块的大小是 2 的幂,内核会使用一个“空闲列表”来管理这些块。这些空闲列表分为多个级别,每个级别的大小是前一级的 2 倍。例如:
- 级别 0:表示 4KB 页面。
- 级别 1:表示 8KB 块,由两个 4KB 页面组成。
- 级别 2:表示 16KB 块,由两个 8KB 块组成。
- 级别 3:表示 32KB 块,由两个 16KB 块组成。
当一个内存块被分配出去后,它就从该级别的空闲列表中删除。分配时,内核会根据请求的内存大小查找合适的内存块。
3. 请求分配连续内存页面
当系统请求分配一块连续的内存时,伙伴系统需要找到足够大的内存块。此时,内核的分配过程大致如下:
步骤一:查找空闲块
内核首先会在当前的内存区内查找一个足够大的空闲块,大小至少为请求的内存大小。如果请求的是连续的页面,系统需要确保能够分配一个足够大的块,而不是单独分配不连续的页面。
- 如果请求的内存大小小于或等于页面的大小,系统会直接查找 4KB 大小的空闲页面。
- 如果请求的内存较大,内核会检查更大的块(8KB、16KB 等),直到找到一个适合大小的块。
步骤二:合适大小的空闲块
假设请求的是连续的 8KB 内存(即两个页面),如果找到了一个空闲的 8KB 块,内核就会分配这块内存。如果找不到大小正好合适的块,系统会进行拆分操作。
- 比如,如果找到的是一个 16KB 的空闲块(由两个 8KB 块组成),内核就会将其拆分成两个 8KB 的块,其中一个会被分配出去,另一个返回空闲列表。
步骤三:分配内存并更新空闲列表
一旦找到合适的块并将其拆分,内核会将其中的一部分分配出去。然后,更新空闲块的列表,将分配出去的块从当前级别的空闲列表中删除,并将未使用的部分返回到空闲列表中。
如果请求的内存块满足连续性要求,内核会在内存中分配一块连续的物理页面,并且返回其虚拟地址给请求的进程。
4. 分配和释放的伙伴关系
伙伴系统利用“伙伴关系”来维护块的合并和拆分。当一个块被释放时,系统会检查它的“伙伴”是否也处于空闲状态。如果它的伙伴也空闲,则这两个块可以合并为一个更大的块,恢复到上一级别的空闲列表中。
释放内存时的合并过程:
- 如果两个伙伴块(位于内存的相邻区域)都为空闲状态,内核就会将它们合并成一个更大的内存块,并将其放回空闲列表中。
- 这种合并操作一直会继续,直到达到最大级别的块或者没有更多的伙伴可合并。
5. 回收内存与内存碎片
伙伴系统的一个关键优势是其能够有效减少内存碎片。通过动态合并和拆分内存块,系统能够保持内存的连续性,并减少空闲内存的碎片化现象。
然而,伙伴系统也有其限制,尤其是在处理一些小块内存时,可能会导致小内存块的碎片。因此,通常会结合其他内存分配机制(如slab分配器)来优化小块内存的分配。
、

















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









