




 本文详细解析了SQL中where子句与having子句的本质区别,包括它们的操作对象、执行顺序及应用场景。通过实例展示了where用于分组前过滤,having则在分组后筛选结果集,强调了聚合函数在两者中的不同作用。
本文详细解析了SQL中where子句与having子句的本质区别,包括它们的操作对象、执行顺序及应用场景。通过实例展示了where用于分组前过滤,having则在分组后筛选结果集,强调了聚合函数在两者中的不同作用。
本质区别:where 对磁盘上的表进行操作,而having 是对结果集进行操作;
==> where 是在分组前过滤数据,而having 是在分组之后过滤数据;
执行顺序:
where 、聚合函数和 having 在from 后面的执行顺序(从先到后):where > 聚合函数(sum,avg,count,max,min)> having
举例说明:
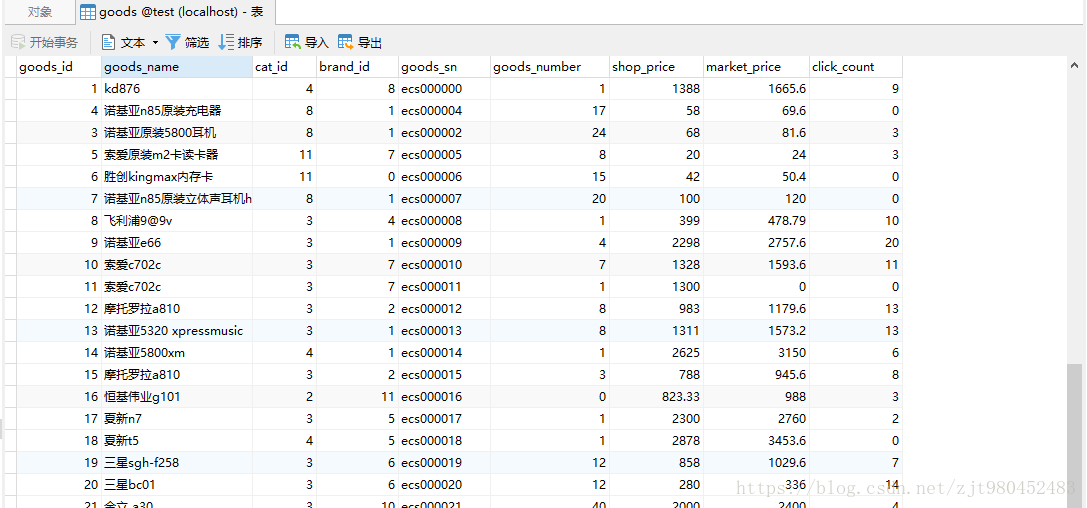
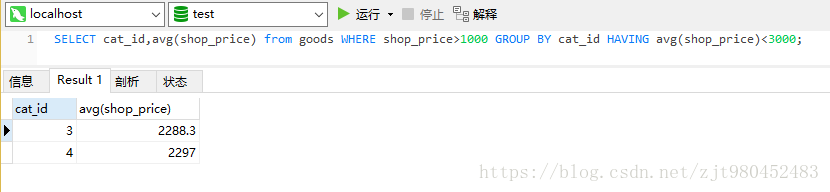
目标:筛选出那些销售价格(shop_price)大于1000商品,并且按照商品分类(cat_id)进行分类,只显示出那些商品的平均销售价格低于3000以及所在的商品分类(cat_id):
SELECT cat_id,avg(shop_price) from goods WHERE shop_price>1000 GROUP BY cat_id HAVING avg(shop_price)<2000;操作顺序:先筛选shop_price>1000;然后按照cat_id分类,接着计算平均值avg(shop_price),最后在结果集中筛选出那些均值小于2000的行
查询结果:
注意事项:where后面不能跟聚合函数,因为where的执行顺序大于聚合函数;
原因:
1.where后面接的子句是在对表进行查询前,将不符合where条件的行去掉,即在分组前过滤数据,所以where条件中不能包含聚合函数;
2.having后面接的子句是筛选满足条件的组,即在分组之后过滤数据,所以having条件中经常包含聚合函数,也可以使用having条件显示特定的组;
具体场景讲解:
1.where和having都可以使用的场景:
SELECT goods_name,shop_price FROM goods WHERE shop_price>1000;SELECT goods_name,shop_price FROM goods HAVING shop_price>1000;上面的having可以用的前提是我已经筛选出了shop_price字段,在这种情况下和where的效果是等效的,但是如果我没有select goods_price 就会报错!!因为having是从前筛选的字段再筛选,而where是从数据表中原有的字段直接进行的筛选的。
2. 只可以用where,不可以用having的情况
SELECT goods_name,goods_id FROM goods WHERE shop_price;//报错!!!因为前面并没有筛选出goods_price 字段
SELECT goods_name,goods_id FROM goods HAVING shop_price;3. 只可以用having,不可以用where情况
查出每种商品类型(cat_id)对应的平均销售价格(shop_price),只反馈那些平均销售价格小于2000的商品分类;
//报错!!因为goods 这张数据表里面没有AVG(shop_price)这个字段
SELECT cat_id ,AVG(shop_price) FROM goods GROUP BY cat_id WHERE AVG(shop_price)<2000;//依然报错,即使取了新的列名ag!!因为goods 这张数据表里面没有AVG(shop_price)这个字段
SELECT cat_id ,AVG(shop_price) AS ag FROM goods GROUP BY cat_id WHERE ag<2000;SELECT cat_id ,AVG(shop_price) FROM goods GROUP BY cat_id HAVING AVG(shop_price)<2000;
where -having-group练习题:
有如下表及数据
+------+---------+-------+
| name | subject | score |
+------+---------+-------+
| 张三 | 数学 | 90 |
| 张三 | 语文 | 50 |
| 张三 | 地理 | 40 |
| 李四 | 语文 | 55 |
| 李四 | 政治 | 45 |
| 王五 | 政治 | 30 |
+------+---------+-------+
要求:查询出2门及2门以上不及格者的平均成绩
SELECT name,sum(score<60) as gk,AVG(score) FROM result GROUP BY name HAVING gk>=2;

















 2238
2238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









