




 本文深入探讨了条件随机场(CRF)的工作原理,特别是针对线性链CRF的参数估计过程。文章对比了CRF与最大熵马尔科夫模型(MEMM)的区别,重点介绍了CRF如何避免LabelBias问题,并详细推导了CRF中参数的求导公式,为理解CRF的训练过程提供了清晰的路径。
本文深入探讨了条件随机场(CRF)的工作原理,特别是针对线性链CRF的参数估计过程。文章对比了CRF与最大熵马尔科夫模型(MEMM)的区别,重点介绍了CRF如何避免LabelBias问题,并详细推导了CRF中参数的求导公式,为理解CRF的训练过程提供了清晰的路径。
接着上一篇的讲到的MEMM的问题来说,
MEMM产生Label Bias的根源是什么,
这是因为MEMM的状态转移概率的计算方式,为了获得转移概率,它每一步的状态转移都会进行归一化,从而导致问题的产生。
CRF认清了问题的根源,只要不要在每一步状态转移进行归一化,而在全局进行归一化 就能一下子化解了MEMM产生的Label Bias标注偏好这个大问题。
p ( s ⃗ ∣ x ⃗ ) = ∏ i = 0 n p ( s i ∣ s i − 1 , x 1 , x 2 , . . . , x n ) = ∏ i = 0 n e x p ( w ⃗ T f ( s i , s i − 1 , x ⃗ ) ) ∑ s ′ ∈ S e x p ( w ⃗ T f ( s ⃗ ′ , s i − 1 , x ⃗ ) ) p(\vec s| \vec x)=\prod_{i=0}^n p(s_i|s_{i-1},x_1,x_2,...,x_n)=\prod_{i=0}^n \dfrac{exp(\vec w^{T} f(s_i,s_{i-1},\vec x))}{ \sum_{s^{'} \in S} exp(\vec w^{T} f(\vec s^{'},s_{i-1},\vec x))} p(s∣x)=∏i=0np(si∣si−1,x1,x2,...,xn)=∏i=0n∑s′∈Sexp(wTf(s′,si−1,x))exp(wTf(si,si−1,x))
p ( s ⃗ ∣ x ⃗ ) = e x p ( w ⃗ T Φ ( s ⃗ , x ⃗ ) ) ∑ s ′ ∈ S n e x p ( w ⃗ T Φ ( s ⃗ ′ , x ⃗ ) ) p(\vec s| \vec x)=\dfrac{exp(\vec w^{T} \Phi(\vec s,\vec x))}{ \sum_{s^{'} \in S^{n}} exp(\vec w^{T} \Phi(\vec s^{'},\vec x))} p(s∣x)=∑s′∈Snexp(wTΦ(s′,x))exp(wTΦ(s,x))
第一个是MEMM 对条件概率做的表达式,
第二个是CRF 对条件概率做的表达式,
分母中的
s
′
∈
S
,
s
′
∈
S
n
s^{'} \in S , s^{'} \in S^{n}
s′∈S,s′∈Sn 一点点不同,表示的含义就千差万别了,前者只是局部的,后者是全局的。
CRF相对于MEMM做了几个改动,首先在特征函数上面做了变动:
Φ
(
s
⃗
,
x
⃗
)
→
R
d
\Phi(\vec s,\vec x) \rightarrow R^{d}
Φ(s,x)→Rd
第一个是它将输入序列
x
⃗
\vec x
x和输出标注
s
⃗
\vec s
s映射为一个d维实数向量(这个d其实就是特征函数的个数,联系前面讲到的特征函数的内容,
L
∗
N
,
L
∗
L
∗
N
L*N,L*L*N
L∗N,L∗L∗N),而MEMM的特征函数拥有的信息只是输入序列
x
⃗
\vec x
x和当前状态以及上一个状态,也就是说CRF的特征函数掌握信息量更多,从而表达能力更强。
第二个的改进是它不再针对每一次状态转移进行归一化,而是在全局进行归一化,这样完美解决Label Bias问题。
有得必有失,注意到全局进行归一化就意味着 模型的分母需要罗列所有的状态序列,对于序列长度为n的输入序列,状态序列的个数为 ∣ S ∣ n |S|^{n} ∣S∣n,对于这种指数增长问题,在实际应用中一般都是intractable的,只能付诸于近似求解,比如我们之前提过的Variational Bayes或者Gibbs Sampling等等。不过有一种特殊结构的CRF,精确快速求解的方式是存在的(前向后向算法帮助我们),因此在早期得以广泛应用。
下面我们就看CRF中是如何做参数估计,也就是所如何来求各 取值的导数,以及更新的。
这一部分 小蓝书《统计学习方法》上讲的是尤其不好,公式中的字母用的都很泛化,看了几遍都等于白看
好在https://blog.youkuaiyun.com/aws3217150/article/details/68935789这篇博客中,讲的不错,而且 该博客中的推导是和CRF++源码中的代码公式可以一一对应的,参考价值更大,而且一步步推导的过程明晰,特别是如何一步步引出了前向后向算法,也在推导中水到渠成。不过该博客中有一处 的一个字母写错了,我后面会指出。
参数估计
接下来我们介绍对于Linear Chain CRF如何进行参数参数估计的。假设我们有训练集 x 1 ⃗ , x 2 ⃗ , . . . , x N ⃗ \vec {x^1},\vec {x^2},...,\vec {x^N} x1,x2,...,xN,对应的标注集合 s 1 ⃗ , s 2 ⃗ , . . . , s N ⃗ \vec {s^1},\vec {s^2},...,\vec {s^N} s1,s2,...,sN,那么其对应的对数似然函数为:
L = ∑ i N l o g p ( s i ⃗ ∣ x i ⃗ ) = ∑ i N l o g e x p ( w T ⃗ Φ ( s i ⃗ , x i ⃗ ) ) ∑ s ⃗ ′ ∈ S n e x p ( w T ⃗ Φ ( s ′ ⃗ , x i ⃗ ) ) = ∑ i N l o g e x p ( ∑ k w k ⃗ Φ k ( s i ⃗ , x i ⃗ ) ) ∑ s ⃗ ′ ∈ S n e x p ( ∑ k w k ⃗ Φ k ( s ′ ⃗ , x i ⃗ ) ) = ∑ i N l o g ( e x p ( ∑ k w k ⃗ Φ k ( s i ⃗ , x i ⃗ ) ) ) − l o g ( ∑ s ⃗ ′ ∈ S n e x p ( ∑ k w k ⃗ Φ k ( s ′ ⃗ , x i ⃗ ) ) ) L=\sum_{i}^{N} log p(\vec {s^i}| \vec {x^i}) \\ =\sum_{i}^{N} log \dfrac{exp(\vec {w^T} \Phi(\vec {s^i},\vec {x^i}))}{ \sum_{ \vec s^{'} \in S^{n}} exp(\vec {w^T} \Phi(\vec {s^{'}},\vec {x^i})) } \\\\ =\sum_{i}^{N} log \dfrac{exp( \sum_{k} \vec {w_k} \Phi_k(\vec {s^i},\vec {x^i}))}{ \sum_{ \vec s^{'} \in S^{n}} exp(\sum_k \vec {w_k} \Phi_k(\vec {s^{'}},\vec {x^i})) } \\ =\sum_{i}^{N} log ( exp( \sum_{k} \vec {w_k} \Phi_k(\vec {s^i},\vec {x^i})))-log (\sum_{ \vec s^{'} \in S^{n}} exp(\sum_k \vec {w_k} \Phi_k(\vec {s^{'}},\vec {x^i})) ) \\ L=i∑Nlogp(si∣xi)=i∑Nlog∑s′∈Snexp(wTΦ(s′,xi))exp(wTΦ(si,xi))=i∑Nlog∑s′∈Snexp(∑kwkΦk(s′,xi))exp(∑kwkΦk(si,xi))=i∑Nlog(exp(k∑wkΦk(si,xi)))−log(s′∈Sn∑exp(k∑wkΦk(s′,xi)))
上面公式中要明确 Φ ( s ′ ⃗ , x i ⃗ ) 和 Φ k ( s ′ ⃗ , x i ⃗ ) \Phi(\vec {s^{'}},\vec {x^i}) 和 \Phi_k(\vec {s^{'}},\vec {x^i}) Φ(s′,xi)和Φk(s′,xi)的区别, Φ ( ) 是 由 多 个 ( L ∗ N , L ∗ L ∗ N ) 的 Φ k ( ) \Phi() 是由多个(L*N,L*L*N) 的\Phi_k() Φ()是由多个(L∗N,L∗L∗N)的Φk()的集合表示。 另外每一个 Φ k ( s ′ ⃗ , x i ⃗ ) \Phi_k(\vec {s^{'}},\vec {x^i}) Φk(s′,xi)是每一个特征函数对应的特征值,是每一个特征函数在 ∑ i = 1 N \sum_{i=1}^{N} ∑i=1N的每一个位置上的取值(0或1)求和后得到的。
上式对 w j w_j wj进行求导,前一项很好求,后一项 先是log x的导数为1/x ,然后再链式求导,可得:
∂
L
∂
w
j
=
∑
i
N
Φ
j
(
s
i
⃗
,
x
i
⃗
)
−
∑
i
N
∑
s
⃗
′
∈
S
n
e
x
p
(
∑
k
w
k
⃗
Φ
k
(
s
′
⃗
,
x
i
⃗
)
Φ
j
(
s
′
⃗
,
x
i
⃗
)
)
∑
s
⃗
′
∈
S
n
e
x
p
(
∑
k
w
k
⃗
Φ
k
(
s
′
⃗
,
x
i
⃗
)
)
\dfrac{\partial L}{\partial w_j} =\sum_{i}^{N} \Phi_j(\vec {s^{i}},\vec {x^i}) -\sum_{i}^{N} \dfrac{ \sum_{ \vec s^{'} \in S^{n}}exp( \sum_{k} \vec {w_k} \Phi_k(\vec {s^{'}},\vec {x^i})\Phi_j(\vec {s^{'}},\vec {x^i}))}{ \sum_{ \vec s^{'} \in S^{n}} exp(\sum_k \vec {w_k} \Phi_k(\vec {s^{'}},\vec {x^i})) }
∂wj∂L=∑iNΦj(si,xi)−∑iN∑s′∈Snexp(∑kwkΦk(s′,xi))∑s′∈Snexp(∑kwkΦk(s′,xi)Φj(s′,xi))
观察
p
(
s
∣
x
)
p(s|x)
p(s∣x)的表达式,正好可以凑出一项,
∂ L ∂ w j = ∑ i N Φ j ( s i ⃗ , x i ⃗ ) − ∑ i N ∑ s ⃗ ′ ∈ S n p ( s ⃗ ′ ∣ x i ) Φ j ( s ′ ⃗ , x i ⃗ ) \dfrac{\partial L}{\partial w_j} =\sum_{i}^{N} \Phi_j(\vec {s^{i}},\vec {x^i}) -\sum_{i}^{N} \sum_{ \vec s^{'} \in S^{n}} p(\vec s^{'}|x^{i}) \Phi_j(\vec {s^{'}},\vec {x^i}) ∂wj∂L=∑iNΦj(si,xi)−∑iN∑s′∈Snp(s′∣xi)Φj(s′,xi)
上面的式子还不可编程,问题出现在上面减号的右半部分,我们单独讨论(为了记号方便,我们省去上标i),即表示为:
∑
s
⃗
∈
S
n
p
(
s
⃗
∣
x
)
Φ
j
(
s
⃗
,
x
⃗
)
\sum_{ \vec s \in S^{n}} p(\vec s|x) \Phi_j(\vec {s},\vec {x})
∑s∈Snp(s∣x)Φj(s,x)
正如我们上面讲的,
Φ
j
(
s
⃗
,
x
⃗
)
\Phi_j(\vec {s},\vec {x})
Φj(s,x) 表示的是第j个特征函数值,它是由特征函数
ϕ
j
\phi_j
ϕj在
∑
i
=
1
N
\sum_{i=1}^{N}
∑i=1N的每一个位置上的取值(0或1)求和后得到的。所以上面的如果需要编码,需要进一步写成,下面的形式:
∑ s ⃗ ∈ S n p ( s ⃗ ∣ x ) Φ j ( s ⃗ , x ⃗ ) ∑ s ⃗ ∈ S n p ( s ⃗ ∣ x ) ∑ k ϕ j ( s k − 1 , s k , x ⃗ ) ∑ k ∑ s ⃗ ∈ S n p ( s ⃗ ∣ x ) ϕ j ( s k − 1 , s k , x ⃗ ) ∑ k ∑ a ∈ S , b ∈ S ϕ j ( s k − 1 = a , s k = b , x ⃗ ) ∑ s ⃗ ∈ S n , s k − 1 = a , s k = b p ( s ⃗ ∣ x ) \sum_{ \vec s \in S^{n}} p(\vec s|x) \Phi_j(\vec {s},\vec {x})\\ \sum_{ \vec s \in S^{n}} p(\vec s|x) \sum_k {\phi_j(s_{k-1},s_k,\vec {x})}\\ \sum _k \sum_{ \vec s \in S^{n}} p(\vec s|x) {\phi_j(s_{k-1},s_k,\vec {x})} \\ \sum _k \sum_{ a \in S,b \in S} {\phi_j(s_{k-1}=a,s_k=b,\vec {x}) \sum_{ \vec s \in S^{n}, s_{k-1}=a,s_k=b} p(\vec s|x)} s∈Sn∑p(s∣x)Φj(s,x)s∈Sn∑p(s∣x)k∑ϕj(sk−1,sk,x)k∑s∈Sn∑p(s∣x)ϕj(sk−1,sk,x)k∑a∈S,b∈S∑ϕj(sk−1=a,sk=b,x)s∈Sn,sk−1=a,sk=b∑p(s∣x)
上面的这个转换,推导其实是很重要的,也是推向前向后向的基础,
上述转换,推导中 从
s
⃗
∈
S
n
\vec s \in S^{n}
s∈Sn 到
s
k
−
1
=
a
,
s
k
=
b
,
a
∈
S
,
b
∈
S
s_{k-1}=a,s_k=b, a \in S,b \in S
sk−1=a,sk=b,a∈S,b∈S 这个退化很重要,因为 CRF的特征函数只会最多用到 了 前后两个位置,所以可以这样转换,推导。
现在问题在于对于任意a,b我们是否能快速求解 出:
∑ s ⃗ ∈ S n , s k − 1 = a , s k = b p ( s 1 , s 2 , . . . , s i − 1 , s i , . . . , s n ∣ x ) = ∑ s ⃗ ∈ S n , s k − 1 = a , s k = b p ( s 1 , s 2 , . . . , s k − 1 , s k , . . . , s n ∣ x ) = p ( s k − 1 = a , s k = b ∣ x ) \sum_{ \vec s \in S^{n}, s_{k-1}=a,s_k=b} p(s_1,s_2,...,s_{i-1},s_{i},...,s_n|x) \\ =\sum_{ \vec s \in S^{n}, s_{k-1}=a,s_k=b} p(s_1,s_2,...,s_{k-1},s_{k},...,s_n|x) \\ =p(s_{k-1}=a,s_{k}=b|x) s∈Sn,sk−1=a,sk=b∑p(s1,s2,...,si−1,si,...,sn∣x)=s∈Sn,sk−1=a,sk=b∑p(s1,s2,...,sk−1,sk,...,sn∣x)=p(sk−1=a,sk=b∣x)
这里,不知不觉就已经推导出了边缘概率
p
(
s
k
−
1
=
a
,
s
k
=
b
∣
x
)
p(s_{k-1}=a,s_{k}=b|x)
p(sk−1=a,sk=b∣x)的由来了。
所以这里就水到渠成地该讲到Forward-Backward 算法了。
Forward-Backward 算法
首先对于如下概率图模型:
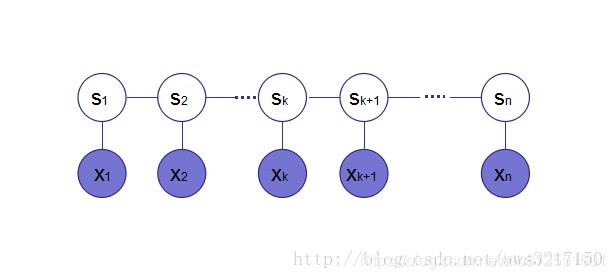
根据定义,我们可得:
p
(
s
⃗
∣
x
⃗
)
=
e
x
p
(
w
⃗
T
Φ
(
s
⃗
,
x
⃗
)
)
∑
s
′
∈
S
n
e
x
p
(
w
⃗
T
Φ
(
s
⃗
′
,
x
⃗
)
)
=
ψ
(
s
⃗
,
x
⃗
)
ψ
(
x
⃗
)
p(\vec s| \vec x)=\dfrac{exp(\vec w^{T} \Phi(\vec s,\vec x))}{ \sum_{s^{'} \in S^{n}} exp(\vec w^{T} \Phi(\vec s^{'},\vec x))}=\dfrac{\psi(\vec s,\vec x)}{\psi(\vec x)}
p(s∣x)=∑s′∈Snexp(wTΦ(s′,x))exp(wTΦ(s,x))=ψ(x)ψ(s,x)。
后面的
ψ
(
s
⃗
,
x
⃗
)
,
ψ
(
x
⃗
)
\psi(\vec s,\vec x), \psi(\vec x)
ψ(s,x),ψ(x)是我们定义的,
这里值得注意的是三个符号
Φ
(
x
⃗
)
、
ϕ
(
x
⃗
)
、
ψ
(
x
⃗
)
\Phi(\vec x)、\phi(\vec x)、\psi(\vec x)
Φ(x)、ϕ(x)、ψ(x)的含义都是不一样的,
Φ
(
x
⃗
)
\Phi(\vec x)
Φ(x)是特征函数对应的特征值的集合
ϕ
(
x
⃗
)
\phi(\vec x)
ϕ(x)是某个特征函数对应的特征值
ψ
(
x
⃗
)
\psi(\vec x)
ψ(x)是特征函数对应的特征值乘以对应的权重参数
w
w
w之后的值,再指数化。
因此上面式子的分母:
ψ
(
x
⃗
)
=
∑
s
′
∈
S
n
e
x
p
(
w
⃗
T
Φ
(
s
⃗
′
,
x
⃗
)
)
∑
s
′
∈
S
n
e
x
p
(
∑
k
w
k
∑
j
ϕ
(
s
j
−
1
,
s
j
,
x
⃗
)
)
∑
s
′
∈
S
n
e
x
p
(
∑
j
∑
k
w
k
ϕ
(
s
j
−
1
,
s
j
,
x
⃗
)
)
∑
s
′
∈
S
n
∏
j
e
x
p
(
∑
k
w
k
ϕ
(
s
j
−
1
,
s
j
,
x
⃗
)
)
\psi(\vec x)=\sum_{s^{'} \in S^{n}} exp(\vec w^{T} \Phi(\vec s^{'},\vec x)) \\ \sum_{s^{'} \in S^{n}} exp( \sum_k w_k \sum_j \phi(s_{j-1},s_j,\vec x)) \\ \sum_{s^{'} \in S^{n}} exp( \sum_j \sum_k w_k \phi(s_{j-1},s_j,\vec x)) \\ \sum_{s^{'} \in S^{n}} \prod_j exp( \sum_k w_k \phi(s_{j-1},s_j,\vec x)) \\
ψ(x)=s′∈Sn∑exp(wTΦ(s′,x))s′∈Sn∑exp(k∑wkj∑ϕ(sj−1,sj,x))s′∈Sn∑exp(j∑k∑wkϕ(sj−1,sj,x))s′∈Sn∑j∏exp(k∑wkϕ(sj−1,sj,x))
上面的最后一步推导很重要,正因为有最后一步推导中的连乘符号,才和我们熟悉 前后向算法的中的连乘符号对应起来了。
我们再抽象出一个定义来,
ψ
(
s
j
−
1
,
s
j
)
=
e
x
p
(
∑
k
w
k
ϕ
(
s
j
−
1
,
s
j
,
x
⃗
)
)
\psi(s_{j-1},s_j)=exp( \sum_k w_k \phi(s_{j-1},s_j,\vec x))
ψ(sj−1,sj)=exp(∑kwkϕ(sj−1,sj,x)).
其实 这样定义的
ψ
(
s
j
−
1
,
s
j
)
\psi(s_{j-1},s_j)
ψ(sj−1,sj) 就是链式CRF模型中常说的因子,这个概念了。这样一步步推导过来,也很自然。
s
j
−
1
,
s
j
s_{j-1},s_j
sj−1,sj是图中的前后两个位置,也是其最大团,最大clique?
因此,
ψ
(
x
⃗
)
=
∑
s
′
∈
S
n
∏
j
ψ
(
s
j
−
1
,
s
j
)
=
∑
s
1
∑
s
2
.
.
.
∑
s
n
∏
j
ψ
(
s
j
−
1
,
s
j
)
=
∑
s
1
∑
s
2
.
.
.
∑
s
n
ψ
(
s
0
=
∗
,
s
1
)
ψ
(
s
1
,
s
2
)
.
.
.
ψ
(
s
n
−
1
,
s
n
)
ψ
(
s
n
,
s
n
+
1
=
S
T
O
P
)
=
[
∑
s
n
ψ
(
s
n
,
S
T
O
P
)
[
∑
s
n
−
1
ψ
(
s
n
−
1
,
s
n
)
.
.
.
[
∑
s
1
ψ
(
s
1
,
s
2
)
[
ψ
(
∗
,
s
1
)
]
]
.
.
.
]
]
\psi(\vec x)=\sum_{s^{'} \in S^{n}} \prod_j \psi(s_{j-1},s_j) \\ =\sum_{s_1} \sum_{s_2}...\sum_{s_n} \prod_j \psi(s_{j-1},s_j)\\ =\sum_{s_1} \sum_{s_2}...\sum_{s_n} \psi(s_{0}=*,s_1)\psi(s_1,s_2)...\psi(s_{n-1},s_n)\psi(s_{n},s_{n+1}=STOP)\\ =[\sum_{s_n}\psi(s_n,STOP) [\sum_{s_{n-1}}\psi(s_{n-1},s_n) ...[\sum_{s_1}\psi(s_1,s_2)[\psi(*,s_1)]]...]]\\
ψ(x)=s′∈Sn∑j∏ψ(sj−1,sj)=s1∑s2∑...sn∑j∏ψ(sj−1,sj)=s1∑s2∑...sn∑ψ(s0=∗,s1)ψ(s1,s2)...ψ(sn−1,sn)ψ(sn,sn+1=STOP)=[sn∑ψ(sn,STOP)[sn−1∑ψ(sn−1,sn)...[s1∑ψ(s1,s2)[ψ(∗,s1)]]...]]
自然想到迭代的应用,
如果定义,
α
(
s
k
)
=
[
∑
s
k
−
1
ψ
(
s
k
−
1
,
s
k
)
[
∑
s
k
−
2
ψ
(
s
k
−
2
,
s
1
)
.
.
.
[
∑
s
1
ψ
(
s
1
,
s
2
)
[
ψ
(
∗
,
s
1
)
]
]
.
.
.
]
]
\alpha(s_k)= [\sum_{s_{k-1}}\psi(s_{k-1},s_k)[\sum_{s_{k-2}}\psi(s_{k-2},s_1) ...[\sum_{s_1}\psi(s_1,s_2)[\psi(*,s_1)]]...]]
α(sk)=[∑sk−1ψ(sk−1,sk)[∑sk−2ψ(sk−2,s1)...[∑s1ψ(s1,s2)[ψ(∗,s1)]]...]]
则 容易有下面的动态规划方程的递推式:
α
(
s
k
)
=
∑
s
k
−
1
ψ
(
s
k
−
1
,
s
k
)
α
(
s
k
−
1
)
\alpha(s_k)=\sum_{s_{k-1}} \psi(s_{k-1},s_k)\alpha(s_{k-1})
α(sk)=∑sk−1ψ(sk−1,sk)α(sk−1)
那么,这样就有:
ψ
(
x
⃗
)
=
α
(
s
n
+
1
)
=
∑
S
n
ψ
(
s
n
,
S
T
O
P
)
α
(
s
n
)
\psi(\vec x)=\alpha(s_{n+1})=\sum_{S_n}\psi(s_n,STOP)\alpha(s_n)
ψ(x)=α(sn+1)=∑Snψ(sn,STOP)α(sn)
该动态规划方程的递推式便是前后向算法的forward阶段(前向阶段),其初始值定义为:
α
(
s
1
)
=
ψ
(
∗
,
s
1
)
\alpha(s_{1})=\psi(*,s_1)
α(s1)=ψ(∗,s1)
若上述的前向过程,用重新实现,伪代码如下:
# n为序列x的长度
for s in S:
alpha(1,s) = psi(*,s) ##1表示第一轮,该轮的终点是s,起始是*(一种选择)
for(m = 2; m <= n; m++):
for s in S:
for s' in S:
alpha(m, s) += psi(s', s) * alpha(m-1, s') ##m表示第m轮,该轮的终点是s,起始是 s'(s种选择),把起始的s种选择的结果相加后才是alpha(m, s)
for s in S:
alpha(n+1, STOP) += psi(s, STOP) * alpha(n, s)##n+1表示第n+1轮,该轮的终点是stop(1种选择),起始是 s'(s种选择),把起始的s种选择的结果相加后才是alpha(n+1, STOP) ,
最终的 α ( n + 1 , S T O P ) \alpha(n+1, STOP) α(n+1,STOP) 就是 ψ ( x ⃗ ) \psi(\vec x) ψ(x)。 也就是整个式子,用于求边缘概率的分母。
类似的反向的backward阶段。
反向的推导是
ψ
(
x
⃗
)
=
∑
s
′
∈
S
n
∏
j
ψ
(
s
j
−
1
,
s
j
)
=
∑
s
1
∑
s
2
.
.
.
∑
s
n
∏
j
ψ
(
s
j
−
1
,
s
j
)
=
∑
s
1
∑
s
2
.
.
.
∑
s
n
ψ
(
s
0
=
∗
,
s
1
)
ψ
(
s
1
,
s
2
)
.
.
.
ψ
(
s
n
−
1
,
s
n
)
ψ
(
s
n
,
s
n
+
1
=
S
T
O
P
)
=
[
∑
s
1
ψ
(
∗
,
s
1
)
[
∑
s
2
ψ
(
s
1
,
s
2
)
.
.
.
[
∑
s
n
−
1
ψ
(
s
n
−
1
,
s
n
)
[
ψ
(
s
n
,
S
T
O
P
)
]
]
.
.
.
]
]
\psi(\vec x)=\sum_{s^{'} \in S^{n}} \prod_j \psi(s_{j-1},s_j) \\ =\sum_{s_1} \sum_{s_2}...\sum_{s_n} \prod_j \psi(s_{j-1},s_j)\\ =\sum_{s_1} \sum_{s_2}...\sum_{s_n} \psi(s_{0}=*,s_1)\psi(s_1,s_2)...\psi(s_{n-1},s_n)\psi(s_{n},s_{n+1}=STOP)\\ =[\sum_{s_1}\psi(*,s1) [\sum_{s_{2}}\psi(s_{1},s_2) ...[\sum_{s_{n-1}}\psi(s_{n-1},s_n)[\psi(s_n,STOP)]]...]]\\
ψ(x)=s′∈Sn∑j∏ψ(sj−1,sj)=s1∑s2∑...sn∑j∏ψ(sj−1,sj)=s1∑s2∑...sn∑ψ(s0=∗,s1)ψ(s1,s2)...ψ(sn−1,sn)ψ(sn,sn+1=STOP)=[s1∑ψ(∗,s1)[s2∑ψ(s1,s2)...[sn−1∑ψ(sn−1,sn)[ψ(sn,STOP)]]...]]
同样的,如果定义,
β
(
s
k
)
=
[
∑
s
k
+
1
.
ψ
(
s
k
,
s
k
+
1
)
.
.
.
[
∑
s
n
−
1
ψ
(
s
n
−
2
,
s
n
−
1
)
[
∑
s
n
ψ
(
s
n
−
1
,
s
n
)
[
ψ
(
s
n
,
S
T
O
P
)
]
]
]
.
.
.
]
\beta(s_{k})= [\sum_{s_{k+1}}.\psi(s_{k},s_{k+1})...[\sum_{s_{n-1}}\psi(s_{n-2},s_{n-1}) [\sum_{s_n}\psi(s_{n-1},s_n)[\psi(s_n,STOP)]]]...]
β(sk)=[∑sk+1.ψ(sk,sk+1)...[∑sn−1ψ(sn−2,sn−1)[∑snψ(sn−1,sn)[ψ(sn,STOP)]]]...]
则 容易有下面的动态规划方程的递推式:
β
(
s
k
−
1
)
=
∑
s
k
ψ
(
s
k
−
1
,
s
k
)
β
(
s
k
)
\beta(s_{k-1})=\sum_{s_{k}} \psi(s_{k-1},s_k)\beta(s_{k})
β(sk−1)=∑skψ(sk−1,sk)β(sk)
那么,这样就有:
ψ
(
x
⃗
)
=
β
(
0
)
=
∑
s
1
ψ
(
∗
,
s
1
)
β
(
s
1
)
\psi(\vec x)=\beta(0)=\sum_{s_1}\psi(*,s_1)\beta(s_1)
ψ(x)=β(0)=∑s1ψ(∗,s1)β(s1)
该动态规划方程的递推式便是前后向算法的backward阶段(后向阶段),其初始值定义为:
β
(
s
n
)
=
ψ
(
s
n
,
S
T
O
P
)
\beta(s_{n})=\psi(s_n,STOP)
β(sn)=ψ(sn,STOP)
伪代码实现如下:
#n为序列x的长度
for s in S:
beta(n, s) = psi(s, STOP)##n表示第一轮,该轮的终点是stop(一种选择),起始是s(s种选择),s表示起点
for(m = n-1; m >= 1; m--):
for s in S:
for s' in S:
beta(m, s) += psi(s, s') * beta(m+1, s')##m表示第m轮,该轮的终点是 s' (s种选择),起始是 s(s种选择),把起始的s种选择的结果相加后才是beta(m, s)
for s in S:
beta(0, *) = psi(*, s) * beta(1, s) ##0表示第0轮,该轮的终点是s (s种选择),起始是 *(1种选择),把起始的s种选择的结果相加后才是beta(0, *) ,
说实话,以前对前向后向算法,总是似懂非懂的转态,看公式能连起来后,但公式的 前后由来,总是断的,这次一次性由头到尾地看前向后向算法,算是真看懂了。
之所以要通过 求前向后向算法中的 β ( m , s ) , α ( m , s ) \beta(m, s),\alpha(m, s) β(m,s),α(m,s)。其实是为了求我们之前提到的 p ( s k − 1 = a , s k = b ∣ x ) p(s_{k-1}=a,s_{k}=b|x) p(sk−1=a,sk=b∣x)这种边缘概率,或者说条件概率。
有上述的动态规划方程的前向后向算法,我们可以很方便求解
α
,
β
α,β
α,β所对应的各个值。
下面推导如果用
α
,
β
α,β
α,β,求出我们需要的条件概率。
对于
α
,
β
α,β
α,β,现在我们考察发现:
α ( s k ) β ( s k ) ψ ( x ⃗ ) = [ ∑ s k − 1 ψ ( s k − 1 , s k ) [ ∑ s k − 2 ψ ( s k − 2 , s 1 ) . . . [ ∑ s 1 ψ ( s 1 , s 2 ) [ ψ ( ∗ , s 1 ) ] ] . . . ] ] ∗ [ ∑ s k + 1 ψ ( s k , s k + 1 ) . . . [ ∑ s n − 1 ψ ( s n − 2 , s n − 1 ) [ ∑ s n ψ ( s n − 1 , s n ) [ ψ ( s n , S T O P ) ] ] ] . . . ] = ∑ s 1 ∑ s 2 . . . ∑ s k − 1 ∑ s k + 1 . . . ∑ s n ∏ j ψ ( s j − 1 , s j ) ψ ( x ⃗ ) = p ( s k ∣ x ⃗ ) \dfrac{\alpha(s_k)\beta(s_k)}{\psi(\vec x)}\\ = [\sum_{s_{k-1}}\psi(s_{k-1},s_k)[\sum_{s_{k-2}}\psi(s_{k-2},s_1) ...[\sum_{s_1}\psi(s_1,s_2)[\psi(*,s_1)]]...]] \\*\\ [\sum_{s_{k+1}}\psi(s_{k},s_{k+1})...[\sum_{s_{n-1}}\psi(s_{n-2},s_{n-1}) [\sum_{s_n}\psi(s_{n-1},s_n)[\psi(s_n,STOP)]]]...]\\ =\dfrac{\sum_{s_1} \sum_{s_2}...\sum_{s_{k-1}}\sum_{s_{k+1}}...\sum_{s_n} \prod_j \psi(s_{j-1},s_j)}{\psi(\vec x)}\\ =p(s_k|\vec x) ψ(x)α(sk)β(sk)=[sk−1∑ψ(sk−1,sk)[sk−2∑ψ(sk−2,s1)...[s1∑ψ(s1,s2)[ψ(∗,s1)]]...]]∗[sk+1∑ψ(sk,sk+1)...[sn−1∑ψ(sn−2,sn−1)[sn∑ψ(sn−1,sn)[ψ(sn,STOP)]]]...]=ψ(x)∑s1∑s2...∑sk−1∑sk+1...∑sn∏jψ(sj−1,sj)=p(sk∣x)
也就是说:
p
(
s
k
∣
x
⃗
)
=
α
(
s
k
)
β
(
s
k
)
ψ
(
x
⃗
)
p(s_k|\vec x)=\dfrac{\alpha(s_k)\beta(s_k)}{\psi(\vec x)}
p(sk∣x)=ψ(x)α(sk)β(sk)
同理可得,
p
(
s
k
,
s
k
∣
x
⃗
)
=
α
(
s
k
−
1
)
ψ
(
s
k
−
1
,
s
k
)
β
(
s
k
)
ψ
(
x
⃗
)
p(s_k,s_k|\vec x)=\dfrac{\alpha(s_{k-1})\psi(s_{k-1},s_k)\beta(s_k)}{\psi(\vec x)}
p(sk,sk∣x)=ψ(x)α(sk−1)ψ(sk−1,sk)β(sk)
由于能高效求出
α
,
β
α,β
α,β,边缘概率
p
(
s
k
,
s
k
∣
x
⃗
)
、
p
(
s
k
∣
x
⃗
)
p(s_k,s_k|\vec x)、p(s_k|\vec x)
p(sk,sk∣x)、p(sk∣x)也可高效求出,进而我们可以精确高效地求出梯度!
只要能快速求解梯度,接下来我们就可以利用SGD或者L-BFGS对CRF进行快速参数估计。
下面我们就继续讲如何从 α , β α,β α,β,边缘概率 p ( s k , s k ∣ x ⃗ ) 、 p ( s k ∣ x ⃗ ) p(s_k,s_k|\vec x)、p(s_k|\vec x) p(sk,sk∣x)、p(sk∣x)来得出CRF的求导式子,也即是源码中真正用于更新参数的式子。
这里我们就要又回到上一篇提到的损失函数(似然函数)式子了,
原始论文的阐述形式是CRF是一种概率图模型,而一幅图可以由它的边和节点来表达,也就是
G=(V,E)
其中,V是节点集合,E是边集合,对于链式CRF,模型对于输入序列和输出序列可以建立如下的概率模型:
p
(
y
⃗
∣
x
⃗
)
=
e
x
p
(
∑
e
∈
E
∑
k
w
k
ϕ
k
(
e
=
(
y
i
−
1
,
y
i
)
,
x
⃗
)
+
∑
v
∈
V
∑
t
w
t
ϕ
t
(
v
=
y
i
,
x
⃗
)
)
Z
p(\vec{y}|\vec{x})=\dfrac{exp( \sum_{e \in E}\sum_{k} w_k \phi_k (e=(y_{i-1},y_{i}), \vec{x}) +\sum_{v \in V}\sum_{t} w_t \phi_t (v=y_{i}, \vec{x})) }{Z}
p(y∣x)=Zexp(∑e∈E∑kwkϕk(e=(yi−1,yi),x)+∑v∈V∑twtϕt(v=yi,x))
这种形式和我们常见的另一种形式其实又很大区别,另一种形式是:
p ( y ⃗ ∣ x ⃗ ) = e x p ( ∑ i ∑ k w k ϕ k ( y i − 1 , y i , x ⃗ ) ) ∑ y ′ ∈ Y e x p ( ∑ i ∑ k w k ϕ k ( y i − 1 ′ , y i ′ , x ⃗ ) ) p(\vec{y}|\vec{x})=\dfrac{exp( \sum_{i}\sum_{k} w_k \phi_k (y_{i-1},y_{i}, \vec{x}) ) }{\sum_{y^{'} \in Y} exp( \sum_{i}\sum_{k} w_k \phi_k (y_{i-1}^{'},y_{i}^{'}, \vec{x}) ) } p(y∣x)=∑y′∈Yexp(∑i∑kwkϕk(yi−1′,yi′,x))exp(∑i∑kwkϕk(yi−1,yi,x))
下面的这种形式是没有将边和节点区分开来,看上去只是写了边的特征函数,因为从某种程度上看,边包含的信息其实已经涵盖了节点所拥有的所有信息,将这两者统一起来只是有利于我们数学公式表达的方便性,另一方面,将边和节点进行单独讨论,从理论上可能有一点冗余, 但从实际效果来讲以及实际源码编写中看,都是边和节点区分开来写源码的,节点信息可以充当一种backoff,起到一定的平滑效果(Smoothing)。
下面我们就看 CRF的似然函数或者损失函数的式子:
L = − ∑ i N l o g p ( y ⃗ i ∣ x ⃗ i ) L=- \sum_{i}^{N} log p(\vec y^{i} |\vec x^{i}) L=−∑iNlogp(yi∣xi)
带入 p ( y ⃗ ∣ x ⃗ ) = e x p ( ∑ e ∈ E ∑ k w k ϕ k ( e = ( y i − 1 , y i ) , x ⃗ ) + ∑ v ∈ V ∑ t w t ϕ t ( v = y i , x ⃗ ) ) Z p(\vec{y}|\vec{x})=\dfrac{exp( \sum_{e \in E}\sum_{k} w_k \phi_k (e=(y_{i-1},y_{i}), \vec{x}) +\sum_{v \in V}\sum_{t} w_t \phi_t (v=y_{i}, \vec{x})) }{Z} p(y∣x)=Zexp(∑e∈E∑kwkϕk(e=(yi−1,yi),x)+∑v∈V∑twtϕt(v=yi,x))这个式子,我们对 w j w_j wj进行求导,要分为两种,即分别是对图节点参数求导和对边参数求导。
∂ L ∂ w j = ∑ i N ( ∑ v ∈ V p ( v = y ∣ x ⃗ ) ϕ j ( v , x ⃗ ) − ∑ v ∈ V ϕ j ( v , x ⃗ ) ) = ∑ i N ( E v ∼ p ( v ∣ x ⃗ ) ϕ j ( v , x ⃗ ) − ∑ v ∈ V ϕ j ( v , x ⃗ ) ) = ∑ i N ( ∑ v ∈ V α ( v ) β ( v ) Z − ∑ v ∈ V ϕ j ( v , x ⃗ ) ) \dfrac{\partial L}{\partial w_j}=\sum_{i}^{N} (\sum_{v \in V} p(v=y|\vec x) \phi_j (v, \vec{x}) - \sum_{v \in V} \phi_j (v, \vec{x})) \\ =\sum_{i}^{N} (E_{v \sim p(v|\vec x)}\phi_j (v, \vec{x}) - \sum_{v \in V} \phi_j (v, \vec{x})) \\ =\sum_{i}^{N} (\sum_{v \in V} \dfrac{\alpha(v)\beta(v)}{Z} - \sum_{v \in V} \phi_j (v, \vec{x})) ∂wj∂L=i∑N(v∈V∑p(v=y∣x)ϕj(v,x)−v∈V∑ϕj(v,x))=i∑N(Ev∼p(v∣x)ϕj(v,x)−v∈V∑ϕj(v,x))=i∑N(v∈V∑Zα(v)β(v)−v∈V∑ϕj(v,x))
上面的式子第二步写出了一种期望的形式,这也就是为什么有些crf的博客里在参数求导时会提到期望的概念。
从第二步到第三步的过程中,我开始看了好几遍以为是 公式写错了,总是觉得少写了一项。因为
α
(
v
)
β
(
v
)
Z
\dfrac{\alpha(v)\beta(v)}{Z}
Zα(v)β(v)明明应该对应于
p
(
v
=
y
∣
x
⃗
)
p(v=y|\vec x)
p(v=y∣x), 怎么又对应于
p
(
v
=
y
∣
x
⃗
)
ϕ
j
(
v
,
x
⃗
)
p(v=y|\vec x) \phi_j (v, \vec{x})
p(v=y∣x)ϕj(v,x) 呢?
后面忽然灵光一现,因为只看公式,没想到公式背后的含义, ϕ j ( v , x ⃗ ) \phi_j (v, \vec{x}) ϕj(v,x) 的物理含义是在i这个位置上,第j个特征函数 取到的特征函数值,由于特征函数的定义只取为0或1。 所以在这种特殊取值的情况下,推导的时候,会有 ∑ v ∈ V α ( v ) β ( v ) Z = ∑ v ∈ V α ( v ) β ( v ) Z ϕ j ( v , x ⃗ ) \sum_{v \in V} \dfrac{\alpha(v)\beta(v)}{Z}=\sum_{v \in V} \dfrac{\alpha(v)\beta(v)}{Z}\phi_j (v, \vec{x}) ∑v∈VZα(v)β(v)=∑v∈VZα(v)β(v)ϕj(v,x)成立。
同理对边参数求导如下:
∂ L ∂ w j = ∑ i N ( ∑ e ∈ E p ( e = ( y i − 1 , y i ) ∣ x ⃗ ) ϕ j ( e , x ⃗ ) − ∑ e ∈ E ϕ j ( e , x ⃗ ) ) = ∑ i N ( E e ∼ p ( e ∣ x ⃗ ) ϕ j ( e , x ⃗ ) − ∑ e ∈ E ϕ j ( e , x ⃗ ) ) = ∑ i N ( ∑ e ∈ E α ( y i − 1 ) ψ ( y i − 1 , y i ) β ( y i ) Z − ∑ e ∈ E ϕ j ( e , x ⃗ ) ) \dfrac{\partial L}{\partial w_j}=\sum_{i}^{N} (\sum_{e \in E} p(e=(y_{i-1},y_i)|\vec x) \phi_j (e, \vec{x}) - \sum_{e \in E} \phi_j (e, \vec{x})) \\ =\sum_{i}^{N} (E_{e \sim p(e|\vec x)}\phi_j (e, \vec{x}) - \sum_{e \in E} \phi_j (e, \vec{x})) \\ =\sum_{i}^{N} (\sum_{e \in E} \dfrac{\alpha(y_{i-1})\psi(y_{i-1},y_{i})\beta(y_i)}{Z} - \sum_{e \in E} \phi_j (e, \vec{x})) ∂wj∂L=i∑N(e∈E∑p(e=(yi−1,yi)∣x)ϕj(e,x)−e∈E∑ϕj(e,x))=i∑N(Ee∼p(e∣x)ϕj(e,x)−e∈E∑ϕj(e,x))=i∑N(e∈E∑Zα(yi−1)ψ(yi−1,yi)β(yi)−e∈E∑ϕj(e,x))
这里的
ψ
(
y
i
−
1
,
y
i
)
\psi(y_{i-1},y_{i})
ψ(yi−1,yi),就是我们在前向后向公式推导中 引入的因子,即
ψ
(
y
j
−
1
,
y
j
)
=
e
x
p
(
∑
k
w
k
ϕ
(
y
j
−
1
,
y
j
,
x
⃗
)
)
\psi(y_{j-1},y_j)=exp( \sum_k w_k \phi(y_{j-1},y_j,\vec x))
ψ(yj−1,yj)=exp(∑kwkϕ(yj−1,yj,x))
ϕ \phi ϕ是特征函数,节点特征函数一般由Unigram模板产生,边特征函数由Bigram模板自动产生, α , β α,β α,β的计算用上面我们介绍的forward-backward算法既可高效求解。
下篇,准备参照
https://blog.youkuaiyun.com/aws3217150/article/details/69212445
中提到的源码片段,对应介绍上面提到的对节点参数和边参数求导的公式。

















 2322
2322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









