




Linux深入理解内存管理21(基于Linux6.6)---伙伴系统启动介绍
一、概述
1、伙伴系统的基本概念
在伙伴系统中,内存被划分为固定大小的块,所有内存块的大小都是 2 的幂次方。内存分配的过程通过合并和拆分内存块来实现,两个相邻的空闲块(它们的大小是相同的)可以被合并成一个更大的块,而一个大的块也可以被拆分成两个更小的块。
伙伴(Buddy)是指一对大小相同、位于内存中相邻的位置的内存块。每个内存块的大小是 2 的幂次方,且它们的起始地址是 2 的幂次方倍数。比如,内存块大小为 32 字节,则其相邻的伙伴块可能是相距 32 字节的内存块。
2、伙伴系统的内存分配和回收
(1) 内存分配
内存分配的过程通常如下:
-
请求内存大小:当一个进程请求一定大小的内存时,操作系统会根据请求的大小找出一个合适的内存块。内存块的大小必须是 2 的幂次方,因此系统会首先将请求的大小向上取整为最接近的 2 的幂次方大小。
-
查找合适的空闲块:操作系统会查找一个足够大的空闲块,这个块的大小是 2 的幂次方,并且大小等于或大于请求的内存大小。
-
分配内存:如果找到合适的空闲块且该块大小与请求的大小相同,则直接分配该块。如果找到的块大于请求的块,操作系统会将该块拆分成两个大小相同的块,其中一个块被分配给请求,另一个块继续作为空闲块。拆分过程递归进行,直到找到合适的块大小为止。
(2) 内存回收
内存回收的过程则是将分配的内存块释放回系统,并尝试通过合并操作来减少内存碎片。回收过程如下:
-
释放内存:当一个进程释放内存时,操作系统将该内存块标记为空闲块。
-
合并伙伴:释放的内存块会与其“伙伴”块进行合并,只有在两个伙伴块都空闲时,它们才会合并成一个更大的块。合并的过程继续进行,直到无法再合并为止。合并的过程是从小块开始,逐步向大块合并。
-
合并条件:只有两个相邻的空闲块才会进行合并,而且这两个块的大小必须相等。
3、伙伴系统的内存结构
在伙伴系统中,内存通常会被划分为若干个大小不同的区域(zone),并为每个区域维护一个空闲块链表(通常是一个数组,每个数组元素代表一个不同大小的内存块)。每个数组元素又会指向一个链表,链表中保存的是所有当前大小为该元素代表大小的空闲块的起始地址。
例如:
- 0号链表 可能代表大小为 32 字节的空闲块。
- 1号链表 代表大小为 64 字节的空闲块。
- 2号链表 代表大小为 128 字节的空闲块。
这样,伙伴系统通过将这些大小相同的内存块分成一个个单独的“伙伴”,使得内存分配和回收操作既高效又简便。
众所周知,Linux内存管理的核心是伙伴系统(buddy system)。其实在linux启动的那一刻,内存管理就已经开始了,只不过不是buddy在管理。在内核中,实现物理内存管理的allocator包括:
- 连续物理内存管理buddy allocator
- 非连续物理内存管理vmalloc allocator
- 小块物理内存管理slab allocator
- 高端物理内存管理kmapper
- 初始化阶段物理内存管理memblock
在系统初始化阶段会先启用一个bootmem分配器和memblock分配器,此分配器是专门用于启动阶段的,一个bootmem分配器管理着一个node结点的所有内存,也就是在numa架构中多个node有多个bootmem,他们被链入bdata_list链表中保存。而伙伴系统的初始化就是将bootmem管理的所有物理页框释放到伙伴系统中去,如何实现bootmem到buddy的过度的整个流程。
二、mem_init
arch/arm/mm/init.c
/*
* mem_init() marks the free areas in the mem_map and tells us how much
* memory is free. This is done after various parts of the system have
* claimed their memory after the kernel image.
*/
void __init mem_init(void)
{
#ifdef CONFIG_ARM_LPAE
swiotlb_init(max_pfn > arm_dma_pfn_limit, SWIOTLB_VERBOSE);
#endif
set_max_mapnr(pfn_to_page(max_pfn) - mem_map);---解析1
/* this will put all unused low memory onto the freelists */
memblock_free_all();---解析2
#ifdef CONFIG_SA1111
/* now that our DMA memory is actually so designated, we can free it */
free_reserved_area(__va(PHYS_OFFSET), swapper_pg_dir, -1, NULL);
#endif
free_highpages();---解析3
/*
* Check boundaries twice: Some fundamental inconsistencies can
* be detected at build time already.
*/
#ifdef CONFIG_MMU
BUILD_BUG_ON(TASK_SIZE > MODULES_VADDR);
BUG_ON(TASK_SIZE > MODULES_VADDR);
#endif
#ifdef CONFIG_HIGHMEM
BUILD_BUG_ON(PKMAP_BASE + LAST_PKMAP * PAGE_SIZE > PAGE_OFFSET);
BUG_ON(PKMAP_BASE + LAST_PKMAP * PAGE_SIZE > PAGE_OFFSET);
#endif
}
- 函数set_max_mapnr()就是用于计算max_mapnr,实际指向实际物理内存大小。
- memblock_free_all函数进行释放,使其能够在伙伴系统中管理空白页。
- free_highpages将高端内存区域释放到伙伴系统,使其能管理空白页。
三、空闲内存释放
函数free_unused_memmap()和free_all_bootmem()都是把空闲内存释放到伙伴系统,前者释放memblock中空闲内存,后者释放bootmem中内存。
mm/memblock.c
/**
* memblock_free_all - release free pages to the buddy allocator
*/
void __init memblock_free_all(void)
{
unsigned long pages;
free_unused_memmap();
reset_all_zones_managed_pages();
pages = free_low_memory_core_early();
totalram_pages_add(pages);
}
mm/memblock.c
/*
* The mem_map array can get very big. Free the unused area of the memory map.
*/
static void __init free_unused_memmap(void)
{
unsigned long start, end, prev_end = 0;
int i;
if (!IS_ENABLED(CONFIG_HAVE_ARCH_PFN_VALID) ||
IS_ENABLED(CONFIG_SPARSEMEM_VMEMMAP))
return;
/*
* This relies on each bank being in address order.
* The banks are sorted previously in bootmem_init().
*/
for_each_mem_pfn_range(i, MAX_NUMNODES, &start, &end, NULL) {
#ifdef CONFIG_SPARSEMEM
/*
* Take care not to free memmap entries that don't exist
* due to SPARSEMEM sections which aren't present.
*/
start = min(start, ALIGN(prev_end, PAGES_PER_SECTION));
#endif
/*
* Align down here since many operations in VM subsystem
* presume that there are no holes in the memory map inside
* a pageblock
*/
start = pageblock_start_pfn(start);
/*
* If we had a previous bank, and there is a space
* between the current bank and the previous, free it.
*/
if (prev_end && prev_end < start)
free_memmap(prev_end, start);
/*
* Align up here since many operations in VM subsystem
* presume that there are no holes in the memory map inside
* a pageblock
*/
prev_end = pageblock_align(end);
}
#ifdef CONFIG_SPARSEMEM
if (!IS_ALIGNED(prev_end, PAGES_PER_SECTION)) {
prev_end = pageblock_align(end);
free_memmap(prev_end, ALIGN(prev_end, PAGES_PER_SECTION));
}
#endif
}
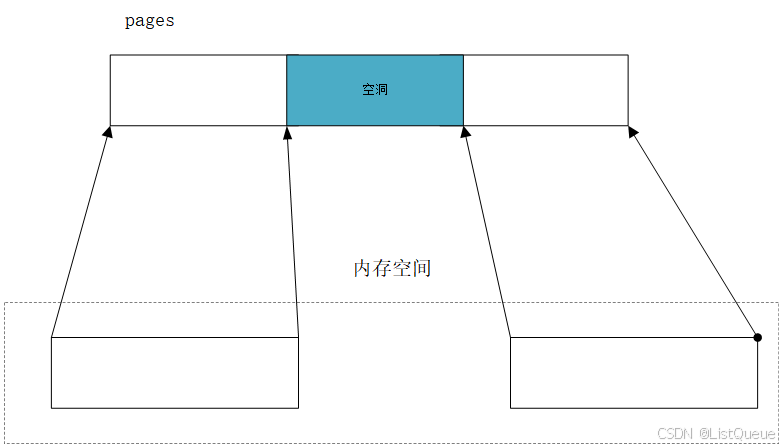
该主要是获得memblock的memory,对于IMX开发板,其reg为0x8000000,得到对应的start为0x80000,所以不满足free_memap的条件,之后拿到的prev_end为0xa0000,而对于只有一片内存,所以对于memblock中没有相对应的空闲内存释放。系统在分配内存节点的mem_map时是按照这个内存节点起始地址到末尾地址分配的,这个地址空间中可能有空洞,这个空洞地址对应的page数据结构是可以释放掉,如下图所示:
mm/memblock.c
/**
* memblock_free_all - release free pages to the buddy allocator
*/
void __init memblock_free_all(void)
{
unsigned long pages;
free_unused_memmap();
reset_all_zones_managed_pages();
pages = free_low_memory_core_early();
totalram_pages_add(pages);
}
- 设置所有node的所有zone的managed_pages为0,该函数只会启动时候调用一次
- 遍历所有需要释放的启动内存数据块,释放bdata启动内存块中所有页框到页框分配器中,计算所有的内存页数据,存储在totalram_pages中,并返回总共释放的页数量。
继续看free_low_memory_core_early,其主要的实现如下所示
mm/memblock.c
static unsigned long __init free_low_memory_core_early(void)
{
unsigned long count = 0;
phys_addr_t start, end;
u64 i;
memblock_clear_hotplug(0, -1);
memmap_init_reserved_pages();
/*
* We need to use NUMA_NO_NODE instead of NODE_DATA(0)->node_id
* because in some case like Node0 doesn't have RAM installed
* low ram will be on Node1
*/
for_each_free_mem_range(i, NUMA_NO_NODE, MEMBLOCK_NONE, &start, &end,
NULL)
count += __free_memory_core(start, end);
return count;
}
遍历memblock.reserved类型的regions,对每个regions设置页面属性为Reserved,对于Imx,这个reserved区域为:
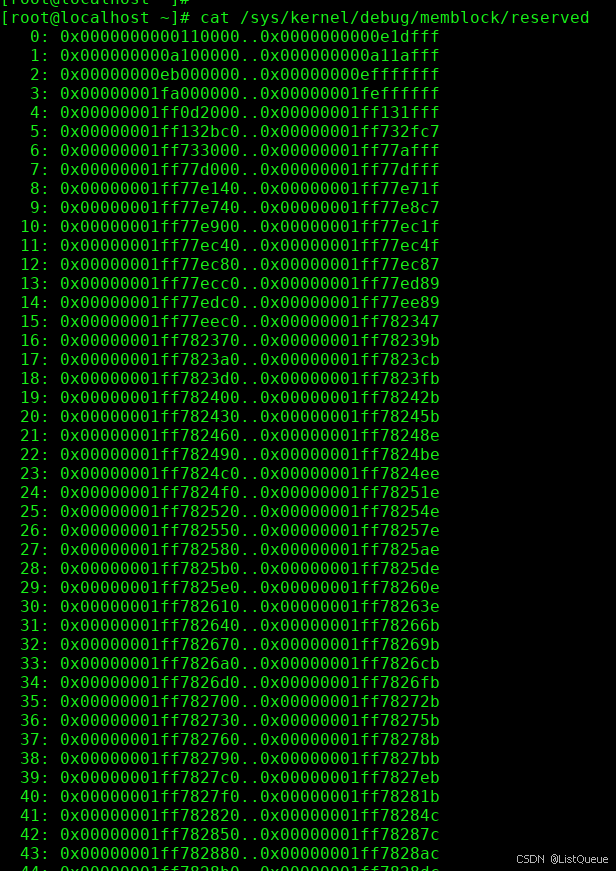
遍历所有在memblock.memory中,但是不在memblock.reserve中的regions。然后清Reserved页面属性。
下面重点看看页面是如何完成reserved的配置,其代码如下,主要是清空各页的page->flags的PG_reserved位,将reserved的区域的页标签位为PG_reserved,并加入到page->lru链表中。
mm/page_alloc.c
void __meminit reserve_bootmem_region(phys_addr_t start, phys_addr_t end)
{
unsigned long start_pfn = PFN_DOWN(start);
unsigned long end_pfn = PFN_UP(end);
for (; start_pfn < end_pfn; start_pfn++) {
if (pfn_valid(start_pfn)) {
struct page *page = pfn_to_page(start_pfn);
init_reserved_page(start_pfn);
/* Avoid false-positive PageTail() */
INIT_LIST_HEAD(&page->lru);
/*
* no need for atomic set_bit because the struct
* page is not visible yet so nobody should
* access it yet.
*/
__SetPageReserved(page);
}
}
}
看看重点的__free_memory_core,其主要是遍历所有在memblock.memory中,但是不在memblock.reserve中的regions,其信息如下
mm/memblock.c
static unsigned long __init __free_memory_core(phys_addr_t start,
phys_addr_t end)
{
unsigned long start_pfn = PFN_UP(start);
unsigned long end_pfn = min_t(unsigned long,
PFN_DOWN(end), max_low_pfn);
if (start_pfn >= end_pfn)
return 0;
__free_pages_memory(start_pfn, end_pfn);
return end_pfn - start_pfn;
}
核心的__free_pages_memory函数,该函数以顺序为单位释放页,清空各页的PG_reserved位,设置pgae->count为0后,然后调用__free_pages,代码实现为:
mm/memblock.c
static void __init __free_pages_memory(unsigned long start, unsigned long end)
{
int order;
while (start < end) {
order = min(MAX_ORDER - 1UL, __ffs(start));
while (start + (1UL << order) > end)
order--;
memblock_free_pages(pfn_to_page(start), start, order);
start += (1UL << order);
}
}
mm/page_alloc.c
void __init memblock_free_pages(struct page *page, unsigned long pfn,
unsigned int order)
{
if (early_page_uninitialised(pfn))
return;
if (!kmsan_memblock_free_pages(page, order)) {
/* KMSAN will take care of these pages. */
return;
}
__free_pages_core(page, order);
}
- 释放1页时调用free_hot_cold_page。
四、高端内存释放
static void __init free_highpages(void)
{
#ifdef CONFIG_HIGHMEM
unsigned long max_low = max_low_pfn;
phys_addr_t range_start, range_end;
u64 i;
/* set highmem page free */
for_each_free_mem_range(i, NUMA_NO_NODE, MEMBLOCK_NONE,
&range_start, &range_end, NULL) {
unsigned long start = PFN_UP(range_start);
unsigned long end = PFN_DOWN(range_end);
/* Ignore complete lowmem entries */
if (end <= max_low)
continue;
/* Truncate partial highmem entries */
if (start < max_low)
start = max_low;
for (; start < end; start++)
free_highmem_page(pfn_to_page(start));
}
#endif
}
存在高端内存时,该代码求出高端内存的起始页帧和尾页帧,然后调用free_area_high函数使伙伴系统管理空白页,free_area_high函数在内部调用__free_page函数,将空白页和一般内存区域共同释放到伙伴系统。
五、总结
mem_init()函数结束启动时的内存分配器memblock和bootmem,将bootmem和memblock管理的空白页以顺序单位构建列表,构建好的伙伴系统将为Linux的内存分配器slab提供空白页。
-
初始化
memblock和bootmem:- 在 Linux 内核启动的早期阶段,
memblock用来记录物理内存区域,bootmem用来为内核提供初步的内存分配。 memblock是在内核引导期间使用的内存管理工具,通常用于初始化阶段。当系统开始启动时,memblock会扫描内存并标记哪些区域是可用的。
- 在 Linux 内核启动的早期阶段,
-
构建伙伴系统:
mem_init()会根据memblock和bootmem管理的内存块,按照伙伴系统的策略组织空闲页。- 系统会将这些空闲内存页按照 2 的幂次方块大小进行组织,每个空闲块的大小都是 2 的幂次方,这样可以方便地进行合并和拆分操作。
memblock管理的内存区域会通过伙伴系统将空闲块连接起来,形成内存页的链表。
-
为
slab分配器提供内存:- 在
mem_init()结束时,内核的内存分配器已经初步完成了初始化工作。接下来的任务是为slab分配器准备足够的内存空间。 slab分配器是内核中用于高效分配对象的内存管理器,它将从伙伴系统中获取空闲的内存块,并通过它来进行内存的管理。- 这样,当
mem_init()完成后,Linux 内核的内存分配系统(包括伙伴系统和slab分配器)就能够高效地分配和管理内存。
- 在

















 3213
3213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









