






 本文介绍了Java中的ForkJoinPool和工作窃取算法,阐述了为何需要ForkJoin,包括它如何节省资源和均衡利用CPU。通过代码示例和工作原理解析,详细讲解了ForkJoinPool的主要类如ForkJoinTask、RecursiveAction和RecursiveTask,以及关键方法如fork()和join()。最后,解释了ForkJoinPool的整体工作流程和工作队列特性。
本文介绍了Java中的ForkJoinPool和工作窃取算法,阐述了为何需要ForkJoin,包括它如何节省资源和均衡利用CPU。通过代码示例和工作原理解析,详细讲解了ForkJoinPool的主要类如ForkJoinTask、RecursiveAction和RecursiveTask,以及关键方法如fork()和join()。最后,解释了ForkJoinPool的整体工作流程和工作队列特性。
forkjoin和forkjoinpool讲解
背景
对于java开发从业人员来说,并发编程是绕不开的话题,juc并发包下提供了一系列多线程场景解决方案。
随着jdk1.8的普及,多线程处理问题,除了使用使用线程池(ExecutorService),很多人选择了parallelStream() 并行流,底层使用forkjoin实现并行处理。
那么并行和并发又有什么区别?究竟改如何选择?滥用时又会有什么影响?
这些问题我分以下几篇文章进行详细说明:
1. 多线程并发和并行的区别
2. parallelStream()并行滥用的后果
3. forkjoin和forkjoinpool讲解 (本文)
4. 线程池正确用法
为什么需要forkjoin
两个好处ThreadPool无法替代
- 线程私有队列,更节省资源
- 工作窃取机制,均衡利用cpu
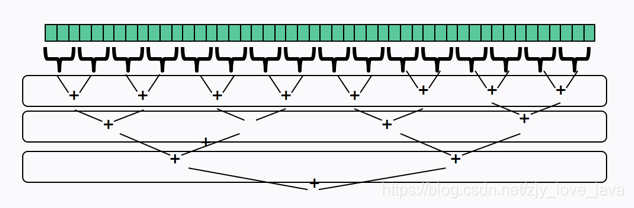
用下面这个例子说明以上两点,如果将一段计算拆分成如下16段进行多线程计算。
- 如果用多线程递归拆分,需要16个线程,而且当cpu核数只有4核时,会存在cpu切换的额外消耗;用forkjoin默认使用cpu相同核数的线程,将任务放入队列进行并行计算。
- 如果使用多线程计算,如果某个线程分到的任务执行比较慢,其他线程先执行完,就会有额外的cpu浪费。如果用forkjoin,先执行完的线程,会到慢的线程队列中窃取任务,均匀利用cpu。
先看代码
看原理之前,先简单的看forkjoin例子
package com.chainup.forkjoin;
import java.util.concurrent.*;
/**
* @Author zhongjingyun
* 通过forkjoin完成1~1000累加
* @Date 2020/9/8 下午11:18
**/
public class ForkJoinDemo {
public static void main(String[] args) throws Exception{
//使用ForkJoinPool来执行任务
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
//生成一个计算任务,负责计算1+2+3+4
CountTaskTmp task = new CountTaskTmp(1, 1000);
long r = forkJoinPool.invoke(task);
System.out.println(r);
}
}
class CountTaskTmp extends RecursiveTask<Long> {
private static final long THRESHOLD = 10;
private long start;
private long end;
public CountTaskTmp(long start, long end) {
this.start = start;
this.end = end;
}
//实现compute 方法来实现任务切分和计算
@Override
protected Long compute() {
System.out.println("当前线程开始:" + Thread.currentThread().getName() + " start : " + start + " end : " + end);
long sum = 0;
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (long i = start; i <= end; i++){
sum += i;
}
} else {
//如果任务大于阀值,就分裂成两个子任务计算
long mid = (start + end) / 2;
CountTaskTmp leftTask = new CountTaskTmp(start, mid);
CountTaskTmp rightTask = new CountTaskTmp(mid + 1, end);
//执行子任务
leftTask.fork();
rightTask.fork();
//等待子任务执行完,并得到结果
long leftResult = leftTask.join();
long rightResult = rightTask.join();
sum = leftResult + rightResult;
}
System.out.println("当前线程结束:" + Thread.currentThread().getName() + " start : " + start + " end : " + end);
return sum;
}
}
结合多线程理解forkjoin代码
forkjoin主要的类
- ForkJoinPool:实现ForkJoin的线程池,类似于ThreadPool
- ForkJoinWorkerThread 实现ForkJoin的线程,继承了Thread
- ForkJoinTask 一个描述ForkJoin的抽象类,类似Runnable/Callable
- RecursiveAction 无返回结果的ForkJoinTask实现,类似Runnable
- RecursiveTask 有返回结果的ForkJoinTask实现,类似Callable
- CountedCompleter 在任务完成执行后会触发执行一个自定义的钩子函数
forkjoin常用方法
- fork():类似于Thread.start(),但是它并不立即执行任务,而是将任务放入工作队列中
- join():跟Thread.join()不同,ForkJoinTask的join()方法并不简单的阻塞线程
利用工作线程运行其他任务
当一个工作线程中调用join(),它将处理其他任务,直到注意到目标子任务已经完成
forkjoin设计原理
forkjoin整体工作流程
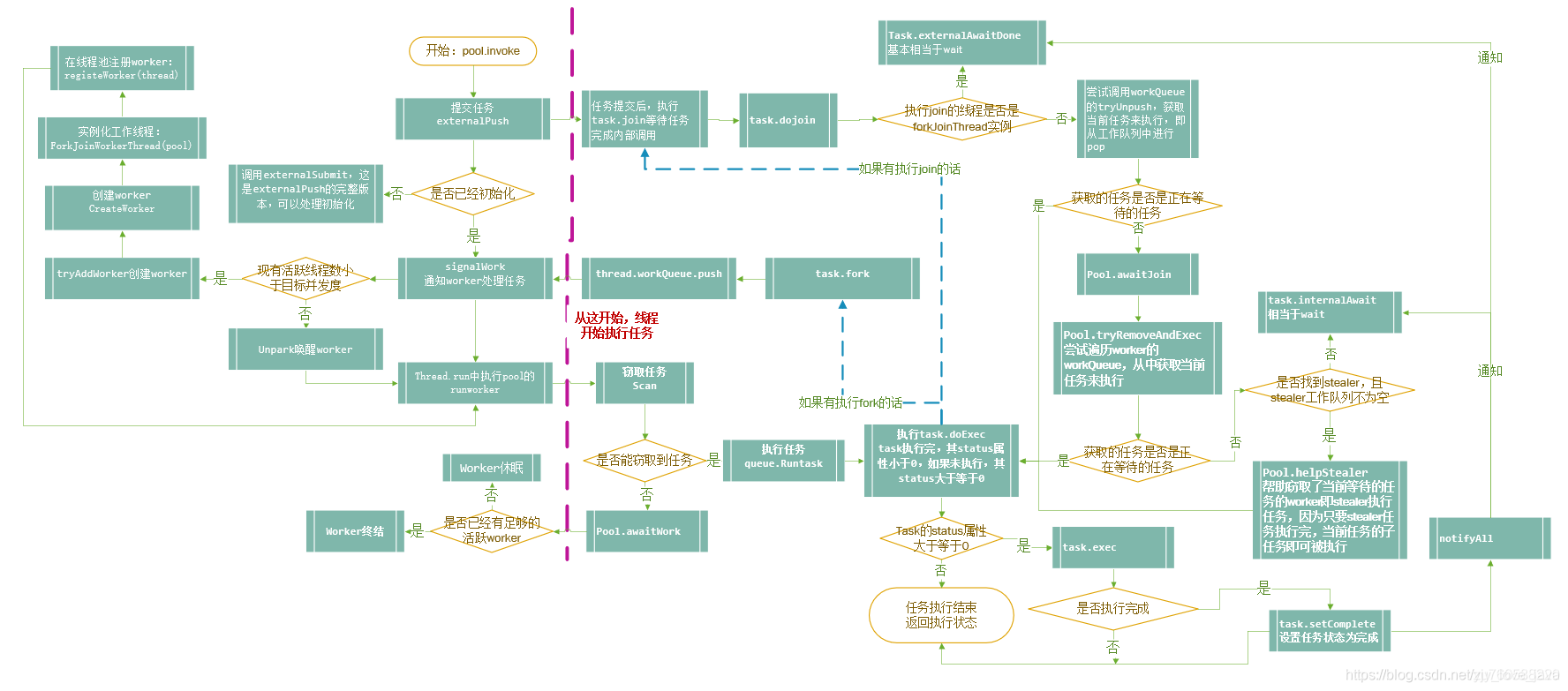
工作队列和线程池
-
ForkJoinPool工作线程池
和线程池一样继承了AbstractExecutorService,专门用来执行ForkJoinTask。提供公共的静态线程池:ForkJoinPool.commonPool();
也可以单独创建指定线程池大小:new ForkJoinPool();默认大小为cpu核数:Runtime.getRuntime().availableProcessors() -
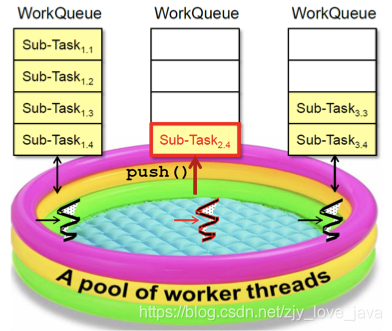
WorkQueue
所有的工作线程均有一个自己的工作队列WorkQueue,具备以下特征- 双端队列(Deque)
- 从队头取任务
- 线程私有,不共享
-
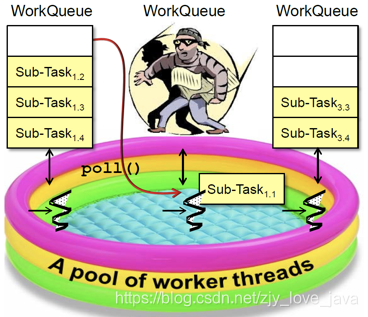
工作窃取机制
为了最大化CPU利用率,空闲的线程将从其他线程的队列中“窃取”任务来执行

















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









