







 本文详细介绍如何使用Elasticsearch、Logstash、Kibana及Filebeat搭建高效日志管理系统,涵盖各组件的功能、配置及常见问题解决方案。
本文详细介绍如何使用Elasticsearch、Logstash、Kibana及Filebeat搭建高效日志管理系统,涵盖各组件的功能、配置及常见问题解决方案。
– “满地都是六便士,只有他抬头看见了月亮”
后面发现使用docker就可以直接搭建,对docker熟悉的可以直接使用docker搭建elk,个人感觉docker搭建比较快,配置也好管理。
ELK简介
E:elasticsearch,百度百科:ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
我理解的大概就是一个数据库一样,负责存在你的日志,提供了很多的web接口,查看日志的信息。
L:Logstash,一个具有实时管道功能的开源数据收集引擎,动态地将来自不同数据源的数据统一,负责日志的收集,过滤,转载。
K:Kibana,开源数据可视化和挖掘工具,可以用于日志和时间序列分析、应用程序监控和运营智能使用案例。可视化的展示elasticsearch的数据,进行分析,提供了许多可视化的功能界面。
大概流程:
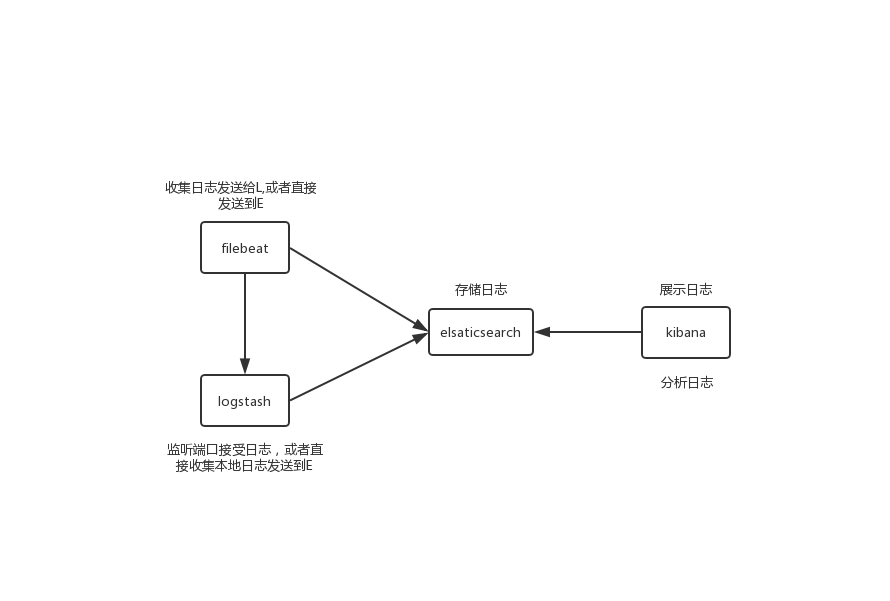
可以看见L直接就能收集本地日志到E,为什么还要使用filebeat明首先L是使用jvm跑的,会消耗很多资源。其次L300多兆,filebeat十几兆,不用多说了吧。这里面花时间最多的就是L,着实费劲。
搭建
注意:ELK,包括filebeat版本需要相同
首先你得有java环境,一般来说java8就行,java环境搭建就不用了说了,最新的7.3版本好像需要java11,所以我选的版本是7.1.0每个版本需要的java环境官方文档里面有:https://www.elastic.co/cn/support/matrix#matrix_jvm,java8应该都是可以的,只是我安装的时候出现了问题,所以换了版本(你们可以试试最新版本,不行再换回来吧)。之前搭建的时候网上说不能用root用户,结果我不用还不行,文件权限都给子用户了,运行提示权限不够,输了密码才行,那多费劲啊,运行一次输一次,然后索性直接root用户运行,目前没发现有啥问题,可能6.x的版本和7.x的不一样吧,网上说啥的都有,你们有时间可以尝试。
若会使用docker,使用docker部署非常方便,需要的可以去了解相关博客
Elasticsearch搭建:
有很多种安装方式,rpm,tar,推荐使用rpm,两者有何区别,自行百度
下载安装包到指定目录,直接下,或者wget都行,https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-1-0
下载rpm的安装包,通过xftp传到centos
rpm -ivh elasticsearch-7.1.0-x86_64.rpm
然后安装到了/usr/share目录下,配置文件在/etc/elasticsearch目录下
编辑配置文件
vim elasticsearch.yml
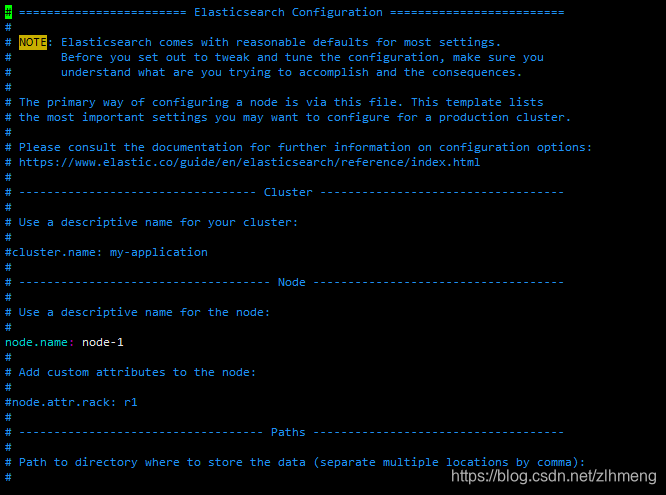
可以看见官方已经给我们分好层了,找到指定位置添加所需要的配置,你也可以直接在文本末全加上,但这是非常不好的习惯
#node下添加节点
node.name: node-1
#Network下添加地址,以及权限
#主机地址或0段,最好配0段,网上说配ip可能会出问题(能少一个坑是一个吧)
network.host: 0.0.0.0
#端口
http.port: 9200
#允许跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
#集群节点(这个不配好像也不行,姑且配上)
cluster.initial_master_nodes: ["node-1"]
还有很多配置,先配置这么多,比较别人花了很久弄的东西我才弄几天,有需要更多配置的直接去官网找,哪里是最全面的,下面的配置也一样。
然后启动
systemctl start elasticsearch
不出意外会启动失败,大概会有三个错误,不过都能解决,大概是文件大小和分配的内存问题,额,我忘了错误是啥。。你们直接复制错误去百度,就能解决。
修改完后再启动
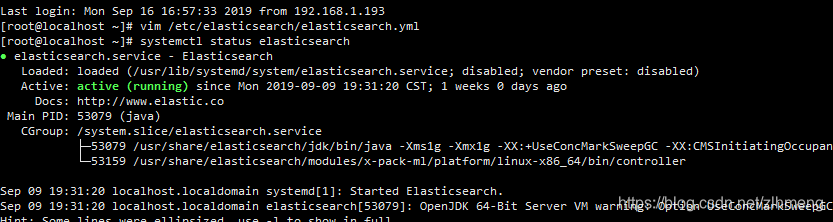
查看状态
systemctl status elasticsearch
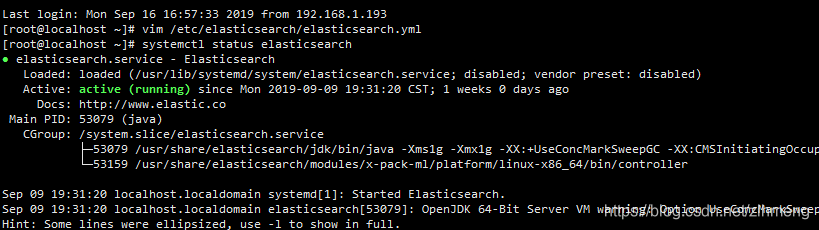
在网页上访问ip:9200能看见json数据证明elasticsearch搭建成功
附上我写的:Elasticsearch简介
Kibana搭建
同样使用下载安装包rpm安装
https://www.elastic.co/cn/downloads/past-releases/kibana-7-1-0
编辑配置文件
vim /etc/kibana/kibana.yml
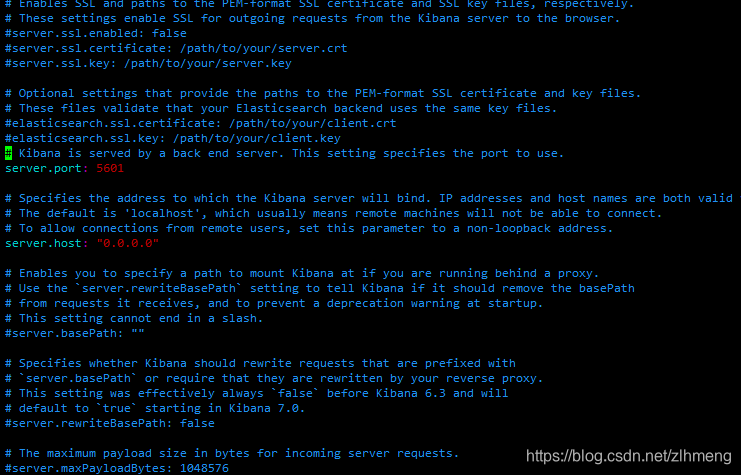
这个是分为一段一段的,他们公司会玩。一会儿分层,一会儿分段。
#端口
server.port: 5601
#地址
server.host: "0.0.0.0"
#节点名称,和E中一样
server.name: "node-1"
#E的地址
elasticsearch.hosts: ["http://192.168.1.185:9200"]
#K的索引
kibana.index: ".kibana"
#配置中文,这个随心
i18n.locale: "zh-CN"
启动:
systemctl start kibana
查看状态
在网页访问ip:5601如果没报错说明EK搭建成功。
Logstash搭建
安装不在废话,我的使用rpm安装失败,还在找原因,然后使用的tar的方式安装的。
只要版本一样rpm和tar都没问题
编辑配置文件,rpm安装在conf.d目录下新建.conf后缀的文件,tar的在config目录下新建.conf后缀文件,或使用它自带的logstash-simple.conf也可以,只需要在启动时指定配置文件即可
修改配置文件内容如下
#输入
input{
#可以配置多个file
file{
path => [xxx/xx.log]
}
}
output{
elasticsearch {
hosts => ["192.168.1.185:9200"]
#索引
index => "test-%{+YYYY.MM.dd}"
}
}
启动:
rpm 启动和上面一样,tar启动到logstash安装目录
bin/logstash -f config/logstash-sample.conf &
后台启动,刚开始建议别后台启动,直接启动可以查看日志信息,启动成功后Ctrl+c退出控制台
nohup bin/logstash -f config/logstash-sample.conf &
然后到kibana界面查看是否有索引
点击界面左边任务栏最下方的设置按钮,

点击索引管理可以对索引进行刷新,删除等一系列操作
点击索引模式你可以看见E里面的索引,点击创建索引,在输入框中输入关键字过滤自己想要的。点击下一步就ok
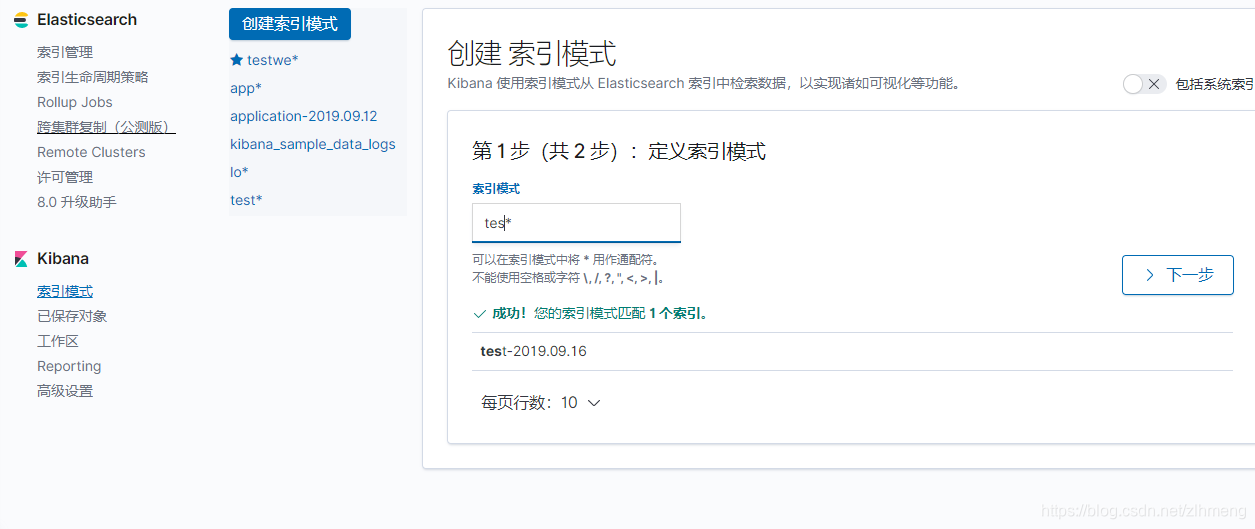
这样ELK就搭建成功了
分布式开发的时候,我们的服务往往不一定都在一台服务器上,这样我们收集本地日志,就需要在每台服务器上部署Logstash,Logstash的缺点就不用了说了,所以elastic官方出了filebeat,此外,即使在读取的过程中如果我们的E或L挂掉了,使用filebeat不会造成数据丢失,filebeat会从断掉的地方继续发送日志,所有如果不使用filebeat,建议可以和消息队列一起使用,比如kafka,RabbitMq
附上我写的:logstash详解,干货满满哦
filebeat搭建
安装不多说
修改配置文件
vim /etc/filebeat/filebeat.yml
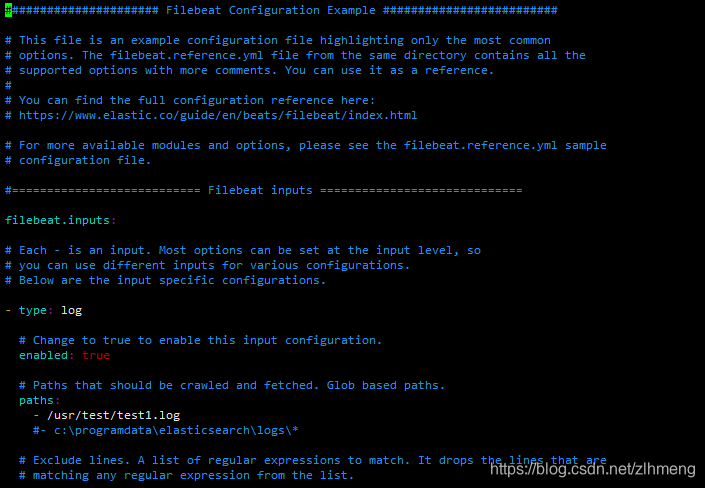
#filebeat input下添加收集的日志文件
filebeat.inputs:
#文件类型
- type: log
#启用该配置
enabled: true
#路径
paths:
- /usr/test/test1.log
#在output节点下选择输出到E还是L,都可以尝试一下,选择其中一个注释掉另外一个
output.logstash:
# The Logstash hosts
hosts: ["xxx:5044"]
其他的配置按照它原来的配置即可无需更改,如果是配置到L,则修改L的输入
input{
#logstash的内置插件,接受filebeat的日志
beats{
#表示监听5044端口,和filebeat发送来的端口一致即可
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
访问kibana
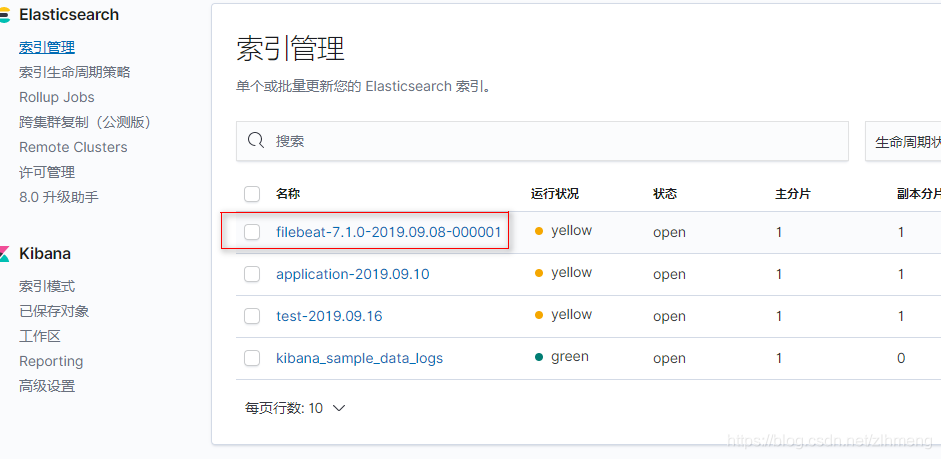
这样ELKF便搭建成功,如果需要还可以配置账号密码,ssl认证。。。后面会把这几个分别单独分一篇写,欢迎吐槽。
有问题欢迎提问,希望能够对你有所帮助。

















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









