




Linux深入理解内存管理12(基于Linux6.6)---页表准备介绍
一、概述
Linux是为通用的操作系统而设计,为了便于移植需要抽象出一些硬件细节,在驱动代码中看到大量的抽象层的思想。内核中只有和硬件相关的代码才会单独实现,这样做便于移植和添加新硬件。
内核里所有进程和内核线程都共享1GB的地址空间,而每个应用程序对应的进程都有独立的3GB的地址空间,相互不干扰。
- 用户空间:在Linux中,每个用户进程都可以访问4GB的线性地址空间,从0到3GB的虚拟地址空间是用户空间,每个用户进程通过自己的页目录,页表来直接访问
- 内核空间:从3GB到4GB的虚拟地址为内核空间,存放内核访问的代码和数据,用户进程不能访问,只有内核态进程才能访问。所有进程(包括用户进程,用户线程,内核线程)从3GB到4GB的虚拟地址空间内容都是一样的,Linux用该方式让内核进程共享代码段和数据段。
由于虚拟机制的引入,进程可以使用32位地址系统支持全部4G线性空间,进程的线性地址空间分为两部分:
- 从0x00000000到0xbfffffff的线性地址,无论用户态还是内核态的进程都可以寻址
- 从0xc0000000到0xffffffff的线性地址,只有内核态的进程能寻址
通过内核临时页表的创建,相应的页表项已经建立号,只映射Kernel Image和DTB的物理内存,在某个还是的时候,内核需要将尽可能多的物理内存映射到页表中。尽管物理内存已经通过memblock_add添加进系统,但是这部分的物理内存到虚拟内存的映射还没有建立,可以通过memblock_alloc分配一段物理内存,但是还不能访问,一切还需要等待paging_init的执行。最终页表建立好后,可以通过虚拟地址去访问最终的物理地址了。
paging_init()负责建立仅用于kernel而用户空间不可访问的页表,主要来看看其做了些什么?
arch/arm/mm/mmu.c
/*
* paging_init() sets up the page tables, initialises the zone memory
* maps, and sets up the zero page, bad page and bad page tables.
*/
void __init paging_init(const struct machine_desc *mdesc)
{
void *zero_page;
pr_debug("physical kernel sections: 0x%08llx-0x%08llx\n",
kernel_sec_start, kernel_sec_end);
prepare_page_table();---解析1
map_lowmem();---解析2
memblock_set_current_limit(arm_lowmem_limit);---解析3
pr_debug("lowmem limit is %08llx\n", (long long)arm_lowmem_limit);
/*
* After this point early_alloc(), i.e. the memblock allocator, can
* be used
*/
map_kernel();---解析4
dma_contiguous_remap();---解析5
early_fixmap_shutdown();---解析6
devicemaps_init(mdesc);---解析7
kmap_init();---解析8
tcm_init();
top_pmd = pmd_off_k(0xffff0000);
/* allocate the zero page. */
zero_page = early_alloc(PAGE_SIZE);
bootmem_init();---解析9
empty_zero_page = virt_to_page(zero_page);
__flush_dcache_page(NULL, empty_zero_page);---解析10
}
- 准备页表,主要是清除段映射(16K一级页表),将对应于内核映像下方以及内核空间的页目录项pmd段均清空为0。
-
map_lowmem主要用于管理低内存区域的映射,特别是在不同的体系结构上,内核如何处理这些低内存区域。 - 真正创建页表,重新建立从物理地址起始点到high_mem的起始点的一一映射。
- 根据arm_lowmem_limit来作为ZONE_NORMAL的终点。
- 建立DMA映射表。
- 为设备IO空间和中断向量表创建页表,并刷新TLB和缓存。
- 进行永久内存映射的初始化,存储在pkmap_page_table中,高64K是用来存放中断向量表。
- TCM初始化,TCM是一个固定大小的RAM,紧密地耦合至处理器内核,提供与cache相当的性能,相比于cache的优点是,程序代码可以精确地控制什么函数和代码放在哪里。
- bootmem_init初始化内存管理。
- 分配一个0页,该页用于写时复制机制。zero_page是全局变量,刷新D-CAHCE内容进RAM中。empty_zero_page是一个全局的页面数组,主要作用就是只要用户引用一个只读的匿名页面并没有进行写操作,缺页中断处理中内核就不会给用户进程分配新的页面。
二、设置内存类型表
在build_mem_type_table函数中,根据ARM版本及内存类型,对struct mem_type结构体类型的全局数组mem_type进行初始化。mem_types结构体数组是具有L1、L2列表和缓存策略、域属性信息的内核数据结构。
为了按内存类型使用虚拟地址空间,Linux对内核使用的内存进行了分类,内核定义在arch/arm/include/asm/io.h中,其类型如下:
/*
* Architecture ioremap implementation.
*/
#define MT_DEVICE 0
#define MT_DEVICE_NONSHARED 1
#define MT_DEVICE_CACHED 2
#define MT_DEVICE_WC 3
根据内存使用的不同目的,内存类型对是否使用缓存,是否使用写缓冲,是否共享,域等信息定义了不同的设置,这里面只是列了部分。
三、准备页表
在内核使用内存之前,需要初始化内核的页表,初始化页表主要在map_lowmem()函数中。在映射页表之前,需要把页表的页表项清零,主要在prepare_page_table()函数中实现。
arch/arm/mm/mmu.c
static __init void prepare_page_table(void)
{
unsigned long addr;
phys_addr_t end;
/*
* Clear out all the mappings below the kernel image.
*/
#ifdef CONFIG_KASAN
/*
* KASan's shadow memory inserts itself between the TASK_SIZE
* and MODULES_VADDR. Do not clear the KASan shadow memory mappings.
*/
for (addr = 0; addr < KASAN_SHADOW_START; addr += PMD_SIZE)---解析1
pmd_clear(pmd_off_k(addr));
/*
* Skip over the KASan shadow area. KASAN_SHADOW_END is sometimes
* equal to MODULES_VADDR and then we exit the pmd clearing. If we
* are using a thumb-compiled kernel, there there will be 8MB more
* to clear as KASan always offset to 16 MB below MODULES_VADDR.
*/
for (addr = KASAN_SHADOW_END; addr < MODULES_VADDR; addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr));
#else
for (addr = 0; addr < MODULES_VADDR; addr += PMD_SIZE)---解析2
pmd_clear(pmd_off_k(addr));
#endif
#ifdef CONFIG_XIP_KERNEL
/* The XIP kernel is mapped in the module area -- skip over it */
addr = ((unsigned long)_exiprom + PMD_SIZE - 1) & PMD_MASK;
#endif
for ( ; addr < PAGE_OFFSET; addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr));
/*
* Find the end of the first block of lowmem.
*/
end = memblock.memory.regions[0].base + memblock.memory.regions[0].size;
if (end >= arm_lowmem_limit)
end = arm_lowmem_limit;
/*
* Clear out all the kernel space mappings, except for the first
* memory bank, up to the vmalloc region.
*/
for (addr = __phys_to_virt(end);---解析3
addr < VMALLOC_START; addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr));
}
1、模块加载的范围应该是在MODULES_VADDR到MODULES_END之间,而MODULES_VADDR在文件arch/arm/include/asm/memory.h定义#define MODULES_VADDR (CONFIG_PAGE_OFFSET - SZ_8M),则该函数pmd_clear清理0~MODULES_VADDR所对应的一级页表项内容,所对应的地址为0x0 ~~~ bf000000。
2、对PAGE_OFFSET之前的页目录项执行初始化,PAGE_OFFSET表示内核空间的起始地址,在32位系统地址空间最多为4G,在编译的时候通过Kconfig分为内核空间和用户空间,一般比为1:3,所以内核空间的起始地址为0xc000 0000。pmd_clear清理MODULES_VADDR~ PAGE_OFFSET 所对应的一级页表项内容,所对应的地址为 bf000000 ~~~ c0000000。
- 通过下面的方式配置
- config PAGE_OFFSET
- hex
- default PHYS_OFFSET if !MMU
- default 0x40000000 if VMSPLIT_1G
- default 0x80000000 if VMSPLIT_2G
- default 0xB0000000 if VMSPLIT_3G_OPT
- default 0xC0000000
3、pmd_clear清理第一个0xe0000000~0xe0800000所对应对应的8M空间的一级页表项内容。
该函数是在建立完整页表前,需要对一级页目录进行清空操作,便于建立页表时,对空页表目录项进行分配。我们以imx6上模拟器为例,第一块也是唯一一块Membank是0x80000000起始地址,大小为512MB,arm_lowmem_limit也是0xa0000000。
为了初始化页目录项,需要获得要初始化的项地址,从上述的代码可以看出,pmd_clear函数将pmd_off_k函数作为输入值。正是通过pmd_off_k函数获得项地址。
include/linux/pgtable.h
static inline pmd_t *pmd_off_k(unsigned long va)
{
return pmd_offset(pud_offset(p4d_offset(pgd_offset_k(va), va), va), va);
}
#define pgd_offset_k(address) pgd_offset(&init_mm, (address))
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr))
/* to find an entry in a page-table-directory */
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT)
pdg_offset_k调用pgd_offset函数,传递的参数init_mm地址,pgd_index将输入地址addr以PGDIR_SHIFT的大小向右移动,因此会求出对应于输入地址的页目录项号,并通过pdg_offset获得管理ADDR所属内存块的页目录的相应项地址。
Init_mm根据INIT_MM进行初始化,其定义如下:
mm/init-mm.c
/*
* For dynamically allocated mm_structs, there is a dynamically sized cpumask
* at the end of the structure, the size of which depends on the maximum CPU
* number the system can see. That way we allocate only as much memory for
* mm_cpumask() as needed for the hundreds, or thousands of processes that
* a system typically runs.
*
* Since there is only one init_mm in the entire system, keep it simple
* and size this cpu_bitmask to NR_CPUS.
*/
struct mm_struct init_mm = {
.mm_mt = MTREE_INIT_EXT(mm_mt, MM_MT_FLAGS, init_mm.mmap_lock),
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.write_protect_seq = SEQCNT_ZERO(init_mm.write_protect_seq),
MMAP_LOCK_INITIALIZER(init_mm)
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.arg_lock = __SPIN_LOCK_UNLOCKED(init_mm.arg_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
.cpu_bitmap = CPU_BITS_NONE,
#ifdef CONFIG_IOMMU_SVA
.pasid = INVALID_IOASID,
#endif
INIT_MM_CONTEXT(init_mm)
};

接着看以下pmd_clear函数 .
arch/arm/include/asm/pgtable-2level.h
#define pmd_clear(pmdp) \
do { \
pmdp[0] = __pmd(0); \
pmdp[1] = __pmd(0); \
clean_pmd_entry(pmdp); \
} while (0)
传递给pmd_clear的参数pmdp为2M单位,并且将pmdp分为2个,并初始化为0,之后变更了页目录值,因此调用clean_pmd_entry函数。
arch/arm/include/asm/tlbflush.h
static inline void clean_pmd_entry(void *pmd)
{
const unsigned int __tlb_flag = __cpu_tlb_flags;
tlb_op(TLB_DCLEAN, "c7, c10, 1 @ flush_pmd", pmd);
tlb_l2_op(TLB_L2CLEAN_FR, "c15, c9, 1 @ L2 flush_pmd", pmd);
}
在代码中清空对应于虚拟地址pmd的MMU数据缓存,总而言之,prepare_page_table函数的作用是将页目录项的pmd段初始化为0,其对应的关系如下图所示:
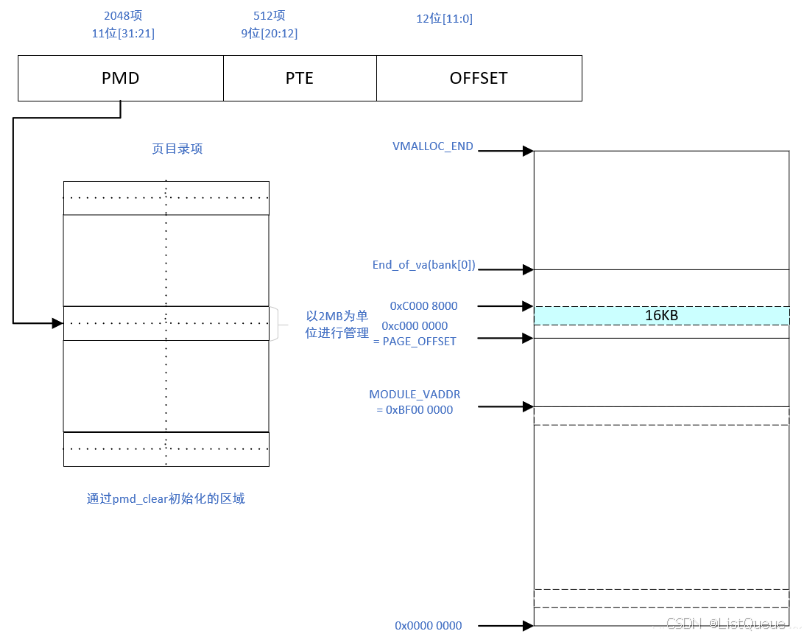
那么从图中可以看出prepare_page_table完成了以下的工作:
- 对虚拟地址0到MODULES_VADDR(0xc0000000以下8MB或16MB的地址)的一级页目录项进行清空。
- 对MODULES_VADDR到PAGE_OFFSET(0xc0000000)的一级页目录项进行清空。
- 对lowmem顶端到VMALLOC_START的一级页目录项进行清空。
四、总结
在 Linux 内核启动过程中,页表的准备通常包括以下几个步骤:
1. 引导阶段(Bootstrapping)
在 Linux 启动初期,CPU 通常处于实模式或其他早期模式下。此时,内核不具备虚拟内存的支持,因此内存映射是通过物理地址来完成的。
-
进入保护模式/64位模式:在 32 位或 64 位架构下,内核会将 CPU 切换到保护模式或 64 位模式,启用分页机制(paging),使得内核可以使用虚拟内存。这个过程通常发生在内核启动的初期阶段。
-
初始化页表:在此阶段,内核会使用一个简单的页表映射,确保能够访问系统的核心内存区域。通常,内核会使用物理地址映射,即在物理地址和虚拟地址之间建立一对一的映射。
2. 内核初始化(Memory Management Initialization)
当内核进入到初始化阶段时,它会进一步设置复杂的页表结构,以支持虚拟内存和内存管理。
-
分页启用:在 x86 系统上,通常在启动时会启用分页机制,并使用简化的页表映射。这时,内核会创建一个初步的页表,将低内存(低 1MB)区域直接映射到内核虚拟地址空间。具体的操作包括设置页目录和页表项,确保内核的虚拟地址空间能够映射到物理内存。
-
内核页表的建立:Linux 内核会为整个系统创建多个页表。在内核启动时,主要会建立两个页表:
- 内核页表:负责映射内核的虚拟地址空间。内核页表的建立会确保内核的代码、数据以及其它重要内存区域的地址映射到正确的物理地址。
- 进程页表:负责映射用户空间的虚拟地址到物理内存。每个进程启动时,都会为其分配一个独立的页表,确保不同进程的内存空间互不干扰。
3. 分页机制和页表的层次结构
现代操作系统通常使用多级页表(如 2 级或 4 级页表),以支持更大的虚拟地址空间。在 64 位 Linux 系统中,页表结构通常由以下几个级别组成:
- 页全局目录(PGD):位于页表的最上层,负责指向下一级的页表(如 PUD、PMD)。
- 页上级目录(PUD):在某些架构中,这一层提供更大的内存映射,指向页表目录。
- 页中间目录(PMD):用于指向更小的页表。
- 页表项(PTE):最终指向具体的物理内存页。
在 32 位系统中,可能只有 2 级页表:页目录和页表。页目录项指向页表,每个页表项指向物理内存页。
4. 内核的虚拟地址映射
内核会设置一些固定的虚拟地址空间区域,例如:
- 内核代码段和数据段:在虚拟内存空间中,内核代码和数据段通常从某个特定的虚拟地址开始。
- 高端内存(High Memory):对于某些架构,内核通过分页机制映射高端内存区域。
- I/O 映射区域:有些特殊的内存区域用于直接与硬件设备交互。
5. 切换到正常的分页模式
在内核初始化过程中,Linux 会逐步将页表从简化模式切换到完整的分页模式。此时,内核不再依赖直接的物理内存访问,而是完全通过虚拟内存系统进行管理。
6. 页表的维护和切换
一旦内核的虚拟内存系统完全启动并切换到分页模式后,页表的维护和切换将进入常规状态:
- 上下文切换:每当内核切换进程时,CPU 会切换页表。操作系统会加载目标进程的页表,这样进程就可以在其自己的虚拟地址空间内执行。
- 内存管理:内核继续根据需要进行内存分配、页面置换、内存映射和保护等操作。

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









