




Linux同步互斥7(基于Linux6.6)---RCU
一、概述
RCU(Read-Copy-Update)是一种用于高并发环境下的同步机制,广泛应用于 Linux 内核中。它设计的核心思想是使得读取操作无需加锁,从而极大提高读取操作的效率,同时确保在多线程环境中对共享数据的安全性。RCU 主要适用于读多写少的场景,尤其是在需要频繁读取数据并且较少修改数据的情况下。
RCU 通过允许并发读取数据而不需要加锁,减少了锁竞争,提高了系统的吞吐量。在修改数据时,RCU 会通过复制和延迟更新的方式,保证对数据的修改不会影响正在进行的读取操作。
二、为何有RCU这种同步机制呢?
RCU(Read-Copy-Update)这种同步机制的出现,主要是为了在高并发环境下提高读操作的效率,同时保持数据一致性和系统的性能。它特别适用于那些“读多写少”的场景,减少了传统锁机制在并发访问时的性能瓶颈。为了更清楚地理解为什么需要 RCPU,可以从以下几个方面来探讨。
1. 锁带来的性能瓶颈
在多线程或多核处理器的系统中,读写共享数据的同步问题通常通过加锁机制来解决。常见的锁机制有互斥锁(mutex)、读写锁(rwlock)等,它们通过显式的锁和解锁操作来保证数据一致性。但加锁也会带来以下问题:
- 写锁导致的性能瓶颈:当一个线程获取写锁时,其他线程必须等待直到写操作完成,才能进行读或写操作。在高并发场景下,这会导致大量的线程阻塞,影响系统的吞吐量和响应时间。
- 锁竞争:多个线程在同一数据上进行读写操作时,可能会产生锁竞争,导致性能下降,特别是当读操作频繁时,锁竞争尤为严重。
2. 读操作的频繁性与写操作的稀缺性
在许多应用场景中,读操作的频率远高于写操作。这种“读多写少”的场景是 RCPU 特别适合的地方。举个例子,操作系统中的进程管理、文件系统、网络协议栈等地方,大量的数据被频繁读取,但更新数据的操作较为稀少。
如果每次读取都需要加锁,效率就会受到极大影响。RCU 通过允许多线程并发地读取数据,同时将写操作通过“复制-更新”的方式推迟,使得读取操作可以无锁执行,从而大大提高了系统的并发性能。
3. 传统同步机制的限制
传统的锁机制(如互斥锁、读写锁)虽然能够解决并发访问问题,但也有它的局限性,特别是在以下几个方面:
- 阻塞问题:当一个线程持有锁时,其他线程可能被阻塞,需要等待锁的释放。这在高并发的环境下尤其影响性能。
- 锁粒度和锁竞争:锁粒度过大或过小都会导致性能问题。过大的锁粒度(例如锁住一个大的数据结构)可能会导致过多的线程等待,而过小的锁粒度(例如锁住单个元素)则可能导致锁竞争过于频繁。
RCU 通过减少对锁的依赖,使得读操作可以在没有任何锁竞争的情况下进行。这样,系统能够更高效地处理大量的并发读取请求。
4. RCU 的创新机制
RCU 通过以下创新机制解决了这些问题:
-
无锁读取:在 RCPU 中,读取操作不需要加锁,多个线程可以并发地读取同一数据,这样就消除了锁带来的性能开销。
-
延迟更新与回收:当数据需要修改时,RCU 不会直接修改原数据,而是会创建一个新的副本进行修改,然后再通过原子操作或指针交换的方式将指针指向新副本。这使得读取线程依然可以继续读取旧的数据副本,而不会受到修改操作的影响。
-
延迟回收(Grace Period):RCU 引入了“宽松期”(grace period)机制,确保所有正在读取旧数据的线程都已经完成对旧数据的访问后,才回收旧数据。这避免了在数据修改期间,读取线程访问到已经被修改的数据副本的问题。
2.1、性能问题
spin lcok、RW spin lcok和seq lock的基本原理。对于spin lock而言,临界区的保护是通过next和owner这两个共享变量进行的。线程调用spin_lock进入临界区,这里包括了三个动作:
(1)获取了自己的号码牌(也就是next值)和允许哪一个号码牌进入临界区(owner)。
(2)设定下一个进入临界区的号码牌(next++)。
(3)判断自己的号码牌是否是允许进入的那个号码牌(next == owner),如果是,进入临界区,否者spin(不断的获取owner的值,判断是否等于自己的号码牌,对于ARM64处理器而言,可以使用WFE来降低功耗)。
注意:(1)是取值,(2)是更新并写回,因此(1)和(2)必须是原子操作,中间不能插入任何的操作。
线程调用spin_unlock离开临界区,执行owner++,表示下一个线程可以进入。
RW spin lcok和seq lock都类似spin lock,它们都是基于一个memory中的共享变量(对该变量的访问是原子的)。假设系统架构如下:
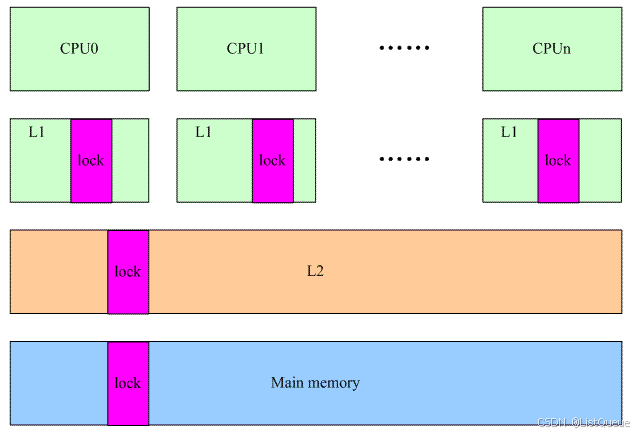
当线程在多个cpu上争抢进入临界区的时候,都会操作那个在多个cpu之间共享的数据lock。
cpu 0操作了lock,为了数据的一致性,cpu 0的操作会导致其他cpu的L1中的lock变成无效,在随后的来自其他cpu对lock的访问会导致L1 cache miss,必须从下一个level的cache中获取,同样的,其他cpu的L1 cache中的lock也被设定为invalid,从而引起下一次其他cpu上的communication cache miss。
RCU的read side不需要访问这样的“共享数据”,从而极大的提升了reader侧的性能。
2.2、reader和writer可以并发执行
spin lock是互斥的,任何时候只有一个thread(reader or writer)进入临界区,rw spin lock要好一些,允许多个reader并发执行,提高了性能。不过,reader和updater不能并发执行,RCU解除了这些限制,允许一个updater(不能多个updater进入临界区,这可以通过spinlock来保证)和多个reader并发执行。比较一下rw spin lock和RCU,参考下图:
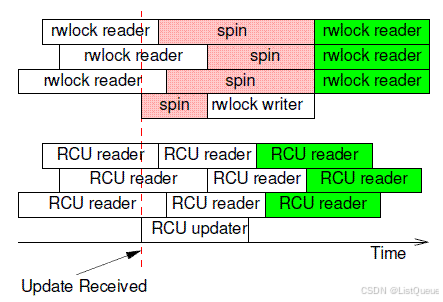
rwlock允许多个reader并发,因此,在上图中,三个rwlock reader愉快的并行执行。
当rwlock writer试图进入的时候(红色虚线),只能spin,直到所有的reader退出临界区。
一旦有rwlock writer在临界区,任何的reader都不能进入,直到writer完成数据更新,立刻临界区。绿色的reader thread们又可以进行愉快玩耍了。
rwlock的一个特点就是确定性,白色的reader一定是读取的是old data,而绿色的reader一定获取的是writer更新之后的new data。
RCU和传统的锁机制不同,当RCU updater进入临界区的时候,即便是有reader在也无所谓,它可以长驱直入,不需要spin。
同样的,即便有一个updater正在临界区里面工作,这并不能阻挡RCU reader的步伐。由此可见,RCU的并发性能要好于rwlock,特别如果考虑cpu的数目比较多的情况,那些处于spin状态的cpu在无谓的消耗,多么可惜,随着cpu的数目增加,rwlock性能不断的下降。
RCU reader和updater由于可以并发执行,因此这时候的被保护的数据有两份,一份是旧的,一份是新的,对于白色的RCU reader,其读取的数据可能是旧的,也可能是新的,和数据访问的timing相关,当然,当RCU update完成更新之后,新启动的RCU reader(绿色block)读取的一定是新的数据。
每种锁都有自己的适用的场景:spin lock不区分reader和writer,对于那些读写强度不对称的是不适合的,RW spin lcok和seq lock解决了这个问题,不过seq lock倾向writer,而RW spin lock更照顾reader。看起来一切都已经很完美了,但是,随着计算机硬件技术的发展,CPU的运算速度越来越快,相比之下,存储器件的速度发展较为滞后。
在这种背景下,获取基于counter(需要访问存储器件)的锁(例如spin lock,rwlock)的机制开销比较大。而且,目前的趋势是:CPU和存储器件之间的速度差别在逐渐扩大。因此,那些基于一个multi-processor之间的共享的counter的锁机制已经不能满足性能的需求,在这种情况下,RCU机制应运而生,它克服了其他锁机制的缺点,但是,甘蔗没有两头甜,RCU的使用场景比较受限,主要适用于下面的场景:
(1)RCU只能保护动态分配的数据结构,并且必须是通过指针访问该数据结构。
(2)受RCU保护的临界区内不能sleep(SRCU不是本文的内容)。
(3)读写不对称,对writer的性能没有特别要求,但是reader性能要求极高。
(4)reader端对新旧数据不敏感。
三、RCU的基本思路
3.1、原理
1、RCPU 的工作原理
RCU 的核心原理可以通过以下几个关键步骤来理解:
-
读取操作无需加锁:
- 读取共享数据的操作通常不需要加锁。读取者可以并发地访问数据结构,而不会受到修改者的影响。
-
更新操作通过复制进行:
- 写操作通常不会直接修改原数据。相反,更新操作会创建一个数据的副本,然后修改副本。
-
延迟回收机制:
- 当写操作完成并发布新的数据副本后,旧的数据副本不会立即被回收。系统会延迟一定时间,直到所有读取操作都确认不再访问旧的数据副本。只有在确认没有正在访问旧数据时,系统才会回收旧副本。
2、RCU 的基本流程
-
读取数据:
- 读取者(读线程)可以无锁地访问数据,因为它们访问的是一个不受写操作影响的版本。
-
更新数据:
- 写操作首先创建一个新副本,然后将指针从旧副本切换到新副本。切换操作使用了某种形式的同步机制(例如原子操作)来保证操作的原子性。
-
删除旧副本:
- 旧副本在切换后不会立即被回收。RCU 使用回收延迟机制来确保在读线程完成对旧副本的访问后,才能安全地释放旧副本。
3、RCU 的实现方式
RCU 的实现通常依赖于内存屏障、原子操作以及引用计数等技术来确保数据的一致性和同步。具体实现方式有很多种,主要的几种包括:
- 原子指针交换(atomic pointer swap):通过原子交换操作,确保写操作的切换操作是原子的,即使多个线程同时进行读操作。
- RCU 版本标识:RCU 使用一种版本标识的机制来确保数据的更新过程不会影响正在读取的数据副本。
- 延迟回收机制(Grace Period):RCU 会设定一个“宽松期”(Grace Period),确保所有的读取操作都完成后,才会回收旧的数据副本。
RCU的基本思路:
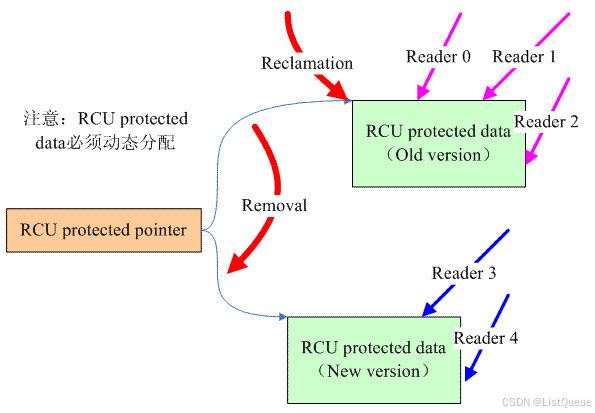
RCU涉及的数据有两种,一个是指向要保护数据的指针,称之RCU protected pointer。另外一个是通过指针访问的共享数据,我们称之RCU protected data 。
对共享数据的访问有两种,一种是writer,即对数据要进行更新,另外一种是reader。如果在有reader在临界区内进行数据访问,对于传统的,基于锁的同步机制而言,reader会阻止writer进入(例如spin lock和rw spin lock。seqlock不会这样,因此本质上seqlock也是lock-free的),因为在有reader访问共享数据的情况下,write直接修改data会破坏掉共享数据。
怎么办呢?当然是移除了reader对共享数据的访问之后,再让writer进入了(writer稍显悲剧)。
对于RCU而言,其原理是类似的,为了能够让writer进入,必须首先移除reader对共享数据的访问,怎么移除呢?创建一个新的copy是一个不错的选择。因此RCU writer的动作分成了两步:
(1)removal。write分配一个new version的共享数据进行数据更新,更新完毕后将RCU protected pointer指向新版本的数据。一旦把RCU protected pointer指向的新的数据,也就意味着将其推向前台,公布与众(reader都是通过pointer访问数据的)。通过这样的操作,原来read 0、1、2对共享数据的reference被移除了(对于新版本的受RCU保护的数据而言),它们都是在旧版本的RCU protected data上进行数据访问。
(2)reclamation。共享数据不能有两个版本,因此一定要在适当的时机去回收旧版本的数据。当然,不能太着急,不能reader线程还访问着old version的数据的时候就强行回收,这样会让reader crash的。reclamation必须发生在所有的访问旧版本数据的那些reader离开临界区之后再回收,而这段等待的时间被称为grace period。
顺便说明一下,reclamation并不需要等待read3和4,因为write端的为RCU protected pointer赋值的语句是原子的,乱入的reader线程要么看到的是旧的数据,要么是新的数据。对于read3和4,它们访问的是新的共享数据,因此不会reference旧的数据,因此reclamation不需要等待read3和4离开临界区。
3.2、基本RCU操作
对于reader,RCU的操作包括:
(1)rcu_read_lock,用来标识RCU read side临界区的开始。
(2)rcu_dereference,该接口用来获取RCU protected pointer。reader要访问RCU保护的共享数据,当然要获取RCU protected pointer,然后通过该指针进行dereference的操作。
(3)rcu_read_unlock,用来标识reader离开RCU read side临界区。
对于writer,RCU的操作包括:
(1)rcu_assign_pointer。该接口被writer用来进行removal的操作,在witer完成新版本数据分配和更新之后,调用这个接口可以让RCU protected pointer指向RCU protected data。
(2)synchronize_rcu。writer端的操作可以是同步的,也就是说,完成更新操作之后,可以调用该接口函数等待所有在旧版本数据上的reader线程离开临界区,一旦从该函数返回,说明旧的共享数据没有任何引用了,可以直接进行reclaimation的操作。
(3)call_rcu。当然,某些情况下,writer无法阻塞,这时候可以调用call_rcu接口函数,该函数仅仅是注册了callback就直接返回了,在适当的时机会调用callback函数,完成reclaimation的操作。这样的场景其实是分开removal和reclaimation的操作在两个不同的线程中:updater和reclaimer。
四、举例应用
RCU(Read-Copy-Update)是一种高效的并发数据结构同步机制,广泛应用于 Linux 内核中,尤其是在读多写少的场景下。RCU 允许多个读操作并发进行,而不需要加锁,从而大大提高了并发性能,尤其是在高频读取数据的环境中。
下面是一些具体的 RCU 应用实例,每个实例都有详细的解释:
4.1、进程调度中的 RCU
在 Linux 内核中,进程调度是一个重要的子系统,RCU 被用来管理进程调度器中的进程队列(例如运行队列、就绪队列等)。调度过程中,大多数操作是读取进程状态,而更新进程状态相对较少。
应用背景:
- 内核中的进程调度器需要频繁地读取进程队列,但这些队列的更新(例如进程切换、进程状态变化等)相对较少。
- 为了提高性能,需要避免加锁机制带来的锁竞争和上下文切换的开销。
RCU 在调度中的作用:
- 当调度器需要查看进程的状态时,使用 RCPU 机制无锁地读取进程队列中的信息。
- 更新进程状态(如进程进入阻塞、退出或被挂起)时,内核会使用 RCPU 机制进行延迟更新和回收,确保旧的数据不会立即被删除,直到所有的读取者完成操作。
代码示例(简化版):
// RCU保护的进程队列
struct task_struct *task;
rcu_read_lock(); // 开始 RCPU 读取区
task = rcu_dereference(runqueue->head); // 获取运行队列的第一个任务
rcu_read_unlock(); // 结束 RCPU 读取区
rcu_read_lock()和rcu_read_unlock()用于保护读取期间的共享数据。rcu_dereference()用来确保获取的是正确的任务指针。
在进程终止时,RCU 会将旧的进程控制块(PCB)标记为可回收,但只有在所有读取线程完成后,才会真正释放旧的 PCB。
4.2、 文件系统中的 RCU
Linux 文件系统(例如 ext4)使用 RCPU 来管理文件系统的元数据,如 inode、目录项等。文件系统中,读取文件信息的操作远远多于文件的创建或删除操作,因此非常适合使用 RCPU 来提高并发性能。
应用背景:
- 文件系统需要频繁地读取 inode 信息、目录项等文件元数据,但这些信息的更新(例如删除文件、修改权限等)较少。
- 文件系统需要保证在读取元数据时不会发生竞争,同时确保元数据更新的延迟回收。
RCU 在文件系统中的作用:
- 文件系统中的许多数据结构(如 inode 缓存、目录项等)都使用 RCPU 来允许多个进程并发读取这些元数据。
- 当文件的 inode 或目录项被修改或删除时,RCU 延迟回收这些已不再使用的数据。
代码示例:
// RCPU保护的 inode 读取
struct inode *inode;
rcu_read_lock(); // 开始 RCPU 读取区
inode = rcu_dereference(file->f_inode); // 获取文件的 inode
rcu_read_unlock(); // 结束 RCPU 读取区
在文件被删除或 inode 被更新时,RCU 会推迟旧 inode 数据的回收,直到所有正在访问它的线程都完成了对旧数据的操作。
4.3、网络协议栈中的 RCU
在 Linux 的网络协议栈中,RCU 也被用于管理大量的路由表、网络设备的状态、连接信息等。这些数据通常是频繁读取,但更新较少的。
应用背景:
- 路由表和网络接口的状态需要被频繁访问,例如每次数据包的路由决策都需要读取路由表,而修改路由表或网络接口的状态的操作相对较少。
- 为了高效地处理大量的网络请求,内核需要避免加锁操作带来的性能瓶颈。
RCU 在网络协议栈中的作用:
- 在网络协议栈中,RCU 允许多个处理器并发读取路由表、网络设备状态等信息,而无需进行加锁。
- 当路由表或网络设备状态需要更新时,RCU 会创建新的数据结构副本,更新后将指针交换为新的副本,而旧的副本会在确保没有线程在访问时被回收。
代码示例:
// RCPU保护的路由表读取
struct route_entry *entry;
rcu_read_lock(); // 开始 RCPU 读取区
entry = rcu_dereference(route_table[route_key]); // 获取路由条目
rcu_read_unlock(); // 结束 RCPU 读取区
当需要更新路由表时,RCU 会创建新的条目并交换指针,从而确保正在读取旧条目的线程不会被阻塞。
4.4、内存管理中的 RCPU
Linux 内核中的内存管理(尤其是页表管理和虚拟内存管理)也使用了 RCPU。内存页面的状态(如是否被占用、是否在交换空间中)是读多写少的典型场景。
应用背景:
- 页表的读取非常频繁,特别是当进程访问不同虚拟地址时,内核需要频繁查找页表项来确定虚拟地址是否有效。
- 页表项的更新相对较少,因此适合使用 RCPU 机制来避免频繁的加锁和提高性能。
RCU 在内存管理中的作用:
- 在内存管理中,RCU 用于管理页表项和虚拟内存区域。多个线程可以并发读取页表项,避免了加锁的性能瓶颈。
- 当页表项需要更新时,RCU 延迟更新,并确保在所有线程完成读取后才回收旧的数据。
代码示例:
// RCPU保护的页表读取
struct page *page;
rcu_read_lock(); // 开始 RCPU 读取区
page = rcu_dereference(page_table[virtual_address]); // 获取虚拟地址对应的物理页面
rcu_read_unlock(); // 结束 RCPU 读取区
4.5、 RCU 本身的实现
RCU 在内核中的实现也自成一体,涉及到 RCPU 的读取锁、写锁以及回收机制。RCU 提供了一个机制,让内核中的许多数据结构可以进行无锁读取,同时在需要更新数据时通过延迟回收机制来避免数据竞争。
RCU 基本操作:
- rcu_read_lock() 和 rcu_read_unlock():用于保护对共享数据的无锁读取操作。
- rcu_dereference():用于读取 RCPU 保护的数据,确保访问到的是最新的数据。
- call_rcu():用于在更新数据时标记旧数据可以回收,并安排回收操作。
总结:
RCU 在 Linux 内核中的应用,特别是在高并发读取操作的场景中,能够显著提升性能。它通过提供无锁的读取方式和延迟更新机制,避免了传统加锁方案的性能瓶颈。RCU 被广泛应用于 进程调度、文件系统、网络协议栈、内存管理等核心子系统,它是现代 Linux 内核高效并发控制的基础。

















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









