




 本文介绍如何通过五步计算模型的平均精度(AP值),包括下载源码、创建真实数据文件、移动图片、创建预测数据文件及运行主程序。
本文介绍如何通过五步计算模型的平均精度(AP值),包括下载源码、创建真实数据文件、移动图片、创建预测数据文件及运行主程序。
参考:https://github.com/Cartucho/mAP#create-the-predicted-objects-files
训练得到自己的神经网络模型后,需要计算AP值来验证模型的好坏,本文介绍AP值计算的方法,最后效果如图所示:
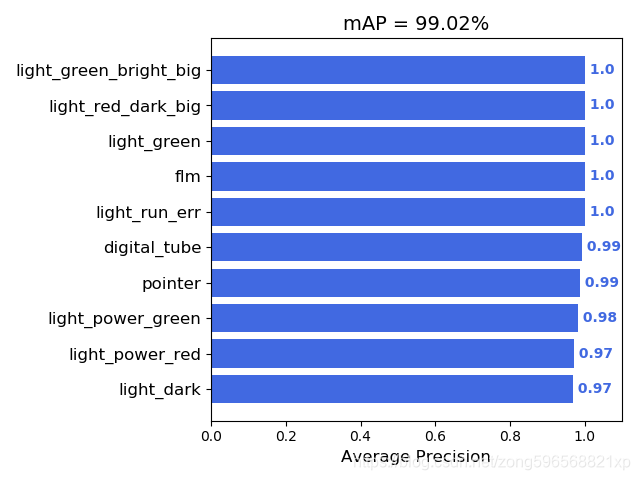
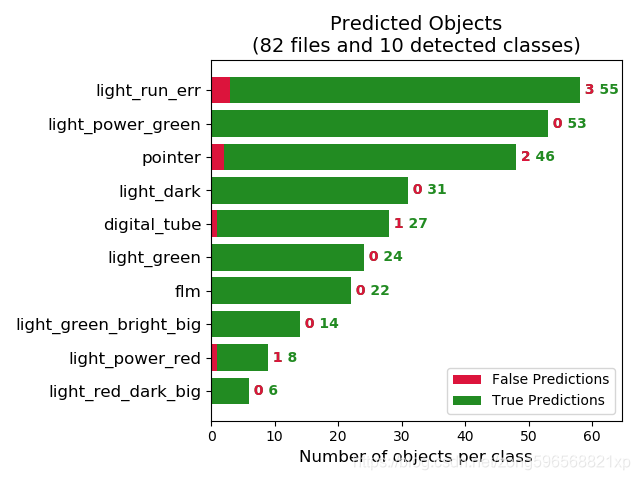
具体步骤如下:
1 下载源码
git clone https://github.com/Cartucho/mAP2 创建真实数据文件
利用labelImg标注工具生成的是*.xml标注文件,并且标注文件与图片一一对应,如有“picture1.jpg”的图片,就会有“picture1.xml”的标注文件。
在计算AP值的时候,需要将xml文件转化为txt文件,具体转化方法在extra文件夹中,运行convert_gt_xml.py文件即可完成转化
txt的数据格式如下
<class_name> <left> <top> <right> <bottom>如"image_1.txt":
tvmonitor 2 10 173 238
book 439 157 556 241
book 437 246 518 351
pottedplant 272 190 316 259将生成的文件放置在ground-truth文件夹下
3 移动图片
将对应的图片移动到images文件夹下,注意名字要与txt文件的名字一一对应
4 创建预测数据文件
将测试模型时的结果文件输出,主要要保存成新的格式,包括类别、置信度和四个坐标值,也保存成txt格式文件,保存在predicted文件夹下(注意predicted文件夹里边的文件格式与ground_truth文件夹里边的文件格式区别)
tvmonitor 0.471781 0 13 174 244
cup 0.414941 274 226 301 265
book 0.460851 429 219 528 247
bottle 0.287150 336 231 376 305
chair 0.292345 0 199 88 436我这块运行的是tensorflow/object-detection的代码,配置流程可参考之前的文章,根据推理得到的结果,采用以下的方式进行转化
#其中一张图片推理及保存结果的代码示例
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores,
detection_classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
#相关参数定义
max_boxes_to_draw = 30
min_score_thresh = .5
width = 1920
height = 1080
#如果是多种照片读一次就行
label_file = open(PATH_TO_LABELS)
label_lines = label_file.readlines()
label_file.close()
txt = open(SAVEDPATH + name + '.txt', 'w+')
for i in range(max_boxes_to_draw):
if scores[0][i] > min_score_thresh:
classes_num = int(classes[0][i])
#去除括号和多余的空格
box_clear = str(boxes[0][i]).replace('[', '').replace(']', '').replace(' ', '').replace('0.', ' 0.').replace(
'1.', ' 1.')
#print('box clear is ', box_clear)
left = str(int(float(box_clear.split(' ', 4)[1]) * height))
top = str(int(float(box_clear.split(' ', 4)[2]) * width))
right = str(int(float(box_clear.split(' ', 4)[3]) * height))
bottom = str(int(float(box_clear.split(' ', 4)[4]) * width))
box_num = top + ' ' + left + ' ' + bottom + ' ' + right
findresult = False
#根据类别序号找到对应的类别名称
for line in label_lines:
if not findresult:
try:
if classes_num == int(line.split('id:', 1)[1]):
findresult = True
except:
continue
else:
classes_name = line.split('name:', 1)[1]
classes_clear = eval(classes_name)
#print('class name is ', classes_clear)
break
#将结果保存写入
txt.write(str(classes_clear) + ' ' + str(scores[0][i]) + ' ' + box_num + '\n')
txt.close()5 运行main.py
运行主程序,即可输出所需结果文件



















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











