




 本文深入讲解MySQL中的分组查询、多表查询等高级特性,并介绍了事务处理、临时表使用及SQL注入防范等实用技巧。
本文深入讲解MySQL中的分组查询、多表查询等高级特性,并介绍了事务处理、临时表使用及SQL注入防范等实用技巧。
接上篇:mysql基础知识总结(上)
六、分组查询
Group By 关键字可以将查询结果按照某个字段或多个字段进行分组,字段中值相等的为一组。
SELECT column_name, function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;示例:
select sex,GROUP_CONCAT(name) from employee group by sex;
select sex,COUNT(sex) from employee group by sex having COUNT(sex)>=3;
select sex, GROUP_CONCAT(name) from employee group by sex WITH ROLLUP; #汇总
注意:select子句顺序(select--from--where--group by--having--order by--limit--)
七、多表查询
1.子查询
select * from products where unitprice > ANY(select unitprice from detail where discount >0.25);
select * from goods where goods_id in (select goods from detail);
select *,(select count(*) from detail where detail.goods=goods_id) as id_count from goods;
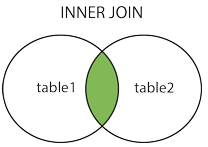
2.内连接查询(inner join 或 join或,)
获取两个表中字段匹配关系的记录。
select * from 表1 inner join 表2 on 表1.字段号=表2.字段号;
或 select * from 表1, 表2 where 表1.字段号=表2.字段号;
select p1.goods_name,p1.goods_maker from goods as p1,good as p2 where p1.goods_id=p2.goods_id and p2.goods_name='饼干4';
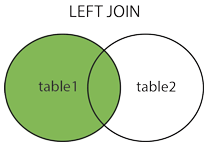
3.左连接(left join)
返回两表中相等的,并且返回左表中不符合的项为null。
select * from 表1 left join 表2 on 表1.字段号=表2.字段号;
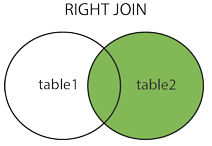
4.右连接(right join)
返回两表中相等的,并且返回右表中不符合的项为null。
select * from 表1 right join 表2 on 表1.字段号=表2.字段号;
5.联合查询
可以自动去重复(不想去重复,加union all),它将两次或多次查询的结果合并起来,要求查询的各列类型一致。
select 字段1,字段2 from table1 where 条件 union select 字段3,字段4 from table2 where 条件;
6.交叉连接(cross join 或者 join 或,)
八、其他
(1)null值处理
- IS NULL:当列的值是NULL,此运算符返回true。
- IS NOT NULL:当列的值不为NULL, 运算符返回true。
- <=>:比较操作符,当比较的两个值为NULL时返回true。
(2)正则表达式
select sname from student where sname regexp '^zh';
下面的正则表达式可应用于regexp操作符中。
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
详细正则表达式内容可参考:正则表达式
(3)事务
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
- 在MySQL中只有使用了Innodb数据库引擎的数据库或表才支持事务;
- 事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要么全部不执行;
- 事务用来管理insert,update,delete语句;
一般来说,事务必须满足4个条件(ACID): Atomicity(原子性)、Consistency(稳定性)、Isolation(隔离性)、Durability(可靠性)
- 事务的原子性:一组事务,要么成功;要么撤回。
- 稳定性 : 有非法数据(外键约束之类),事务撤回。
- 隔离性:事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。
- 可靠性:软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得。
(4)临时表
MySQL 临时表在我们需要保存一些临时数据时是非常有用的。临时表只在当前连接可见,当关闭连接时,Mysql会自动删除表并释放所有空间。
create temporary table teacher(...);
(5)SQL注入
SQL注入,就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
(6)导出和导入数据
- 导出数据:select ... into outfile 'filename';
- 导入数据:load data local infile 'filename' into table table_name;
(7)相关函数
- DATEDIFF(date1,date2):计算两个日期差;
- CHARSET(str):返回字串字符集;
- CONCAT(string, [...]):连接字符串;
- INSTR(string, substring):返回substring在string中出现的位置;
- UCASE(str):转换成大写;
- LCASE(str):转换成小写;
- LEFT(str, length):从str中的左边起取length个字符;
- LENGTH(str):string长度;
- REPLACE(str, search_str, replace_str):在str中用replace替换search;
- SRRCMP(string1, string2):逐字符比较两字串大小;
- SUBSTRING(str, position[length]):从str的position开始取length个字符;
- LTRIM(str)/RTRIM(str):去除左或右端空格;
- FORMAT(number, decimal_places):保留小数位数;
- COUNT(column_name):返回某一列,行的总数;
select sid,sname,sid*smark as imark from student;
select concat(sname, '(', sid, ')') as sname from student;
select sname, upper(sname) from student;
select sid,sname from student where mod(sid,2)=0;
select avg(sid) as avg,min(sid) as min from student;
select count(sage) from student;

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









