









本文转载自:https://zhuanlan.zhihu.com/p/54082978
这里梳理了一下当前几个高效卷积神经网络,包括mobilenet[1]、mobilenetv2[2]、shufflenet[3]、shufflenetv2[4]、xception[5]、light xception[6]。
梳理的目的有二:
1、神经网络结构的细节在文章中一般会散落在各处,通过梳理,我们将网络结构的细节合为一处,形成一个网络结构说明书,按照这个说明书就能快速而又无误地实现出对应的神经网络;
2、通过比较各个高效卷积神经网络,找到其中的共性与区别。
每个网络结构说明书的重点是“基本单元”和“网络结构全貌”,网络结构中的重要细节则直接从论文中摘抄。
Mobilenet
- 基本单元

- 网络全貌
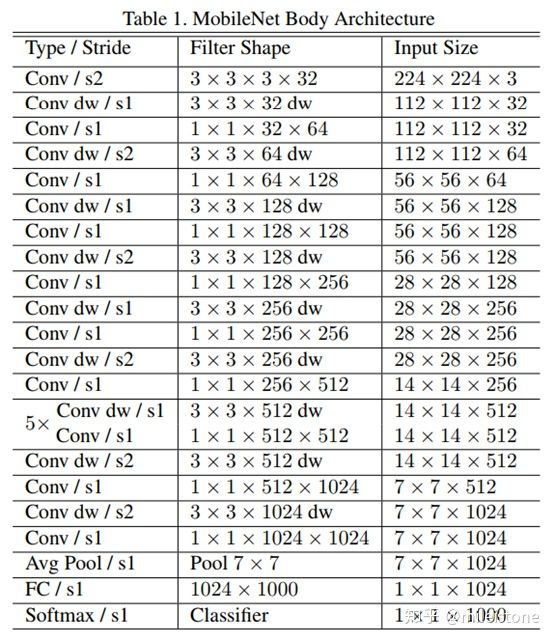
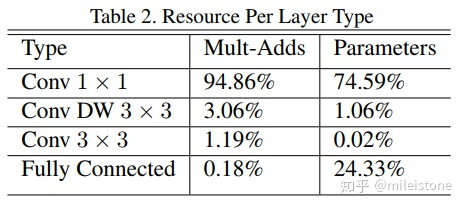
- 资源占比
- Width Multiplier
In order to construct these smaller and less computationally expensive models we introduce a very simple parameter α called width multiplier. The role of the width multiplier α is to thin a network uniformly at each layer. For a given layer and width multiplier α, the number of input channels M becomes αM and the number of output channels N becomes αN.
Mobilenetv2
- 基本单元
We use batch normalization after every layer.

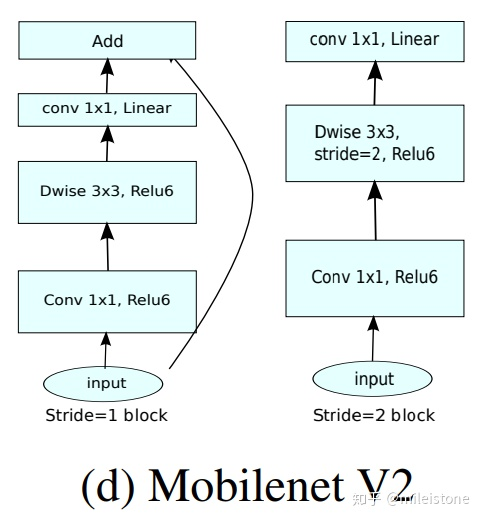
- 网络全貌
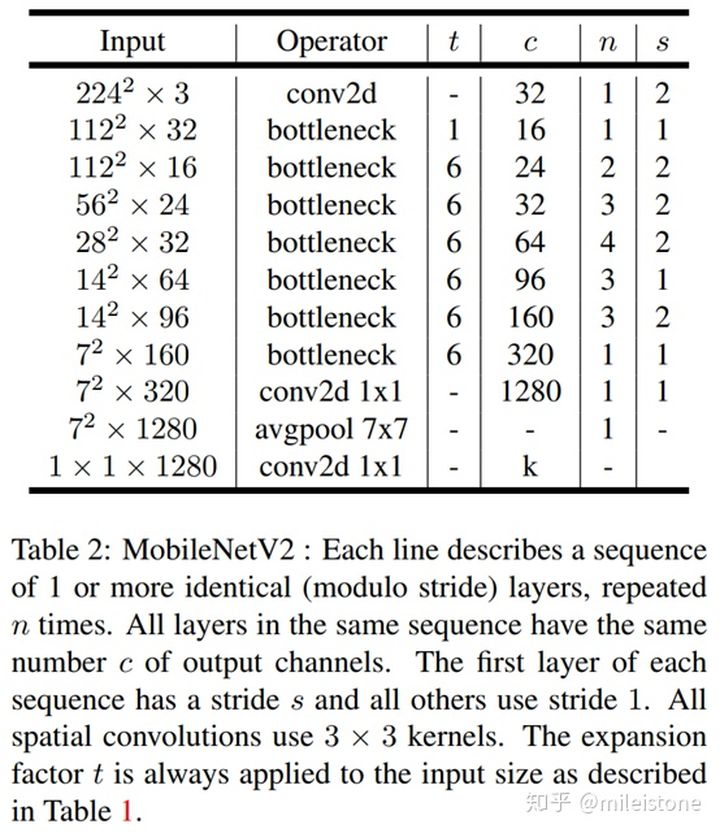
- Width Multiplier
One minor implementation difference, with [1] is that for multipliers less than one, we apply width multiplier to all layers except the very last convolutional layer. This improves performance for smaller models.
Shufflenet
- 基本单元
we set the number of bottleneck channels to 1/4 of the output channels for each ShuffleNet unit.
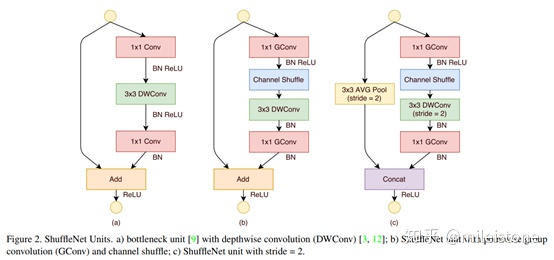
- 网络全貌
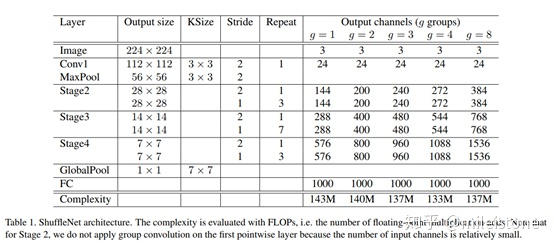
Note that for Stage 2, we do not apply group convolution on the first pointwise layer because the number of input channels is relatively small.
- Width multiplier
To customize the network to a desired complexity, we can simply apply a scale factor s on the number of channels. For example, we denote the networks in Table 1 as ”ShuffleNet 1*”, then ”ShuffleNet s*” means scaling the number of filters in ShuffleNet 1*by s times thus overall complexity will be roughly s2 times of ShuffleNet 1*.
Shufflenetv2
- 基本单元
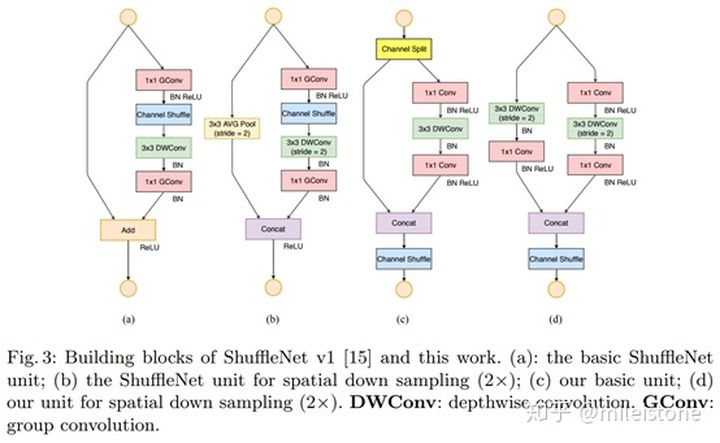
It is clear that when c1 : c2 is approaching 1 : 1, the MAC becomes smaller and the network evaluation speed is faster.
即channel split的时候,左右两个branch的channel平均分效果最好。
At the beginning of each unit, the input of c feature channels are split into two branches with c-c0 and c0 channels, respectively. Following G3, one branch remains as identity. The other branch consists of three convolutions with the same input and output channels to satisfy G1. The two 1 × 1 convolutions are no longer group-wise, unlike [3]. This is partially to follow G2, and partially because the split operation already produces two groups.
- 网络全貌

- Width multiplier
the number of channels in each block is scaled to generate networks of different complexities, marked as , 0.5*, 1* , etc.
Xception
- 基本单元
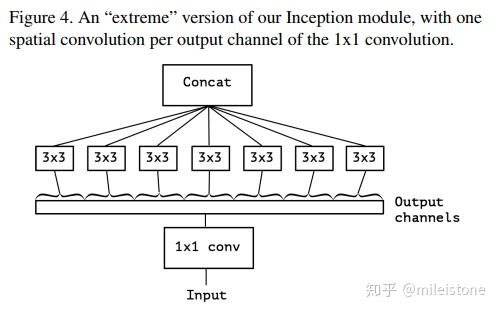
Two minor differences between and “extreme” version of an Inception module and a depthwise separable convolution would be:
1. The order of the operations: depthwise separable convolutions as usually implemented (e.g. in TensorFlow) perform first channel-wise spatial convolution and then perform 1x1 convolution, whereas Inception performs the 1x1 convolution first.
2. The presence or absence of a non-linearity after the first operation. In Inception, both operations are followed by a ReLU non-linearity, however depthwise separable convolutions are usually implemented without non-linearities.
We argue that the first difference is unimportant, in particular because these operations are meant to be used in a stacked setting.
the absence of any non-linearity leads to both faster convergence and better final performance.
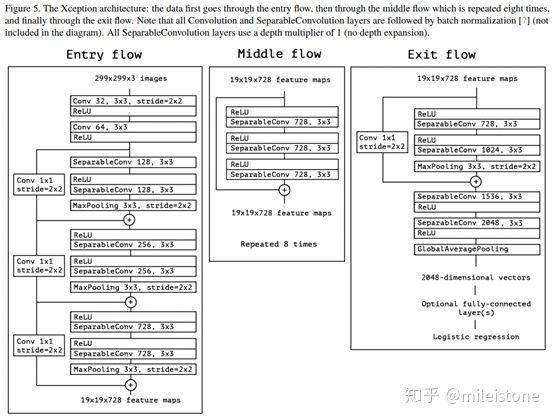
- 网络全貌
Note that all Convolution and SeparableConvolution layers are followed by batch normalization (not included in the diagram). All SeparableConvolution layers use a depth multiplier of 1 (no depth expansion).
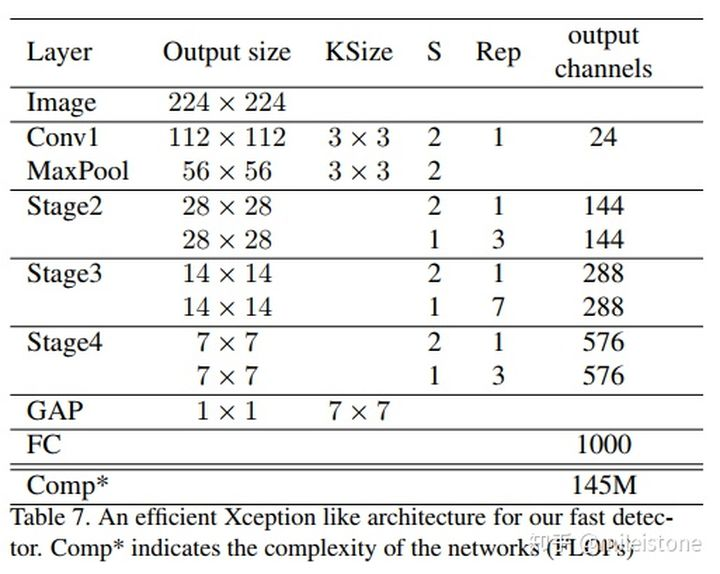
Light Xception
An efficient Xception like architecture for our fast detector An efficient Xception like architecture for our fast detector.
- 网络全貌
we do not use the pre-activation design
综合来看
1、所有模型,无论是普通conv、point wise conv(无论是否执行group操作)还是depth wise conv后面都会接上一个bn层;
2、是否pre activation得根据具体模型和具体任务来决定;
3、mobilenet、mobilenetv2的depth wise conv之后接了非线性layer,而shufflenet、shufflenetv2、xception的depth wise conv之后没接非线性layer。到底是接好还是不接好,有点类似是否pre activation,得根据具体任务、具体模型来决定;
4、separable conv模块中point wise conv和depth wise conv的顺序对模型影响不大;
5、第一层和最后一层会有一些特殊处理,需要注意,如mobilenetv2在用width multiplier进行模型缩放时,对最后一层不会缩放;shufflenet第2个stage的第一层point wise conv不会执行group操作。
一些感想
高效网络结构有点像机器学习算法,没有最好的机器学习算法,只有最合适的,高效网络结构亦然,每种高效网络结构也有自己的assumption,没有一种网络结构可以”放之四海而皆准“,比如并不是任何情况下使用separable conv替换普通conv就一定能提高网络前向速度。
硬件实现、软件实现以及网络结构自身特点,都可能改变网络前向速度的瓶颈,网络前向速度的瓶颈变了,设计思路就得跟着变,这需要我们对各种高效网络设计的motivation和assumption了然于胸。

















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









